什么是网站的伸缩性?网站的伸缩性的应用场景?具体的伸缩性架构应该怎样划分和架构?
1. 伸缩性
在《大型网站技术架构》一书中给了关于网站伸缩性的解释:
网站的伸缩性是指不需要改变网站的软硬件设计,仅仅通过改变部署的服务器数量就可以线性的扩大或者缩小网站的服务处理能力。
网址的大访问量好比洪水,为了应对洪水带来的危害,你可以通过增加河道数量,来缓解洪水压力。同理,为了应对网站的大并发量,可以通过适当的增加服务器数量,来提高系统的服务处理能力。
2. 伸缩性可以从两个维度上拆分
2.1 不同功能进行物理分离实现伸缩
我们可以从“横向”和“纵向”上对系统伸缩性进行分离。我们常见的“卖家、买家、网站前台”等属于“横向分离”,而以“数据库、基础技术服务、可复用业务服务、网站具体产品”等属于纵向分离,具体场景还需要看业务需求。
2.2 单一功能通过集群规模实现伸缩
我们可以从“应用服务器”和“数据服务器”上对系统进行伸缩性拆分。应用服务器集群主要靠“负载均衡”来实现,数据服务器集群分为“缓存数据服务器集群”和“存储数据服务器集群”。
3. 应用服务器集群的伸缩性设计
如果HTTP请求分发装置可以感知或者可以配置集群的服务器数量,可以及时发现集群中新上线或下线的服务器,并能向新上线的服务器分发请求,停止向已下线的服务器分发请求,就实现了应用服务器的集群的伸缩性。
3.1 HTTP重定向负载均衡服务器
推荐指数: ★
该负载均衡的实现主要依靠的是HTTP的重定向(302)用户发送一个请求到负载均衡服务器114.100.20.200,该负载均衡服务器根据某种负载均衡算法获得一台真实Web服务器地址114.100.20.203,构造一个包含该Web服务器地址的重定向响应返回给浏览器,浏览器在重新发送请求到Web服务器114.100.20.203。
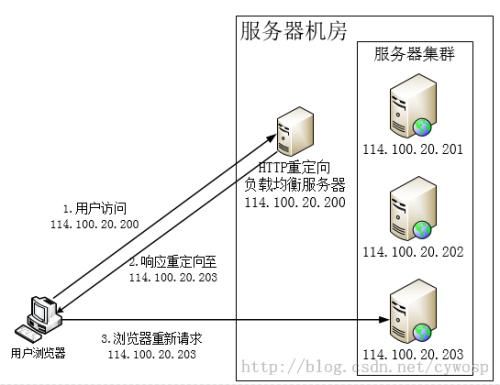
该方案相对比较简单,浏览器需要两次请求服务器才能完成一次访问,性能较差。同时重定向服务器自身也可能成为瓶颈,伸缩性有限。使用HTTP302响应码重定向,可能使搜索引擎判断为SEO作弊。
3.2 DNS域名解析负载均衡
推荐指数: ★★★
主要利用DNS处理域名解析请求的同时进行负载均衡处理的一种方案。通过在DNS服务器中配置多个A记录。每次域名解析都会根据负载均衡算法计算出一个不同的IP地址返回。这样A记录中配置的多个服务器就构成了集群,实现了负载均衡。如下,浏览器发送请求解析域名www.apusapp.com,DNS根据A记录和负载均衡算法计算得到一个IP地址114.100.20.203,并返回给浏览器。浏览器根据IP 114.100.20.203访问真实物理服务器。
