
一.管道机制(pipe)
1.Linux的fork操作
在计算机领域中,尤其是Unix及类Unix系统操作系统中,fork是一种复制自身而创建自身进程副本的操作。它通常是内核实现的一种系统调用。Fork是类Unix操作系统上创建进程的一种主要方法,甚至历史上是唯一方法。
由fork创建的新进程被称为子进程(child process)。该函数被调用一次,但返回两次。两次返回的区别是子进程的返回值是0,而父进程的返回值则是新进程(子进程)的进程 id。将子进程id返回给父进程的理由是:一个进程的子进程可以多于一个,没有一个函数使一个进程可以获得其所有子进程的进程id。对子进程来说,之所以fork返回0给它,是因为它随时可以调用getpid()来获取自己的pid;也可以调用getppid()来获取父进程的id。(进程id 0总是由交换进程使用,所以一个子进程的进程id不可能为0 )。
fork之后,操作系统会复制一个与父进程完全相同的子进程,虽说是父子关系,但是在操作系统看来,他们更像兄弟关系,这2个进程共享代码空间,但是数据空间是互相独立的,子进程数据空间中的内容是父进程的完整拷贝,指令指针也完全相同,子进程拥有父进程当前运行到的位置(两进程的程序计数器pc值相同,也就是说,子进程是从fork返回处开始执行的),但有一点不同——如果fork成功,子进程中fork的返回值是0,父进程中fork的返回值是子进程的进程号;如果fork不成功,父进程会返回错误。
可以这样想象,2个进程一直同时运行,而且步调一致,在fork之后,他们分别作不同的工作,也就是分岔了。这也是fork为什么叫fork的原因。至于那一个最先运行,可能与操作系统(调度算法)有关,而且这个问题在实际应用中并不重要。
为什么将管道机制之前要先讲讲fork机制呢?因为管道机制是建立在"具有亲缘关系的进程之间”,而如何找到这两个进程?笔者的理解是可以通过他们的id号来寻找——因为通过上面的额fork机制的讲解,我们知道父子、兄弟进程之间的id号是彼此可知的(理解不到位见谅)。
2.什么是管道机制?
管道是Linux/UNIX系统中比较原始的通信方式,他的实现以一种数据流的方式,在进程之间流动。在Linux系统中,“一切皆文件”,因此"管道(pipe)"其相当于文件系统上的一个文件,来缓存所要传输的数据。这个文件是一种“特殊的文件”,它和一般文件有些不同的:
- 管道是内核管理的一个固定大小的缓冲区。在Linux 中,该缓冲区的大小为1 页,即4KB,使得它的大小不像文件那样不加检验地增长。
- 当管道中的数据被读出时,管道中就没有数据了,文件没有这个特性。注意从管道读数据是一次性操作,数据一旦被读,它就从管道中被抛弃,释放空间以便写更多的数据。
在写管道时可能变满,当这种情况发生时,随后对管道的write()调用将默认地被阻塞,等待某些数据被读取,以便腾出足够的空间供write()调用写;当所有当前进程数据已被读取时,管道变空,当这种情况发生时,一个随后的read()调用将默认地被阻塞,等待某些数据被写入,这解决了read()调用返回文件结束的问题。
3.管道的实现机制
管道是由内核管理的一个缓冲区,相当于我们放入内存中的一个纸条。管道的一端连接一个进程的输出。这个进程会向管道中放入信息。管道的另一端连接一个进程的输入,这个进程取出被放入管道的信息。当管道中没有信息的话,从管道中读取的进程会等待,直到另一端的进程放入信息。当管道被放满信息的时候,尝试放入信息的进程会等待,直到另一端的进程取出信息。当两个进程都终结的时候,管道也自动消失。
在Linux 中,管道的实现并没有使用专门的数据结构,而是借助了文件系统的file 结构和VFS(Virtual File System,虚拟文件系统)的索引节点inode(inode是管理一个具体的文件的模块,是文件的唯一标识,一个文件对应一个inode)。通过将两个 file 结构指向同一个临时的 VFS 索引节点,而这个 VFS 索引节点又指向一个物理页面而实现的。
