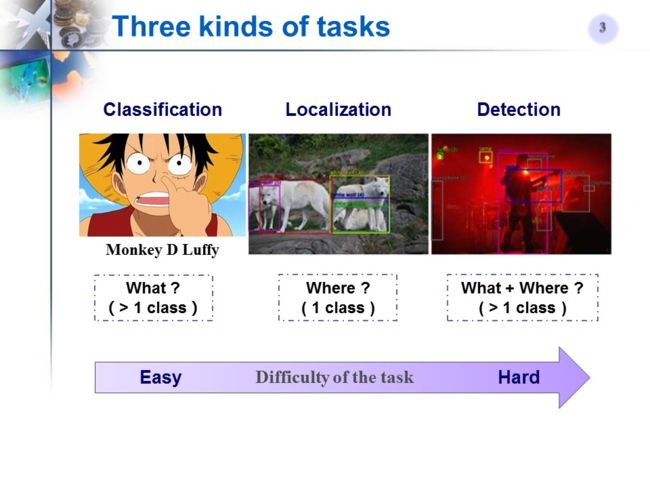
分类,检测,定位:
www.open-open.com/lib/view/open1477274580713.html (2016-10-24)
目标检测的发展
传统的目标检测一般使用滑动窗口的框架,主要包括三个步骤:
(1) 利用不同尺寸的滑动窗口框住图中的某一部分作为候选区域;
(2) 提取候选区域相关的视觉特征。比如人脸检测常用的Harr特征;行人检测和普通目标检测常用的HOG特征等;
(3) 利用分类器进行识别,比如常用的SVM模型。
传统的目标检测中,多尺度形变部件模型DPM(Deformable Part Model)[13]是出类拔萃的,连续获得VOC(Visual Object Class)2007到2009的检测冠军,2010年其作者Felzenszwalb Pedro被VOC授予”终身成就奖”。DPM把物体看成了多个组成的部件(比如人脸的鼻子、嘴巴等),用部件间的关系来描述物体,这个特性非常符合自然界很多物体的非刚体特征。DPM可以看做是HOG+SVM的扩展,很好的继承了两者的优点,在人脸检测、行人检测等任务上取得了不错的效果,但是DPM相对复杂,检测速度也较慢,从而也出现了很多改进的方法。正当大家热火朝天改进DPM性能的时候,基于深度学习的目标检测横空出世,迅速盖过了DPM的风头,很多之前研究传统目标检测算法的研究者也开始转向深度学习。
基于深度学习的目标检测发展起来后,其实效果也一直难以突破。比如文献[6]中的算法在VOC 2007测试集合上的mAP只能30%多一点,文献[7]中的OverFeat在ILSVRC 2013测试集上的mAP只能达到24.3%。2013年R-CNN诞生了,VOC 2007测试集的mAP被提升至48%,2014年时通过修改网络结构又飙升到了66%,同时ILSVRC 2013测试集的mAP也被提升至31.4%。
其实在R-CNN之前已经有很多研究者尝试用Deep Learning的方法来做目标检测了,包括OverFeat[7],但R-CNN是第一个真正可以工业级应用的解决方案,这也和深度学习本身的发展类似,神经网络、卷积网络都不是什么新概念,但在本世纪突然真正变得可行,而一旦可行之后再迅猛发展也不足为奇了。
R-CNN这个领域目前研究非常活跃,先后出现了R-CNN[1,2,3,18]、SPP-net[4,19]、Fast R-CNN[14, 20]、Faster R-CNN[5,21]、R-FCN[16,24]、YOLO[15,22]、SSD[17,23]等研究。Ross Girshick作为这个领域的开山鼻祖总是神一样的存在,R-CNN、Fast R-CNN、Faster R-CNN、YOLO都和他有关。这些创新的工作其实很多时候是把一些传统视觉领域的方法和深度学习结合起来了,比如选择性搜索(Selective Search)和图像金字塔(Pyramid)等。
从近两年的CVPR会议来看,目标检测的研究方向是怎么样的?