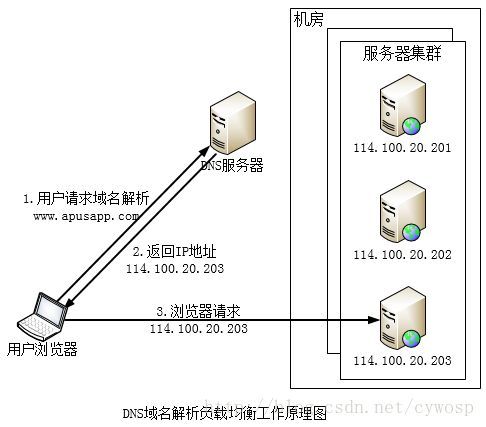
该方案的优点是将负载均衡的工作转交给DNS,且DNS支持基于地理位置的域名解析,可提升网站的访问性能。目前的DNS是多级解析,每一级DNS都可能缓存A记录,当下线某台服务器后,即使修改了DNS的A记录,要使其生效也需要一定时间,这段时间DNS仍然会将域名解析到下线的服务器上。且负载均衡依赖DNS域名解析和其负载均衡,在这方面无法对网站进行管理和优化。
事实上大型网站总是部分的使用DNS域名解析,利用域名解析作为第一级负载均衡,将域名解析地址指向内部负载均衡服务器,内部负载均衡服务器再将请求分发到真是的Web服务器上。
3.3反向代理负载均衡
推荐指数: ★★★★
该负载均衡主要是利用反向代理实现应用服务器的负载均衡。浏览器发送请求至反向代理服务器114.100.80.10,反向代理服务器根据负载均衡算法计算得到一台真实物理web服务器10.0.0.3,并将请求转发给服务器。10.0.0.3处理完成请求响应返回给反向代理服务器,反向代理服务器在将请求响应给用户。
PS:反向代理服务器可以缓存资源,可以改善网站性能。
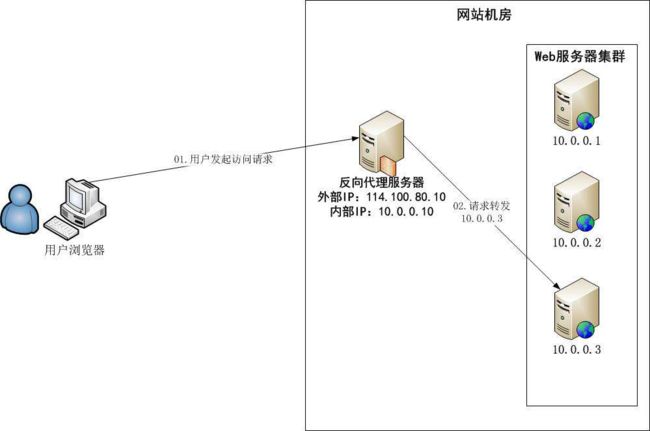
反向代理服务器转发请求在HTTP协议层面,因此也称应用层负载均衡。优点是将负载均衡和反向代理服务器功能集成在一起。缺点是反向代理服务器处理所有请求和响应,可能成为性能瓶颈。
3.4 IP负载均衡
推荐指数: ★★★★
该负载均衡主要是通过网络层修改请求目的IP地址进行负载均衡。浏览器发送请求至负载均衡服务器114.100.20.200,负载均衡服务器根据某种负载均衡算法计算得到一台真是web服务器地址192.168.1.1,该负载均衡服务器将数据包的目的地址修改为192.168.1.1,真实Web处理完成,响应数据包回到负载均衡服务器,负载均衡服务器再将数据包源地址修改为自身的IP地址200.100.50.1发送给浏览器。
究竟真实物理Web服务器响应数据包如何返回给负载均衡服务器?
1) 负载均衡服务器在修改目的IP地址的时候,将源地址修改为自身IP地址,即源地址转换(SNAT)。
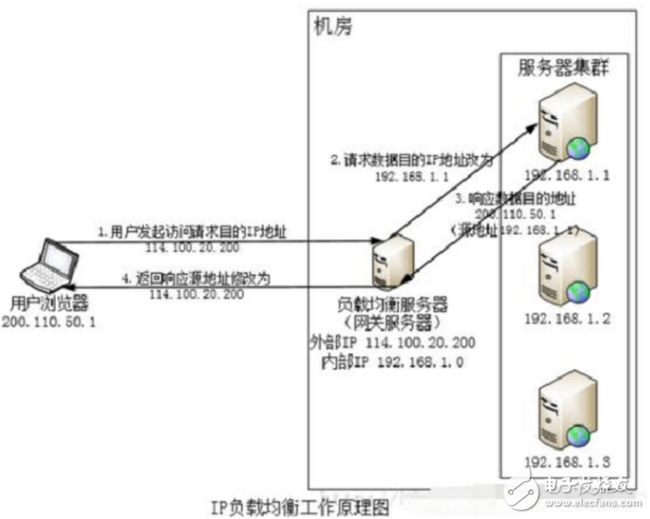
该方案的优点是负载均衡在内核进程中完成数据分发,较反向代理负载均衡有更好的处理性能。但由于所有的请求响应都通过负载均衡服务器,集群的最大吞吐量受限于负载均衡服务器网卡带宽。
3.5数据链路层负载均衡
推荐指数: ★★★★★
在IP负载均衡中所有的请求和响应都是通过负载均衡服务器,是否可以将响应直接通过真实物理web服务器呢?