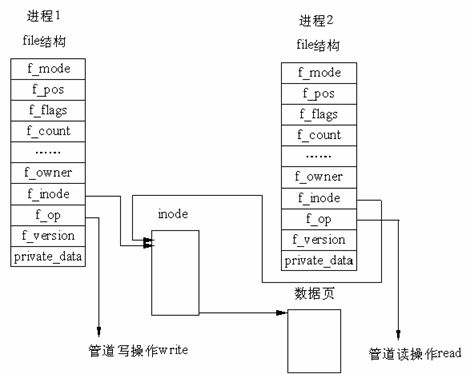
图中有两个 file 数据结构,它们定义文件操作例程地址是不同的,其中一个是向管道中写入数据的例程地址,而另一个是从管道中读出数据的例程地址。这样,用户程序的系统调用仍然是通常的文件操作,而内核却利用这种抽象机制实现了管道这一特殊操作。
4.管道机制的特点
- 管道是半双工的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道;
- 只能用于具有公共祖先(具有亲缘关系的进程)的进程之间通信,即用于父子进程或者兄弟进程之间;
- 单独构成一种独立的文件系统:管道对于管道两端的进程而言,就是一个文件,但它不是普通的文件,它不属于某种文件系统,而是自立门户,单独构成一种文件系统,并且只存在于内存中;
- 数据的读出和写入:一个进程向管道中写的内容被管道另一端的进程读出。数据的流通方式是以一种“先进先出”的队列数据结构进行,即写入的内容每次都添加在管道缓冲区的末尾,并且每次都是从缓冲区的头部读出数据。
5.管道的创建即读写规则
Linux环境下使用pipe函数创建一个匿名半双工管道,其函数原型如下:
#include
int pipe(int fd[2])
参数int fd[2]为一个长度为2的文件描述数组,fd[0]是读出端,fd[1]是写入端,函数返回值为0表示成功,-1表示失败。当函数成功返回,则自动维护了一个从fd[1]到fd[0]的数据通道。
需要注意的是,管道的两端是固定了任务的。即一端只能用于读,由描述字fd[0]表示,称其为管道读端;另一端则只能用于写,由描述字fd[1]来表示,称其为管道写端。
二.命名管道机制(FIFO)
上面说的管道通信机制的缺点就是,它们的关系一定是父子进程的关系,这就使得它的使用受到了一点的限制,但是我们可以使用命名管道来解决这个问题。
1.什么是命名管道?
命名管道也被称为FIFO文件,它在文件系统中以文件名的形式存在,和之前所讲的没有名字的管道(匿名管道)类似,有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
由于Linux中所有的事物都可被视为文件,所以对命名管道的使用也就变得与文件操作非常的统一,也使它的使用非常方便,同时我们也可以像平常的文件名一样在命令中使用。
2.命名管道的特点
- FIFO不同于管道之处在于它提供一个路径名与之关联,以FIFO的文件形式存在于文件系统中。这样,即使与FIFO的创建进程不存在亲缘关系的进程,只要可以访问该路径,就能够彼此通过FIFO相互通信。
#include
#include
int mkfifo(const char *pathname, mode_t mode);
经该函数创建一个FIFO,FIFO在文件系统中表现为为一个文件(FIFO类型文件),其中文件的路径由参数pathname指定(如果pathname路径下的文件已经存在则mkfifo返回-1),mode指定FIFO的读写权限(每个进程在调用这个方法的时候要指明自己的额权限,是写进程还是读进程)。
说了这么多了,其实FIFO就是指明了一个文件路径,创建了一个文件,然后通信的双方进程都往这个文件中读写东西,只不过一个读一个写而已——这样只要双方都知道了这个约定路径就可以读写,那么就不必一定具有亲缘关系了。当删除FIFO文件时,管道连接也随之消失。
有名管道的名字(包括路径名和读写权限)存在于文件系统中,内容存放在内存中。这样只要路径常驻与文件系统(或者磁盘)中,那么在就可快速的多次通信。
三.消息队列
Linux 中的消息可以被描述成在内核地址空间的一个内部链表,每一个消息队列由一个IPC 的标识号唯一地标识。Linux 为系统中所有的消息队列维护一个 msgque 链表,该链表中的每个指针指向一个 msgid_ds 结构,该结构完整描述一个消息队列。