www.zhihu.com/question/34223049 (2017-03-18)
目前object detection的工作可以粗略的分为两类:
(1) 使用region proposal的,目前是主流,比如RCNN、SPP-Net、Fast-RCNN、Faster-RCNN以及MSRA最近的工作R-FCN。
(2) 端到端(End-to-End),无需区域提名,不使用region proposal的,YOLO,SSD。
从我这个渣渣的视野来看,这些工作都体现的一个趋势:如何让不同ROI之间尽量多的共享计算量,并充分利用CNN得到的特征,使得整个detection的速度变快。
具体说来,我们先回忆一下基于region proposal的方法的大致流程是什么样的:
1. 从待检测的图片中,提取出N个ROI,这里N远大于图片中真实object的个数。具体的方法有selective search、edge box以及最近流行起来的RPN。
2. 根据1中检测到的ROI,上CNN对图像进行feature extraction。
3. 对2中得到的feature进行分类,比如对于PSACAL VOC数据,就是一个21分类的问题(20个object class+background)。
4. boudningbox regression。
注意:上述几个步骤应该都是测试的步骤
RCNN对于每个ROI,都跑一遍CNN,即使这些ROI之间是有overlap的,显然有部分计算是重复的,所以SPP-net和fast rcnn就在这方面做了文章,具体做法是先用CNN抽取整张图的特征,然后利用ROI pooling抽取对应ROI的特征,使得不同ROI共享特征提取的计算量。结果就是原来我处理一张图像需要前向2000次CNN,现在只要前向一次就好了,极大的提升了计算速度
fast rcnn还通过multi-task loss实现了一个end to end的系统,这里不是我们的重点。 fast-rcnn提出来之后,detection的性能瓶颈变成了计算region proposal。CPU实现的selective search处理一张图需要2秒钟,远大于GPU上CNN特征抽取的时间。Faster RCNN就是要解决这个问题,他的出发点是这样的:既然用CNN进行feature extraction这一步已经无法避免,那么我们为什么不更充分地利用得到的feature?具体来说,我们是不是可以直接用CNN得到的feature来进行region proposal,答案是肯定的。Faster RCNN将CNN得到的feature输入到一个两层网络(RPN),网络的输出就是region proposal。这样一来,region proposal的额外开销就只有一个两层网络。实验证明这样不仅速度变快,而且proposal的质量也更高了。
到目前为止,上面我们说的4个步骤中,第1步和第2步都可以通过前向一遍CNN来得到,所以前俩步都不再是速度的瓶颈。然后我们考虑第3步,假设我们用faster rcnn的RPN得到了300个region proposal,在预测的过程中,我们需要对300个region proposal去做分类,每个region proposal都要经过多个FC层,这个时间开销仍然是很大的,所以就有了R-FCN这个工作。具体来说,是先利用FCN进行类似semantic segmentation的计算,然后利用ROI对相应的区域进行average pooling,得到整个ROI关于21个类别的置信度。简单的说就是把分类这个过程也融合到网络的前向计算过程中,由于这个过程对于不同的ROI是共享的,所以比单独跑分类器要快好多。文章里还有一个position-sensitive的idea,也很有趣,不过感觉给我一种”这也能行“的感觉,应该是我少见多怪,理解不了大神的世界。
个人感觉object detection是一个比较考验insight以及”让一个idea真正能work的能力“的方向,不像semantic segmentation,后者现在的提升很多靠CRF,有陷入”图模型加圈“(传说中水论文三大法宝之一)的趋势,对数学要求比较高。
以上只是个人读paper的心得,可能作者们当时并不是这么想的,如有冲突,纯属我瞎bb
...