数据链路层负载均衡是在通信协议的数据联络层修改mac地址进行负载均衡。通过配置真实物理服务器集群所有虚拟IP和负载均衡服务器IP地址一致,从而达到在不修改数据包的源地址和目的地址就可以进行数据分发的目的。
浏览器发送请求到负载均衡服务器114.100.20.200,负载均衡服务器根据负载均衡算法,获取一台真实物理web服务器mac地址,并将请求数据报文的目的mac地址修改为真实物理web服务器的mac地址。web服务器处理完成直接响应给用户。
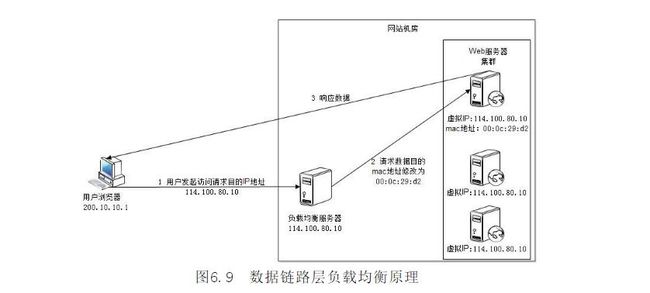
三角传输模式的数据链路层负载均衡解决了IP负载均衡服务器的请求和响应的瓶颈问题,数据链路层负载均衡服务器是目前大型网站使用最广的一种负载均衡手段。在Linux平台上,最好的数据链路层负载均衡开源产品是LVS(Linux Virtual Service)。
3.6 负载均衡算法
在实现负载均衡中主要分成两个步骤:
1) 根据负载均衡算法和Web服务器列表计算得到集群中一台Web服务器地址。
2)将请求数据转发给集群中计算得到的Web服务器。
上面多次提及“负载均衡算法”,具体的负载均衡算法主要有以下几种:
A:轮询
在所有硬件资源都相同的场景下,所有请求被依次分发到每台应用服务器上,每台的服务器需处理的请求数据都相同称为轮询。
B:加权轮询
根据硬件资源的情况,在轮询的基础上,按照配置的权重将请求分发到每个服务器上。
C:随机
请求被随机的分配到各个应用服务器,在许多场合下,这种方案都很简单实用。主要是好的随机数本身就很均衡(也可实现加权随机)。
D:最少连接
记录每个应用服务器正在处理的连接数(请求数),将新到的请求分发到最少连接的服务器上,这种最符合负载均衡定义的算法(也可实现加权最少连接)。
E:源地址散列
根据请求地址的IP进行Hash计算,得到应用服务器,实现来自同一IP地址的请求总是在同一个服务器上处理,在一个会话周期内重复使用,实现会话黏带。
4. 分布式缓存集群的伸缩性设计
分布式缓存集群和应用服务器集群的伸缩性设计不同,主要是应用服务器是无状态的,而缓存服务器中记录的热点数据,一旦新的缓存服务器加入没有缓存任何数据,下架的缓存服务器还缓存这网站的许多热点数据,一旦缓存服务器替换,请求就可能直达数据库。
分布式缓存集群的伸缩性必须保证新上线的缓存服务器对整个分布式缓存集群影响最小,原先的缓存的数据尽可能的还能被访问到。
4.1 Memcached分布式缓存集群
Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。Memcached基于一个存储键/值对的hashmap。其守护进程(daemon )是用C写的,但是客户端可以用任何语言来编写,并通过memcached协议与守护进程通信。
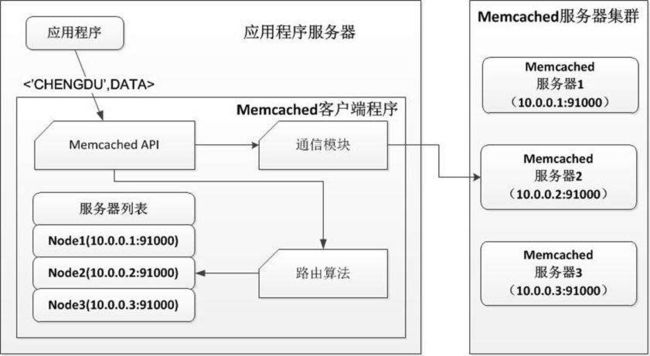