这种通信方式,个人觉得非常类似于Android的Looper消息机制中的MessageQuene,即数据队列由一个链表构成,链表上的每一个消息都包含了该消息的特定格式和优先级的记录。进程间通过消息队列通信,主要是:创建或打开消息队列,添加消息,读取消息和控制消息队列。
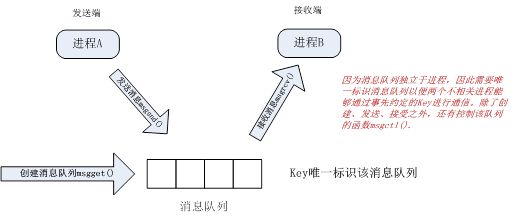
因为消息队列独立于进程而存在,为了区别不同的消息队列,需要以key值标记消息队列,这样两个不相关进程可以通过事先约定的key值通过消息队列进行消息收发。例如进程A向key消息队列发送消息,进程B从Key消息队列读取消息。
消息队列的优势
- 消息队列与管道通信相比,其优势是对每个消息指定特定的消息类型,接收的时候不需要按照先进先出的次序读取,而是可以根据自定义条件接收特定类型的消息。
- 与管道(匿名管道:只存在于内存中的文件;命名管道:存在于实际的磁盘介质或者文件系统)不同的是消息队列存放在内核中,只有在内核重启(即,操作系统重启)或者显示地删除一个消息队列时,该消息队列才会被真正的删除;而管道只要关闭其中的数据就会丢失(当然命名管道存放在磁盘上的名称不会因此丢失,除非显示的删除这个路径名及其对应的文件)。
- 另外与管道不同的是,消息队列独立于发送与接收进程,在某个进程往一个队列写入消息之前,并不需要另外某个进程在该队列上等待消息的到达。
关于消息队列我们就说到这里,这种IPC机制在实际的应用中并不多。
四.System V 共享内存
1.共享内存的概念
共享内存可以说是最有用的进程间通信方式,也是最快的IPC形式。两个不同进程A、B共享内存的意思是,同一块物理内存被映射到进程A、B各自的进程地址空间。进程A可以即时看到进程B对共享内存中数据的更新,反之亦然。由于多个进程共享同一块内存区域,必然需要某种同步机制,互斥锁和信号量都可以。
要解释清楚共享内存这种IPC机制,我们不得不从Linux中的文件结构讲起:
2.System V 共享内存实现原理
(1).Linux文件系统
操作系统的主要功能是为管理硬件资源和为应用程序开发人员提供良好的环境,但是计算机系统的各种硬件资源是有限的,因此为了保证每一个进程都能安全的执行。处理器设有两种模式:“用户模式”与“内核模式”。一些容易发生安全问题的操作都被限制在只有内核模式下才可以执行,例如I/O操作,修改基址寄存器内容等。而连接用户模式和内核模式的接口称之为系统调用。
我们知道,系统内核为一个进程分配内存地址时,通过分页映射机制可以让一个进程的物理地址不连续只需保证进程,但是进程得到的虚拟地址是连续的。进程的虚拟地址空间可分为两部分,内核空间和用户空间。内核空间中存放的是内核代码和数据,而进程的用户空间中存放的是用户程序的代码和数据。不管是内核空间还是用户空间,它们都处于虚拟空间中,都是对物理地址的映射。
应用程序中实现对文件的操作过程就是典型的系统调用过程。
虚拟文件系统
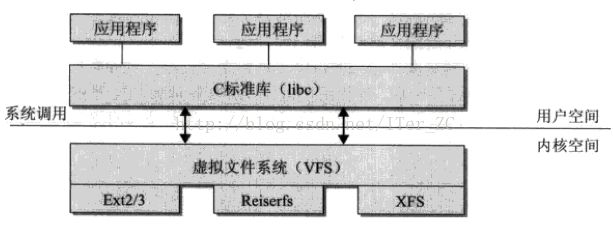
一个操作系统可以支持多种底层不同的文件系统(比如NTFS, FAT, ext3, ext4),为了给内核和用户进程提供统一的文件系统视图,Linux在用户进程和底层文件系统之间加入了一个抽象层,即虚拟文件系统(Virtual File System, VFS),进程所有的文件操作都通过VFS,由VFS来适配各种底层不同的文件系统,完成实际的文件操作。
通俗的说,VFS就是定义了一个通用文件系统的接口层和适配层,一方面为用户进程提供了一组统一的访问文件,目录和其他对象的统一方法,另一方面又要和不同的底层文件系统进行适配。如图所示:
虚拟文件系统主要模块
1、超级块(super_block),用于保存一个文件系统的所有元数据,相当于这个文件系统的信息库,为其他的模块提供信息。因此一个超级块可代表一个文件系统。文件系统的任意元数据修改都要修改超级块。超级块对象是常驻内存并被缓存的。
