出
1、pc机的组成
处理器
存储器
主板与芯片组
主板起连接作用,主板上还有两颗重要的芯片俗称北桥和南桥芯片,统称芯片组,主要负责处理器和其他部件的通信。
上北下南,和处理器相邻的桥称为北桥,北桥下面的桥称为南桥。
北桥负责处理器与那些需要较高通信带宽部件间的通信,主要是存储器和显卡。
南桥负责处理器与较低速度部件间的接口,通常连接各种输入输出设备。
输入设备
输出设备
显卡
将cpu送来的图像数据处理成显示器认识的格式,再送到显示器显示图像。
通信接口
QPI是Intel最新的芯片间点对点互联技术,用于将两个处理器连接器起来,或者是是连接处理器与北桥芯片,
PCI/PCI-E外部设备互联
的总线
SATA采用串行方式传输数据,是目前硬盘的主要接口,一次传送一位数据。
USB
显示器接口VGA-传输模拟信号,DVI-传输数字信号,HDMI
2、初识处理器
处理器的分层模型
指令集体系结构
处理器微架构
处理器物理实现
内核
存储器
外设与接口
硬件指标
性能
时钟基准MIPS:misp越高,则理论上每秒可以执行的指令数越多。
综合基准:运行相同的程序,比较所需要的时间。
专业评估组织基准
3、指令集体系结构

CISC复杂指令集
变长编码
SISC精简指令集
定长编码
CISC指令的一条指令常常对应RISC的多条指令,在RISC处理器中,过分精简的指令数量,使得RISC处理器与存储器之间的数据交换增多,而存储器的工作速度远远低于处理器,很容易导致性能恶化。

指令集分类

4、汇编语言格式
机器字长
机器字长表示处理器一次处理数据的长度,主要由运算器,寄存器决定,如32位处理器,每个寄存器能存储32bit数据,加法器支持两个32bit数相加。
32位处理器的地址总线通常都是32位,可寻址范围为4Gbyte,总线宽度越宽,可寻址范围越大。通常数据总线的宽度都要高于机器字长,可以一次读取更多的数据。
操作数个数
RISC指令集,基本运算都使用3个操作数,2个原操作数,一个目的操作数:ADD A1,A2,A3
操作数的顺序
x86指令格式:ADD BX AX;表示将BX与AX的值相加,结果放到BX中。
C6000 DSP指令格式:ADD A1,A2,A3;表示将A1和A2的值相加,结果放到A3中。
MISP指令集也是3个操作数,与C600 DSP不同的是:目的操作数时第一个操作数。
指令类型
算数逻辑指令:加法,乘法,移位,除法
控制指令:循环,跳转
数据传送指令:
load *A1 ,A2;将存储器某地址处的值导入到A2中,该存储器地址记录在寄存器A1中。
store A3,*A4;将寄存器A3中的值导出到存储器某地址处,该存储器地址记录在寄存器A4中。
5、微架构
流水线
流水级数

三级流水线
取指—>译码—>执行
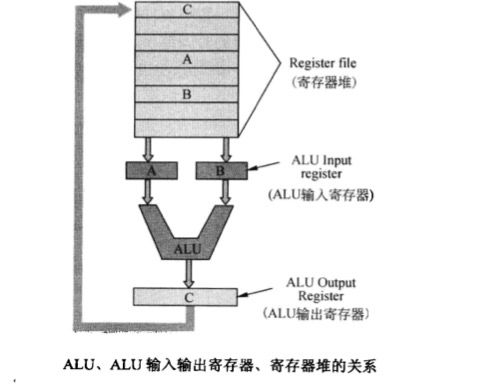
在汇编语言中,ALU(算数逻辑单元)直接访问通用寄存器进行,在硬件实现时,通用寄存器中的数据先被读到流水线寄存器中,即ALU的输入寄存器,ALU运算结束后,数据会存储在ALU的输出寄存器中,最后再送回通用寄存器。
五级流水线

