缘起
就像我很多年都没搞懂Excel数据透视表一样,我对PowerQuery的透视和逆透视也是一直迷迷糊糊。直到今天遇到一个实际的例子。
我更新windows10时,从微软网站上下载了一个关于此更新的文件信息csv文件。一时兴起,想拿这个文件来练练手。
文件链接见:http://pan.baidu.com/share/link?shareid=2260904732&uk=3579801784
文件分析
这是一个csv文件,我用Excel打开之后,发现这个文件其实分为两部分:一部分是很标准的表格形式:

这种格式很好处理。
从第32544行开始,数据变成另一种格式:

我准备建立三个查询:一个是原始数据,一个是第一部分数据,再一个是第二部分数据。
原始数据处理思路
第一部分数据,从前三行都是无效数据,因此可以通过Table.Skip()来跳过前三行。
这里有个奇怪的地方是,我导入原始数据时,用的是从csv文件导入,但是PowerQuery居然不能正确识别分隔符,导致所有数据都在同一列,我表示不知道为什么【2016年11月14日补充:应该是PowerQuery老版本的bug之类的问题,我刚才将Office2016升级到1610.7466.2038后问题解决】。所以只好按文本处理,然后手动分列,最终代码如下:
let
源 = Table.FromColumns({Lines.FromBinary(File.Contents("C:\Users\wangh\Downloads\3197954.csv"))}),
用分隔符分列 = Table.SplitColumn(源,"Column1",Splitter.SplitTextByDelimiter(","),{"Column1.1", "Column1.2", "Column1.3", "Column1.4", "Column1.5", "Column1.6", "Column1.7", "Column1.8", "Column1.9"}),
删除的顶端行 = Table.Skip(用分隔符分列,3),
提升的标题 = Table.PromoteHeaders(删除的顶端行)
in
提升的标题
第一部分数据处理思路
第一部分数据在原始数据查询的基础上进行引用,这样原始数据将来万一需要任何修改的话,可以很方便地将修改结果反映到第一部分数据处理这个查询上。
这里的难点是如何安全高效剔除第二部分数据。当然可以加载到excel表格中,手动找到第二部分开始的前一行的行号,然后回到查询编辑器里,用Table.FirstN()来筛选出第一部分数据。但这种办法只适用于处理这一个文件。PowerQuery的魅力在于流程化处理满足条件的所有文件而不是某个特定文件,因此,需要用更动态的法子来获取截断处的行号。我用的是:
List.PositionOf(Table.Column(源,"File name"),"Additional file information")
因为通过观察发现,截断处附近包含文本"Additional file information"。可以合理假设其他微软的类似文件也都有这句话,所以找到这句话所在的行号,就可以截取了。
第一部分数据处理的完整代码如下:
let
源 = 原始,
保留的行 = Table.FirstN(源,List.PositionOf(Table.Column(源,"File name"),"Additional file information")),
已删除的空行 = Table.SelectRows(保留的行, each not List.IsEmpty(List.RemoveMatchingItems(Record.FieldValues(_), {"", null})))
in
已删除的空行
第二部分数据处理思路
第二部分的数据有两种方法可以获得,一是反向合并两个表格,二是老老实实利用处理第一部分数据的思路来获取。我采取的是第二种方法。
这里要注意的是,第二部分数据开始的第一个数据片段,跟后面的数据片段相比,少了一行,所以,这个片段是无效数据,需要剔除。我用了Table.Skip()来剔除。
接下来处理掉每个数据片段的空格。直接在UI上选择删除空行。
接下来就到了这个例子中最复杂的部分了。
数据都是每7行、每两列为一条完整的记录,因此,我们需要将六行两列变成一行六列的有效记录。
我们知道行变列可以用转置的方法,但是在这个例子是行不通的,因为并不是简单的行列转换问题。
这里需要Table.Pivot()函数。
在开始透视之前,还有一个额外的步骤要做,就是为每一条记录设置一个ID。如果不设置这个ID,直接透视,PowerQuery会报如下错误:
Expression.Error: 枚举中用于完成该操作的元素过多。
为什么会这样,我还不清楚,我只知道获取记录的ID之后,就不会报错。
获取ID的第一步是为表格添加索引,可以直接在UI的“添加列”选项卡找到“添加索引列”命令,我们添加一个开始为1的索引列。之所以开始为1,主要是我个人爱好——觉得这样好理解。其实在后面我们还要通过运算将索引变为0开始才能正确获取记录的ID。
接下来是再添加一列,获取ID:
ID = Table.AddColumn(已添加索引, "ID", each Number.IntegerDivide([索引]-1,6)),
可以看到将索引列减1就是将其变成从0开始。
这里这个Number.IntegerDivide()很过瘾,就是返回两个相除之后商的整数部分。由于每一条记录的六行所在的索引号减去1之后除以6,获取的商的整数部分都相同,因此,可以判断出这里的整数商就是判断是否同一条记录的依据,因此这是获取ID的关键步骤。
注意获取ID之后有一个重命名表格列名称的步骤,原因在于我们整理原始数据时将列标题处理好了,但是现在第二部分数据的列标题需要从行里获取,如果获取之后的列标题和已有列标题重复,PowerQuery会报错。这个步骤可以在导入源之后的操作及Table.Pivot()操作中间的任何一步进行。
接下来是选取我们需要的列,删除那些不需要的列。
到这一步,我们才真正开始用Table.Pivot()函数来获取数据:
已透视列 = Table.Pivot(删除的其他列,List.Distinct(Table.Column(删除的其他列,"Column1")), "Column1","Column2"),
我个人一直认为这个Table.Pivot()函数很不好理解,事实上我也是折腾了好久才偶然弄出我想要的结果来。
第一个参数“删除的列”是要透视的表格,这个没什么好说。
第二个参数是要将行里的数据提取成为透视后的表格列标题。在此例中,Column1里边的数据就是我们要变成列标题的数据。由于这一列的所有数据都是六个标题行的重复,因此我们需要获取不重复值,因此
List.Distinct(Table.Column(删除的其他列,"Column1"))
得到的其实是一个有6行的list。这个list的每一个元素将作为透视后的表格的每一列。
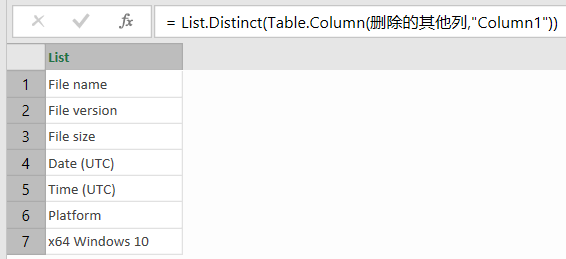
【注意截图中其实是7行。最后那一行x64 Windows10我表示很懵比,不知道它从哪里钻出来的,后来检查原始数据,才知这个第二部分的数据其实也是分了两部分:x86和x64两部分。鉴于我太懒,而且x64部分删除空格后,它的第一个片段也是5行,加上x64 Windows10这一行,还是构成一个完整的6行,并不会导致数据发生紊乱,所以懒得对它进行单独处理了。】
回到Table.Pivot()函数上来。
第三个和第四个参数其实就是原始表格中,记录(Record)的属性(Attribute)和值(Value)。透视后,产生的每一条记录,其属性来源于第三个参数,其值来源于第四个参数。在这个例子中,每一条记录的属性都在原始表格第二部分数据的第一列,值都在第二列。