2、目录项模块,管理路径的目录项。比如一个路径 /home/foo/hello.txt,那么目录项有home, foo, hello.txt。目录项的块,存储的是这个目录下的所有的文件的inode号和文件名等信息。其内部是树形结构,操作系统检索一个文件,都是从根目录开始,按层次解析路径中的所有目录,直到定位到文件。
3、inode模块,管理一个具体的文件,是文件的唯一标识,一个文件对应一个inode。通过inode可以方便的找到文件在磁盘扇区的位置。同时inode模块可链接到address_space模块,方便查找自身文件数据是否已经缓存。
4、打开文件列表模块,包含所有内核已经打开的文件。已经打开的文件对象由open系统调用在内核中创建,也叫文件句柄。打开文件列表模块中包含一个列表,每个列表表项是一个结构体struct file,结构体中的信息用来表示打开的一个文件的各种状态参数。
5、file_operations模块。这个模块中维护一个数据结构,是一系列函数指针的集合,其中包含所有可以使用的系统调用函数,例如open、read、write、mmap等。每个打开文件(打开文件列表模块的一个表项)都可以连接到file_operations模块,从而对任何已打开的文件,通过系统调用函数,实现各种操作。
6、address_space模块,它表示一个文件在页缓存中已经缓存了的物理页。它是页缓存和外部设备中文件系统的桥梁。如果将文件系统可以理解成数据源,那么address_space可以说关联了内存系统和文件系统。
I/O 缓冲区
如高速缓存(cache)产生的原理类似,在I/O过程中,读取磁盘的速度相对内存读取速度要慢的多。因此为了能够加快处理数据的速度,需要将读取过的数据缓存在内存里。而这些缓存在内存里的数据就是高速缓冲区(buffer cache),下面简称为“buffer”。
具体来说,buffer(缓冲区)是一个用于存储速度不同步的设备或优先级不同的设备之间传输数据的区域。一方面,通过缓冲区,可以使进程之间的相互等待变少,从而使从速度慢的设备读入数据时,速度快的设备的操作进程不发生间断。另一方面,可以保护硬盘或减少网络传输的次数。
- Buffer和Cache
buffer和cache是两个不同的概念:cache是高速缓存,用于CPU和内存之间的缓冲;buffer是I/O缓存,用于内存和硬盘的缓冲;简单的说,cache是加速“读”,而buffer是缓冲“写”,前者解决读的问题,保存从磁盘上读出的数据,后者是解决写的问题,保存即将要写入到磁盘上的数据。
- Buffer Cache和 Page Cache
buffer cache和page cache都是为了处理设备和内存交互时高速访问的问题。buffer cache可称为块缓冲器,page cache可称为页缓冲器。页缓存page cache面向的是虚拟内存(RAM和文件之间),块I/O缓存Buffer cache是面向块设备(磁盘等之间)。
在linux不支持虚拟内存机制之前,还没有页的概念,因此缓冲区以块为单位对设备进行。在linux采用虚拟内存的机制来管理内存后,页是虚拟内存管理的最小单位,开始采用页缓冲的机制来缓冲内存。
buffer cache和page cache两者最大的区别是缓存的粒度。buffer cache面向的是文件系统的块。而内核的内存管理组件采用了比文件系统的块更高级别的抽象:页page,其处理的性能更高。因此和内存管理交互的缓存组件,都使用页缓存。
Page Cache
页缓存是面向文件,面向内存的。通俗来说,它位于内存和文件之间缓冲区,文件IO操作实际上只和page cache交互,不直接和内存交互。page cache可以用在所有以文件为单元的场景下,比如网络文件系统等等。page cache通过一系列的数据结构,比如inode, address_space, struct page,实现将一个文件映射到页的级别:
struct page结构标志一个物理内存页,通过page + offset就可以将此页帧定位到一个文件中的具体位置。同时struct page还有以下重要参数:
- 标志位flags来记录该页是否是脏页,是否正在被写回等等;
- mapping指向了地址空间address_space,表示这个页是一个页缓存中页,和一个文件的地址空间对应;
- index记录这个页在文件中的页偏移量;
文件读写基本流程
读文件
- 1、进程调用库函数向内核发起读文件请求;
- 2、内核通过检查进程的文件描述符定位到虚拟文件系统的已打开文件列表表项;
- 3、调用该文件可用的系统调用函数read()
- 3、read()函数通过文件表项链接到目录项模块,根据传入的文件路径,在目录项模块中检索,找到该文件的inode;
- 4、在inode中,通过文件内容偏移量计算出要读取的页;
- 5、通过inode找到文件对应的address_space;
- 6、在address_space中访问该文件的页缓存树,查找对应的页缓存结点:
①如果页缓存命中,那么直接返回文件内容;
②如果页缓存缺失,那么产生一个页缺失异常,创建一个页缓存页,同时通过inode找到文件该页的磁盘地址,读取相应的页填充该缓存页;重新进行第6步查找页缓存; - 7、文件内容读取成功。
写文件
前5步和读文件一致,在address_space中查询对应页的页缓存是否存在:
- 6、如果页缓存命中,直接把文件内容修改更新在页缓存的页中。写文件就结束了。这时候文件修改位于页缓存,并没有写回到磁盘文件中去。
- 7、如果页缓存缺失,那么产生一个页缺失异常,创建一个页缓存页,同时通过inode找到文件该页的磁盘地址,读取相应的页填充该缓存页。此时缓存页命中,进行第6步。
- 8、一个页缓存中的页如果被修改,那么会被标记成脏页。脏页需要写回到磁盘中的文件块。有两种方式可以把脏页写回磁盘:
①手动调用sync()或者fsync()系统调用把脏页写回
②pdflush进程会定时把脏页写回到磁盘
原文链接:从内核文件系统看文件读写过程,这里只截取一部分对本文分析有用的段落。
(2)mmap函数
mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用read,write等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。
mmap内存映射的实现过程,总的来说可以分为三个阶段:
- ①进程启动映射过程,并在虚拟地址空间中为映射创建虚拟映射区域
- ②调用内核空间的系统调用函数mmap(不同于用户空间函数),实现文件物理地址和进程虚拟地址的一一映射关系
- ③进程发起对这片映射空间的访问,引发缺页异常,实现文件内容到物理内存(主存)的拷贝
mmap和常规文件操作的区别
上面我们提到常规文件系统操作(调用read/fread等类函数)中,函数的调用过程:
- 1.进程发起读文件请求。
- 2.内核通过查找进程文件符表,定位到内核已打开文件集上的文件信息,从而找到此文件的inode。
- 3.inode在address_space上查找要请求的文件页是否已经缓存在页缓存中。如果存在,则直接返回这片文件页的内容。
- 4.如果不存在,则通过inode定位到文件磁盘地址,将数据从磁盘复制到页缓存。之后再次发起读页面过程,进而将页缓存中的数据发给用户进程。
总结来说,常规文件操作为了提高读写效率和保护磁盘,使用了页缓存机制。这样造成读文件时需要先将文件页从磁盘拷贝到页缓存中,由于页缓存处在内核空间,不能被用户进程直接寻址,所以还需要将页缓存中数据页再次拷贝到内存对应的用户空间中。这样,通过两次数据拷贝过程,才能完成进程对文件内容的获取任务。写操作也是一样,待写入的buffer在内核空间不能直接访问,必须要先拷贝至内核空间对应的主存,再写回磁盘中(延迟写回),也是需要两次数据拷贝。