流水线的冒险
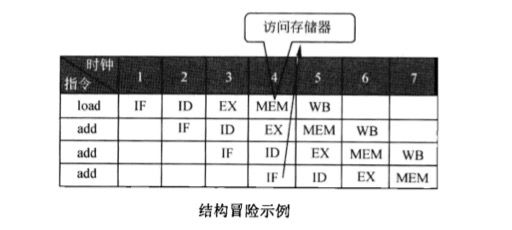
结构冒险
因为处理器资源的冲突,而无法实现某些指令的组合,就称为该处理器有结构冒险。
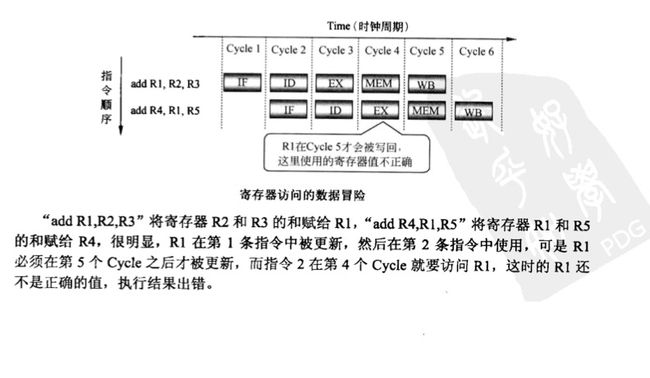
数据冒险
控制冒险
在流水线处理器中,指令是并行处理的,在当前指令正在执行时,后面的很多条指令已经完成了取值和译码等步骤,然而当程序中出现跳转语句时,如果程序等实际执行路径是要跳转到其他的地址执行,那么流水线中已经做的那些取指和译码工作就白做了。
控制冒险-分支预测
分支预测算法
1-bit预测:如果该跳转指令上一次发生了跳转,就预测这一次也发生跳转。如果上一次没有发生跳转,就预测这一次也不会跳转。
2-bit预测:每个跳转指令的预测状态信息从1bit增加到2bit计数器,如果这个跳转执行了,就加1,加到3就不加了。如果这个跳转不执行,就减1,减到0就不减了,当计数器的值为0和1的时候,这个分支不执行,当计数器值为2和3的时候,就预测这个分支执行。
分支预测实现
Inter的分支预测模块包含3个单元
Branch Target Buffer(BTB)
The Static Predictor
Return Stack
BTB:包含历史跳转信息,用于预测分支指令是否发生跳转。
The Static Predictor(静态预测器):人们将分支指令的执行情况做了大量的统计,从中总结出一些特性,并且将这些特性总结成一些固定的策略。默认的跳转策略为:向下跳转预测为不跳转,向上跳转预测为跳转。
Return Stack(返回栈):在函数调用时,将函数的返回地址压栈到Return Stack中,当遇到函数返回指令时,就从Return stack中取地址。
条件执行
从顺序执行到乱序执行
指令的相关
寄存器相关
当两条语句共用寄存器时,他们就是相关的。
控制相关
去除指令的相关性
去数据相关
去控制相关
去伪相关
处理器的ISA寄存器数目通常较少,编译器在将程序中的变量映射到寄存器时,会导致多个变量共用一个寄存器,这样即使时不相关的指令,也会使用同样的寄存器,导致了名字相关,我们将ISA寄存器重新映射到处理器内部的物理寄存器,由于物理寄存器较多,相同的ISA寄存器可以映射到不同的物理寄存器,经过映射后,新的指令就能使用不同的物理寄存器,指令间的相关性也就消除了。
寄存器重命名
(1)将每一条指令的目的寄存器映射到新的物理寄存器
(2)指令的源寄存器映射为ISA寄存器最近映射到的那个物理寄存器
(3)当本条指令完成后,该目的寄存器映射的更早的物理寄存器就可以释放。
处理器的乱序执行
buffer的作用——缓存没有执行的指令
(1)抗波动(2)去耦合
指令调度
指令什么时候执行?