Overfeat
本文作为目标检测的一篇回顾,先来看看目标检测中广泛使用的区域提名——选择性搜索,以及用深度学习做目标检测的早期工作——Overfeat。
(1) 选择性搜索
目标检测的第一步是要做区域提名(Region Proposal),也就是找出可能的感兴趣区域(Region Of Interest, ROI)。区域提名类似于光学字符识别(OCR)领域的切分,OCR切分常用过切分方法,简单说就是尽量切碎到小的连通域(比如小的笔画之类),然后再根据相邻块的一些形态学特征进行合并。但目标检测的对象相比OCR领域千差万别,而且图形不规则,大小不一,所以一定程度上可以说区域提名是比OCR切分更难的一个问题。
区域提名可能的方法有:
一、滑动窗口。滑动窗口本质上就是穷举法,利用不同的尺度和长宽比把所有可能的大大小小的块都穷举出来,然后送去识别,识别出来概率大的就留下来。很明显,这样的方法复杂度太高,产生了很多的冗余候选区域,在现实当中不可行。
二、规则块。在穷举法的基础上进行了一些剪枝,只选用固定的大小和长宽比。这在一些特定的应用场景是很有效的,比如拍照搜题APP小猿搜题中的汉字检测,因为汉字方方正正,长宽比大多比较一致,因此用规则块做区域提名是一种比较合适的选择。但是对于普通的目标检测来说,规则块依然需要访问很多的位置,复杂度高。
三、选择性搜索。从机器学习的角度来说,前面的方法召回是不错了,但是精度差强人意,所以问题的核心在于如何有效地去除冗余候选区域。其实冗余候选区域大多是发生了重叠,选择性搜索利用这一点,自底向上合并相邻的重叠区域,从而减少冗余。
区域提名并不只有以上所说的三种方法,实际上这块是非常灵活的,因此变种也很多,有兴趣的读者不妨参考一下文献[12]。
选择性搜索的具体算法细节[8]如算法1所示。总体上选择性搜索是自底向上不断合并候选区域的迭代过程。
输入:
输出:候选的目标位置集合L
算法:
...
...
此处省略,看原博客
...
从算法不难看出,R中的区域都是合并后的,因此减少了不少冗余,相当于准确率提升了,但是别忘了我们还需要继续保证召回率,因此算法1中的相似度计算策略就显得非常关键了。如果简单采用一种策略很容易错误合并不相似的区域,比如只考虑轮廓时,不同颜色的区域很容易被误合并。选择性搜索采用多样性策略来增加候选区域以保证召回,比如颜色空间考虑RGB、灰度、HSV及其变种等,相似度计算时既考虑颜色相似度,又考虑纹理、大小、重叠情况等。
总体上,选择性搜索是一种比较朴素的区域提名方法,被早期的基于深度学习的目标检测方法(包括Overfeat和R-CNN等)广泛利用,但被当前的新方法弃用了。
(2) OverFeat
OverFeat[7][9]是用CNN统一来做分类、定位和检测的经典之作,作者是深度学习大神之一——Yann Lecun在纽约大学的团队。OverFeat也是ILSVRC 2013任务3(分类+定位)的冠军得主[10]。
OverFeat的核心思想有三点:
1. 区域提名:结合滑动窗口和规则块,即多尺度(multi-scale)的滑动窗口;
2. 分类和定位:统一用CNN来做分类和预测边框位置,模型与AlexNet[12]类似,其中1-5层为特征抽取层,即将图片转换为固定维度的特征向量,6-9层为分类层(分类任务专用),不同的任务(分类、定位、检测)公用特征抽取层(1-5层),只替换6-9层;
3. 累积:因为用了滑动窗口,同一个目标对象会有多个位置,也就是多个视角;因为用了多尺度,同一个目标对象又会有多个大小不一的块。这些不同位置和不同大小块上的分类置信度会进行累加,从而使得判定更为准确。
OverFeat的关键步骤有四步:
1. 利用滑动窗口进行不同尺度的区域提名,然后使用CNN模型对每个区域进行分类,得到类别和置信度。从图2中可以看出,不同缩放比例时,检测出来的目标对象数量和种类存在较大差异;

2. 利用多尺度滑动窗口来增加检测数量,提升分类效果,如图3所示

3. 用回归模型预测每个对象的位置,从图4中来看,放大比例较大的图片,边框数量也较多

4. 边框合并。

Overfeat是CNN用来做目标检测的早期工作,主要思想是采用了多尺度滑动窗口来做分类、定位和检测,虽然是多个任务但重用了模型前面几层,这种模型重用的思路也是后来R-CNN系列不断沿用和改进的经典做法。
当然Overfeat也是有不少缺点的,至少速度和效果都有很大改进空间,后面的R-CNN系列在这两方面做了很多提升。