应用程序通过Memcached客户端访问Memcached服务器集群。 Memcached客户端由一组API、路由算法、通信模块构成。其中路由算法负责根据用户输入的缓存数据KEY计算得到应该将数据写入到Memcached的哪台服务器(写缓存)或者应该从哪台服务器读数据(读缓存)。
应用程序数据需要写缓存的数据<'CHENGDU',DATA>,API将KEY输入路由算法模块,路由算法根据KEY和Memcached集群服务器列表计算得到一台服务编号Node1,进而得到该地址的IP和端口(10.0.0.2:91000)。API调用通信模块和编号为Node1的服务器通信,将数据写入该服务器。读缓存依此类推。
4.2 Memcached分布式缓存集群的伸缩性挑战
在Memcached分布式缓存系统中,对于服务器集群的管理,路由算法至关重要,和负载均衡算法一样,决定着被访问的真实物理服务器。
余数Hash:用服务器数目除缓存数据KEY的Hash值,余数为服务器列表下标编号。因为HashCode具有随机性,能够保证整个Memcached服务器集群比较均衡的分布。如果不需要考虑缓存服务器集群的伸缩性,余数Hash就可以满足绝大多数的缓存路由需求。一旦需要考虑缓存服务器集群的伸缩性,余数Hash就难以为继,每增加一台缓存服务器,缓存不能命中的概率将会达到N/(N+1)。将网站3台缓存服务器扩容至4台缓存服务器,改变了服务器列表数量,也就改变了KEY指向的缓存服务器,不能命中的概率(3/4),当扩容至100台,不能命中的概率99%。
4.3 分布式缓存的一致Hash算法
针对余数Hash存在的问题主要是路由算法的问题,能否通过改进路由算法使得新加入的服务器不影响大部分缓存正确命中率呢?
一致Hash算法基于一致Hash环的数据结构实现KEY到缓存服务器的Hash映射。
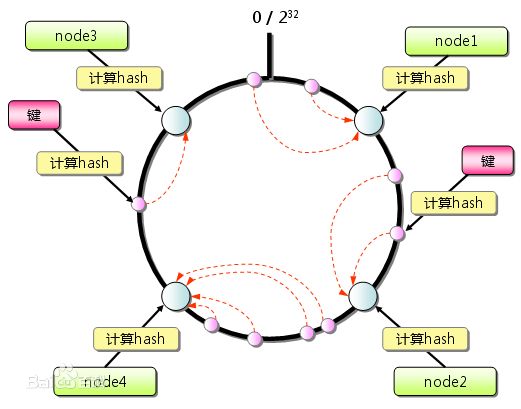
具体的算法原理:先构造一个长度为2^32的整数环(这个环被称为一致Hash环),根据节点名称的Hash值,将缓存服务器节点放置在这个Hash换上。然后根据KEY值计算得到其Hash值,从Hash环顺时针查找距离这个KEY的Hash值最近的缓存服务器节点,完成KEY到服务器Hash映射查找。
加入的新节点Node后,原来的KEY大部分还能继续计算到原来的节点,只有新节点的和上一个节点之间的KEY需要重新缓存。3台缓存服务器扩容至4台时,继续命中原有缓存数据的概率为75%,远高于余数Hash25%。99台缓存服务器扩容至100台时,命中率为99%。在具体应用中,这个一致Hash环通常使用二叉查找树实现。
上述的一致Hash环基本上解决了分布式缓存集群伸缩性问题,但是这里存在一个问题:假设之前有4台缓存服务器,其中存储的数据量25对/台,如果新增一台缓存服务器,按照计算应该保证数据量20对/台。上述的一致Hash环新增一个节点Node4,只影响原来的节点Node2,而原先的Node1和Node3不变,意味着各个节点的缓存比例为:
node1:node2:node3:node4=2:1:2:1
这显然不是我们需要的结果。
在计算网络中我们也遇到过这类问题,OSI的7层协议,每一层都可以看作是下一层的虚拟。解决上述一致性Hash算法的负载不均衡问题,可以通过使用虚拟层手段实现:
将每台物理缓存服务器虚拟为一组虚拟缓存服务器,将虚拟服务器的Hash值放置在Hash环上,KEY在环上先找到虚拟服务器节点,再得到物理服务器的信息。
新加入物理服务器节点时,是将一组虚拟节点加入环中,如果虚拟节点的数据足够多,这组虚拟节点会影响同样多数目的已经在环上存在的虚拟节点,这些已经存在的虚拟节点有对应不同的物理节点。
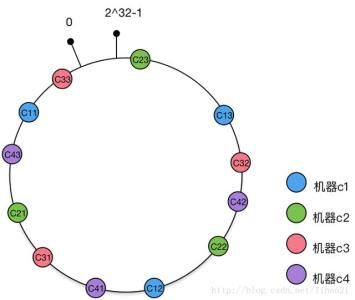
新加节点机器c4对应的一组虚拟节点为C41、C42、C43,加入到一致Hash环后,影响C31、C22、C11三个虚拟节点,而这三个虚拟节点分别对应机器c3、机器c2、机器c1三个物理节点。在理想情况下,每个物理节点受影响的数据量(还在缓存中,但是不能被访问到数据)为其节点缓存数据量的1/4(X/(N+X),N为原有物理节点数,X为新增物理节点数),意味着集群中已经被缓存的数据有75%可以被继续命中,和未使用虚拟节点的一致性Hash算法结果相同。
5. 数据存储服务器集群的伸缩性设计
数据存储服务器集群和缓存以及应用服务器集群设计不同,数据存储服务器集群的伸缩性对数据的持久性和可用性提出更高的要求。
数据存储服务器必须保证数据的可靠存储,在任何情况下都必须保证数据的可用性和正确性。数据存储服务器集群的伸缩性设计会更加复杂一点,可以分为关系数据库集群的伸缩性设计和NoSQL数据库集群的伸缩性设计。
5.1关系数据库集群的伸缩性设计
市场上主要的关系数据库都支持数据复制功能,使用这个功能可以对数据库进行简单的伸缩。利用MySQL的数据复制功能,进行读写分离,数据的写操作都在MySQL的主服务器上,而数据的读操作都在MySQL的从数据库上。如下图:
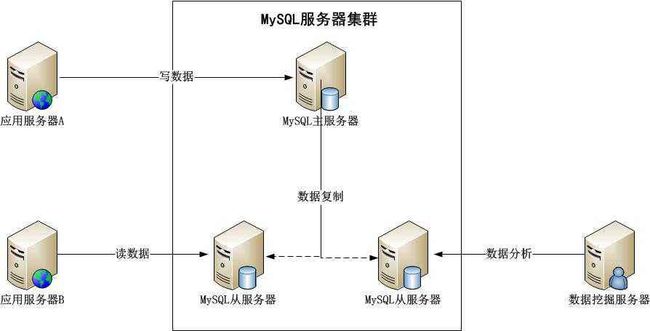
同时,也可通过业务分割模式将不同业务数据表部署在不同的数据库集群中,即数据分库(存在制约是不能进行Join操作)。大型网站中的单表数据量可能很大,需要进行分片处理,将一张表拆开分别存储在多个数据库中。
支持数据分片的分布式关系数据产品主要有:Amoeda、Cobar和Mycat等。(暂时还未对这方面有所了解,待续……)
5.2NoSQL数据库的伸缩性设计
NoSQL指非关系的、分布式的数据库设计模式。NoSQL放弃了关系数据库的2大重要基础:第一、 以关系代数为基础的结构化查询语言SQL;第二、事务一致性保证(ACID)。重点强化大型网站的高可用性和可伸缩性。
(暂时还未对这方面有所了解,待续……)