如果用PowerQuery的角度来理解表格(Table)和记录(Record)会比较好理解。可以参见微软官方网站的Table.Pivot()示例: https://msdn.microsoft.com/zh-cn/library/mt260767
let
源 = 原始,
删除的顶端行 = Table.Skip(源,List.PositionOf(Table.Column(源,"File name"),"Additional file information")+4),
删除的列 = Table.RemoveColumns(删除的顶端行,{"File size", "Date", "Time", "Platform", "SP requirement", "Service branch", ""}),
删除的顶端行1 = Table.Skip(删除的列,6),
已删除的空行 = Table.SelectRows(删除的顶端行1, each not List.IsEmpty(List.RemoveMatchingItems(Record.FieldValues(_), {"", null}))),
已添加索引 = Table.AddIndexColumn(已删除的空行, "索引", 1, 1),
ID = Table.AddColumn(已添加索引, "ID", each Number.IntegerDivide([索引]-1,6)),
重命名的列 = Table.RenameColumns(ID,{{"File name", "Column1"}, {"File version", "Column2"}}),
删除的其他列 = Table.SelectColumns(重命名的列,{"ID", "Column1", "Column2"}),
已透视列 = Table.Pivot(删除的其他列,List.Distinct(Table.Column(删除的其他列,"Column1")), "Column1","Column2"),
删除的列1 = Table.RemoveColumns(已透视列,{"x64 Windows 10", "ID"})
in
删除的列1