上回我们讲到了dmzj漫画搜索爬虫(一),紧接着上一回的代码,我们继续进行深入的爬取分析。
分析详情页
首先,先改一下上回的代码,让我们可以先把详情页的具体链接和信息先保存到json文件中,这样可以直接从文件中读取相关的详情页链接。
def post_request(keywords):
response = requests.post(SEARCH_URL, data={"keywords": str(keywords)})
try:
html = etree.HTML(response.content)
ul_tags = html.xpath('//ul[@class="update_con autoHeight"]/li')
res = []
item = {}
for li_tag in ul_tags:
item['name'] = li_tag.xpath('./a/@title')[0]
item['url'] = li_tag.xpath('./a/@href')[0]
item['cover'] = li_tag.xpath('./a/img/@src')
item['author'] = li_tag.xpath('//p[@class="auth"]/text()')[0]
item['status'] = li_tag.xpath('//p[@class="newPage"]/text()')[0]
# click.echo(json.dumps(item, ensure_ascii=False)) ##删除
with open('./search_result.json', mode='w', encoding='utf-8') as f:
f.write(json.dumps(item, ensure_ascii=False))
except Exception as e:
raise e
输出的结果如下:
{
"name": "第一次的Gal",
"url": "http://manhua.dmzj.com/diyicidegal",
"cover": [
"https://images.dmzj.com/webpic/3/diyicidegalV3.jpg"
],
"author": "植野メグル",
"status": "最新:第33话"
}
基于以上的结果,我们将提取其中的URL,然后进行该漫画的详情页的页面分析。
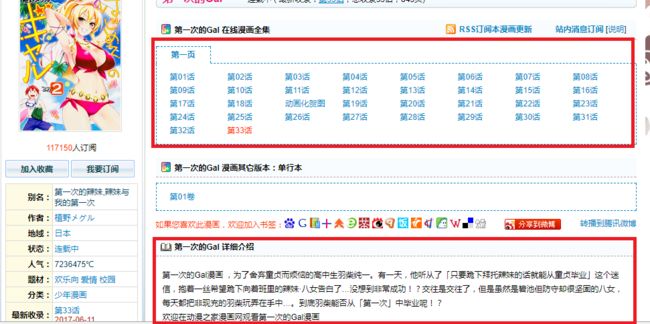
需要采集的信息
红框标注的信息为我们在详情页需要采集的信息。
- 第一个红框表示的信息为具体的某话的漫画内容,从这里进去可以获取到最终的漫画图片内容。
- 第二个红框表示的信息为该漫画的内容简介。
本小节的内容主要就是采集这两块内容,为后续的搜索爬虫的具体形成做参考。
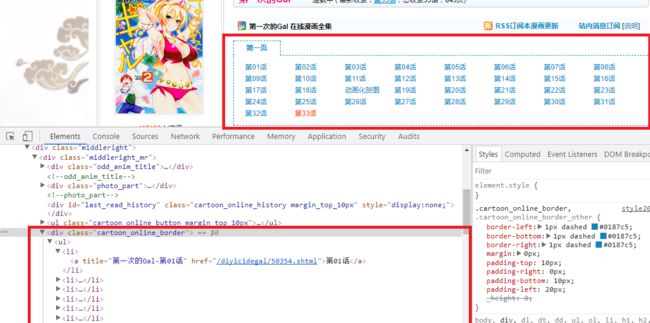
漫画具体话对应DOM节点
如同上一节所讲述的一样,我们还是采用Chrome 开发者工具,通过右键检查来定位具体的DOM节点,从上图可以清晰的看出,漫画具体话数包裹在类名为 cartoon_online_border的DIV节点中。同时,下面所有的某某话的 a标签节点也可以很清楚的看出。
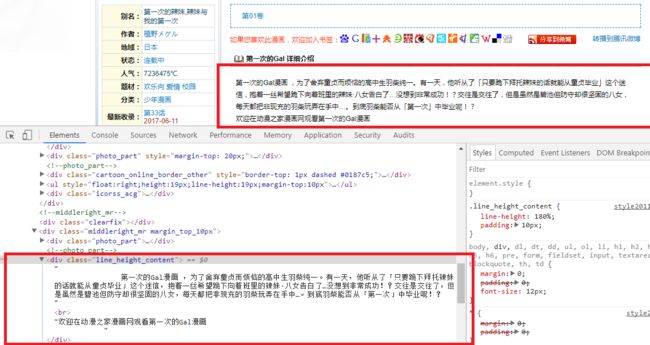
内容简介对应的DOM节点
同样的,我们可以从上图中看出内容简介包裹于类名为 line_height_content的DIV节点中。
根据以上两个分析,我们可以书写出以下的代码:
# -*- coding: utf-8 -*-
import requests
import json
from lxml import etree
import click
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/56.0.2924.87 Safari/537.36',
'Referer': 'http://www.dmzj.com/category'
}
PREIX = 'http://manhua.dmzj.com'
def get_request(url):
response = requests.get(url, headers=headers)
try:
html = etree.HTML(response.content)
a_tags = html.xpath('//div[@class="cartoon_online_border"]/ul/li/a')
# 内容简介
text_tag = html.xpath('//div[@class="line_height_content"]/text()')[0]
item = {'data': [], 'synopsis': text_tag.replace('\n', '').strip()}
for a_tag in a_tags:
# 具体的某话
temp = {'title': a_tag.xpath('./@title')[0],
'href': PREIX + a_tag.xpath('./@href')[0]}
item['data'].append(temp)
with open('./details.json', mode='w', encoding='utf-8') as f:
# ensure_ascii设置为False,防止中文乱码
f.write(json.dumps(item, ensure_ascii=False))
except Exception as e:
raise e
if __name__ == '__main__':
info = None
f = open('./search_result.json', mode='r', encoding='utf-8')
info = json.load(f)
get_request(info['url'])
输出的结果:
{
"data": [
{
"title": "第一次的Gal-第01话",
"href": "http://manhua.dmzj.com/diyicidegal/50354.shtml"
},
{
"title": "第一次的Gal-第02话",
"href": "http://manhua.dmzj.com/diyicidegal/50431.shtml"
},
{
"title": "第一次的Gal-第03话",
"href": "http://manhua.dmzj.com/diyicidegal/50799.shtml"
},
{
"title": "第一次的Gal-第04话",
