前言:
文章以Andrew Ng 的 deeplearning.ai 视频课程为主线,记录Programming Assignments 的实现过程。相对于斯坦福的CS231n课程,Andrew的视频课程更加简单易懂,适合深度学习的入门者系统学习!
这一部分的作业主要涉及到Logistic Regression,Logistic Regression 用于Binary Classification二分类的问题(0,1),基于多分类的Softmax也是在Logistic Regression的基础上改进而来,这次Assignment的数据集为data.h5,包含train_data和test_data,label分别为cat和non_cat,,首先我们看一下数据集,对数据集有一个直观的认识:
1 Overview of the Problem set
train_set_x_orig, train_set_y, test_set_x_orig, test_set_y, classes = load_dataset()
index = 25
plt.imshow(train_set_x_orig[index])
print ("y = " + str(train_set_y[:, index]) + ", it's a '" + classes[np.squeeze(train_set_y[:, index])].decode("utf-8") + "' picture.")
程序输出:y = [1], it's a 'cat' picture.

我们需要对图片进行预处理,从而转化为我们需要的shape类型,并且需要normalization从而加速收敛
m_train = train_set_x_orig.shape[0]
m_test = test_set_x_orig.shape[0]
num_px = train_set_x_orig.shape[1]
train_set_x_flatten =train_set_x_orig.reshape([train_set_x_orig.shape[0],-1]).T
test_set_x_flatten = test_set_x_orig.reshape([test_set_x_orig.shape[0],-1]).T
print ("train_set_x_flatten shape: " + str(train_set_x_flatten.shape))
print ("train_set_y shape: " + str(train_set_y.shape))
print ("test_set_x_flatten shape: " + str(test_set_x_flatten.shape))
print ("test_set_y shape: " + str(test_set_y.shape))
print ("sanity check after reshaping: " + str(train_set_x_flatten[0:5,0]))
train_set_x = train_set_x_flatten/255.
test_set_x = test_set_x_flatten/255.

2 General Architecture of the learning algorithm
The following figure explains the architecture of the learning algorithm,this algorithm can distinguish cat images from non-cat images:

3 Building the parts of our algorithm
def sigmoid(z):
s = 1./(1+np.exp(-z))
return s
def initialize_with_zeros(dim):
w =np.zeros((dim,1))
b = 0
return w, b
def propagate(w, b, X, Y):
A = sigmoid(np.dot(w.T,X)+b)
cost =-1/m*(np.sum(Y*np.log(A)+(1-Y)*np.log(1-A)))
dw =1/m*np.dot(X,(A-Y).T)
db = 1/m*np.sum(A-Y)
cost = np.squeeze(cost)
grads = {"dw": dw,
"db": db}
return grads, cost
def optimize(w, b, X, Y, num_iterations, learning_rate, print_cost = False):
costs = []
for i in range(num_iterations):
grads, cost = propagate(w, b, X, Y)
dw = grads["dw"]
db = grads["db"]
w = w-learning_rate*dw
b = b-learning_rate*db
if i % 100 == 0:
costs.append(cost)
if print_cost and i % 100 == 0:
print ("Cost after iteration %i: %f" %(i, cost))
params = {"w": w,
"b": b}
grads = {"dw": dw,
"db": db}
return params, grads, costs
def predict(w, b, X):
m = X.shape[1]
Y_prediction = np.zeros((1,m))
w = w.reshape(X.shape[0], 1)
A = sigmoid(np.dot(w.T,X)+b)
for i in range(A.shape[1]):
if A[0,i]>0.5:
Y_prediction[0][i]=1
else:
Y_prediction[0][i]=0
return Y_prediction
def model(X_train, Y_train, X_test, Y_test, num_iterations = 2000, learning_rate = 0.5, print_cost = False):
w, b = initialize_with_zeros(X_train.shape[0])
parameters, grads, costs = optimize(w, b, X_train, Y_train,num_iterations,learning_rate,print_cost)
w = parameters["w"]
b = parameters["b"]
Y_prediction_test = predict(w, b, X_test)
Y_prediction_train = predict(w, b, X_train)
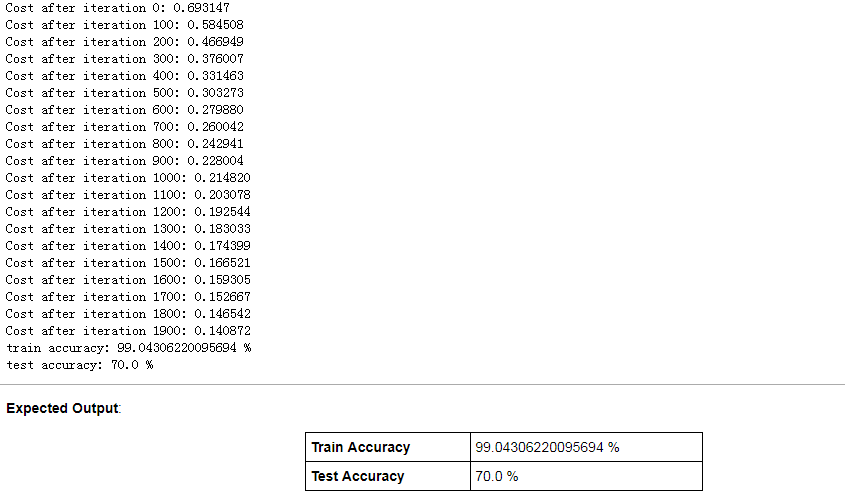
print("train accuracy: {} %".format(100 - np.mean(np.abs(Y_prediction_train - Y_train)) * 100))
print("test accuracy: {} %".format(100 - np.mean(np.abs(Y_prediction_test - Y_test)) * 100))
d = {"costs": costs,
"Y_prediction_test": Y_prediction_test,
"Y_prediction_train" : Y_prediction_train,
"w" : w,
"b" : b,
"learning_rate" : learning_rate,
"num_iterations": num_iterations}
return d
现在我们可以用model函数来进行训练:
d = model(train_set_x, train_set_y, test_set_x, test_set_y, num_iterations = 2000, learning_rate = 0.005, print_cost = True)
训练结果如图所示:
index = 1
plt.imshow(test_set_x[:,index].reshape((num_px, num_px, 3)))
print ("y = " + str(test_set_y[0,index]) + ", you predicted that it is a \"" + classes[d["Y_prediction_test"][0,index]].decode("utf-8") + "\" picture.")

我们可以看一下随着迭代次数的增加,cost的变化情况
costs = np.squeeze(d['costs'])
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds)')
plt.title("Learning rate =" + str(d["learning_rate"]))
plt.show()
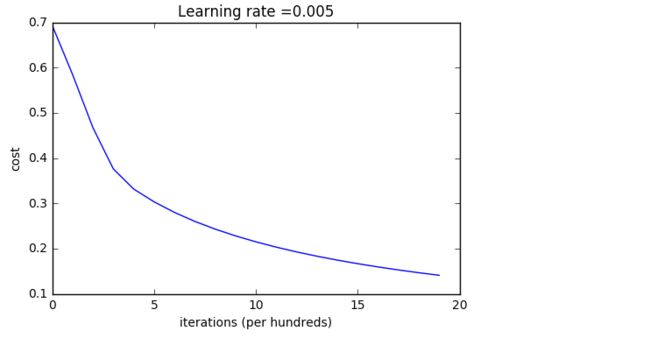
对于不同的learning_rate,cost曲线变化明显:

4 Test with your own image
我们可以用模型训练出来的参数对图片进行预测,判断是否为猫的图片
my_image = "my_image.jpg"
fname = "images/" + my_image
image = np.array(ndimage.imread(fname, flatten=False))
my_image = scipy.misc.imresize(image, size=(num_px,num_px)).reshape((1, num_px*num_px*3)).T
my_predicted_image = predict(d["w"], d["b"], my_image)
plt.imshow(image)
print("y = " + str(np.squeeze(my_predicted_image)) + ", your algorithm predicts a \"" + classes[int(np.squeeze(my_predicted_image)),].decode("utf-8") + "\" picture.")
预测结果为:
y = 0.0, your algorithm predicts a "non-cat" picture.
最后附上我作业的得分,表示我的程序没有问题,如果觉得我的文章对您有用,请随意打赏,我将持续更新Deeplearning.ai的作业!