指令的顺序提交
乱序执行后,指令的结果虽然已经出来了,但这个结果并没有立即提交到ISA寄存器中,而是先缓存起来,只有当前指令前面的指令提交后,这条指令才会提交。
顺序提交可以解决精确中断和解决投机执行出错的问题。

乱序执行总结

处理器的并行设计

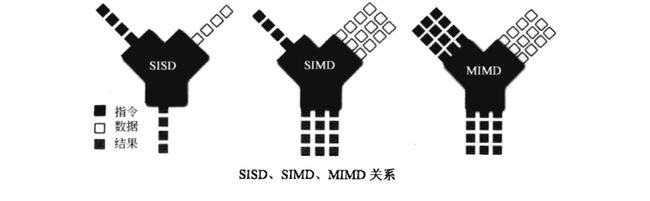
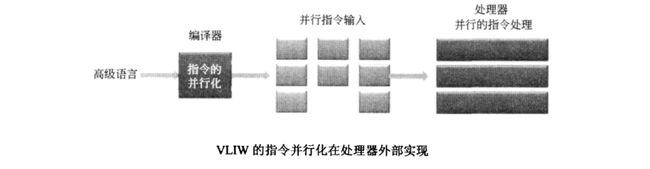
Supercalar:标量处理器时代的指令都是串行执行的,处理器为了兼容原有的程序,但同时又要提高程序执行效率,就在处理器内部做了指令的并行化处理。这就是超标量处理器的基本原型。
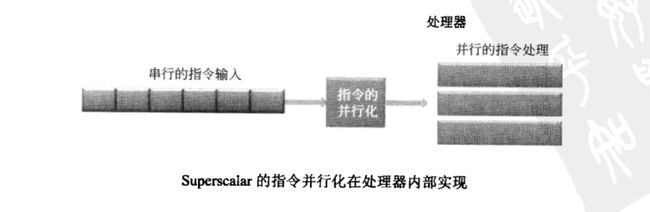
VLIW:(Very Long Instruction Word)如果将指令的并行化显示的声明在指令格式中,处理器只会傻乎乎的执行。指令的并行化可由编译器完成,也可以由程序员手工写并行汇编代码实现。
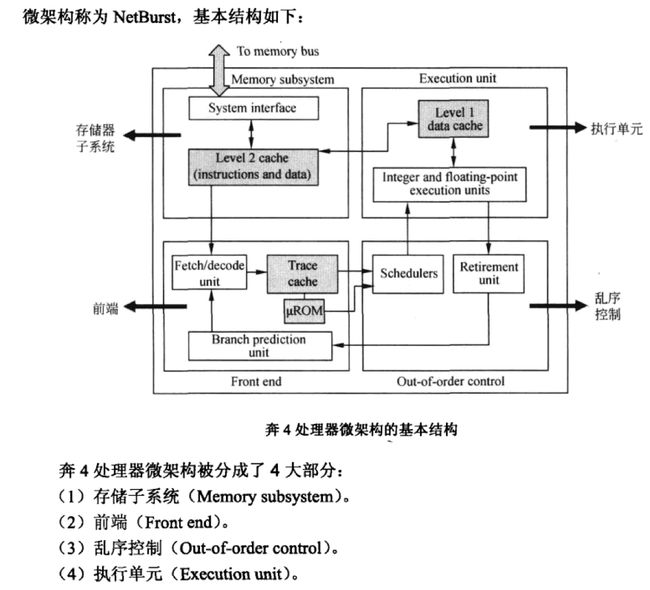
Superscalar处理器的实例——Inter P4 CPU

线程并行
多线程——时分复用
现代程序设计都将程序分成多个线程,每个线程完成各自的功能,结合起来实现一个应用。
操作系统采用时间片轮转的方式,隔一定的时间就切换到新的线程执行。
硬件多线程
1.粗粒度
当处理器发现一个线程被长时间中断时,这是处理器就切换到其他线程去执行。
2.细粒度
处理器的每个cycle轮流发射不同线程的指令。