"href": "http://manhua.dmzj.com/diyicidegal/51606.shtml"
},
{
"title": "第一次的Gal-第05话",
"href": "http://manhua.dmzj.com/diyicidegal/51585.shtml"
},
{
"title": "第一次的Gal-第06话",
"href": "http://manhua.dmzj.com/diyicidegal/52078.shtml"
},
{
"title": "第一次的Gal-第07话",
"href": "http://manhua.dmzj.com/diyicidegal/52079.shtml"
},
{
"title": "第一次的Gal-第08话",
"href": "http://manhua.dmzj.com/diyicidegal/52052.shtml"
},
{
"title": "第一次的Gal-第09话",
"href": "http://manhua.dmzj.com/diyicidegal/52721.shtml"
},
{
"title": "第一次的Gal-第10话",
"href": "http://manhua.dmzj.com/diyicidegal/52817.shtml"
},
{
"title": "第一次的Gal-第11话",
"href": "http://manhua.dmzj.com/diyicidegal/53319.shtml"
},
{
"title": "第一次的Gal-第12话",
"href": "http://manhua.dmzj.com/diyicidegal/53366.shtml"
},
{
"title": "第一次的Gal-第13话",
"href": "http://manhua.dmzj.com/diyicidegal/54369.shtml"
},
{
"title": "第一次的Gal-第14话",
"href": "http://manhua.dmzj.com/diyicidegal/55430.shtml"
},
{
"title": "第一次的Gal-第15话",
"href": "http://manhua.dmzj.com/diyicidegal/55521.shtml"
},
{
"title": "第一次的Gal-第16话",
"href": "http://manhua.dmzj.com/diyicidegal/55556.shtml"
},
{
"title": "第一次的Gal-第17话",
"href": "http://manhua.dmzj.com/diyicidegal/56315.shtml"
},
{
"title": "第一次的Gal-第18话",
"href": "http://manhua.dmzj.com/diyicidegal/56380.shtml"
},
{
"title": "第一次的Gal-动画化贺图",
"href": "http://manhua.dmzj.com/diyicidegal/56767.shtml"
},
{
"title": "第一次的Gal-第19话",
"href": "http://manhua.dmzj.com/diyicidegal/57129.shtml"
},
{
"title": "第一次的Gal-第20话",
"href": "http://manhua.dmzj.com/diyicidegal/59057.shtml"
},
{
"title": "第一次的Gal-第21话",
"href": "http://manhua.dmzj.com/diyicidegal/59136.shtml"
},
{
"title": "第一次的Gal-第22话",
"href": "http://manhua.dmzj.com/diyicidegal/59722.shtml"
},
{
"title": "第一次的Gal-第23话",
"href": "http://manhua.dmzj.com/diyicidegal/59744.shtml"
},
{
"title": "第一次的Gal-第24话",
"href": "http://manhua.dmzj.com/diyicidegal/59826.shtml"
},
{
"title": "第一次的Gal-第25话",
"href": "http://manhua.dmzj.com/diyicidegal/59935.shtml"
},
{
"title": "第一次的Gal-第26话",
"href": "http://manhua.dmzj.com/diyicidegal/60095.shtml"
},
{
"title": "第一次的Gal-第27话",
"href": "http://manhua.dmzj.com/diyicidegal/60122.shtml"
},
{
"title": "第一次的Gal-第28话",
"href": "http://manhua.dmzj.com/diyicidegal/60651.shtml"
},
{
"title": "第一次的Gal-第29话",
"href": "http://manhua.dmzj.com/diyicidegal/60901.shtml"
},
{
"title": "第一次的Gal-第30话",
"href": "http://manhua.dmzj.com/diyicidegal/60930.shtml"
},
{
"title": "第一次的Gal-第31话",
"href": "http://manhua.dmzj.com/diyicidegal/61471.shtml"
},
{
"title": "第一次的Gal-第32话",
"href": "http://manhua.dmzj.com/diyicidegal/61810.shtml"
},
{
"title": "第一次的Gal-第33话",
"href": "http://manhua.dmzj.com/diyicidegal/62187.shtml"
}
],
"synopsis": "第一次的Gal漫画 ,为了舍弃童贞而烦恼的高中生羽柴纯一。有一天,他听从了「只要跪下拜托辣妹的话就能从童贞毕业」这个迷信,抱着一丝希望跪下向着班里的辣妹·八女告白了…没想到非常成功!?交往是交往了,但是虽然是碧池但防守却很坚固的八女,每天都把非现充的羽柴玩弄在手中…。到底羽柴能否从「第一次」中毕业呢!?"
}
哈哈,写的有点简单了!就酱紫了,下期再见呢!!
下一篇文章