而使用mmap操作文件中,创建新的虚拟内存区域和建立文件磁盘地址以及虚拟内存区域映射这两步,没有文件拷贝操作。而之后访问数据时发现内存中并无数据而发起的缺页异常过程,可以通过已经建立好的映射关系,只使用一次数据拷贝,就从磁盘中将数据传入内存的用户空间中,供进程使用。
总而言之,常规文件操作需要从磁盘到页缓存再到用户主存的两次数据拷贝。而mmap操控文件,只需要从磁盘到用户主存的一次数据拷贝过程。说白了,mmap的关键点是实现了用户空间和内核空间的数据直接交互而省去了空间不同数据不通的繁琐过程。因此mmap效率更高。
(3)System V 共享内存建立过程
第一步:shmget函数创建共享内存
shmget函数的原型为:
int shmget(key_t key, size_t size, int shmflg);
第一个参数,程序需要提供一个参数key(非0整数),它有效地为共享内存段命名,shmget函数成功时返回一个与key相关的共享内存标识符(非负整数),用于后续的共享内存函数。调用失败返回-1.
第二个参数,size以字节为单位指定需要共享的内存容量
第三个参数,shmflg是权限标志,他声明创建这段共享内存的进程是可读还是可写的
进程间需要共享的数据被放在一个叫做IPC共享内存区域的地方,任何想要访问该数据的进程都必须在本进程的地址空间新增一块内存区域,用来映射IPC共享内存区域的物理内存页面。System V 共享内存通过shmget获得或创建一个IPC共享内存区域,并返回相应的标识符(key)。
上面的shmget()函数就是用来创建IPC共享区域的,内核在保证shmget获得或创建一个共享内存区,初始化该共享内存区相应的shmid_kernel结构的同时,还将在特殊文件系统shm中,创建并打开一个同名文件,并在内存中建立起该文件的dentry及inode结构,新打开的文件不属于任何一个进程,任何进程都可以访问该共享内存区。
注:每一个共享内存区都有一个控制结构struct shmid_kernel。shmid_kernel是共享内存区域中非常重要的一个数据结构,它是存储管理和文件系统结合起来的桥梁,定义如下:
struct shmid_kernel
{
struct kern_ipc_perm shm_perm; //与内核交互,内核通过他该结构体来维护所有共享内存区
struct file * shm_file; //存储将被映射文件的地址
int id;
unsigned long shm_nattch;
unsigned long shm_segsz;
time_t shm_atim;
time_t shm_dtim;
time_t shm_ctim;
pid_t shm_cprid;
pid_t shm_lprid;
};
该结构中最重要的一个域应该是shm_file,它存储了将被映射文件的地址。每个共享内存区对象都对应特殊文件系统shm中的一个文件,一般情况下,特殊文件系统shm中的文件是不能用read()、write()等方法访问的,当采取共享内存的方式把其中的文件映射到进程地址空间后(mmap函数映射),可直接采用访问内存的方式对其访问。内核通过数据结构struct ipc_ids shm_ids维护系统中的所有共享内存区域。
第二步:shmat函数启动对该共享内存的访问
第一次创建完共享内存时,它还不能被任何进程访问,shmat函数的作用就是用来启动对该共享内存的访问,并把共享内存连接到当前进程的地址空间。它的原型如下:
void *shmat(int shm_id, const void *shm_addr, int shmflg);
第一个参数,shm_id是由shmget函数返回的共享内存标识。
第二个参数,shm_addr指定共享内存连接到当前进程中的地址位置,通常为空,表示让系统来选择共享内存的地址。
第三个参数,shm_flg是一组标志位,通常为0。
调用shmat()函数之后,系统会发现“IPC共享内存”在shm中对应的文件为空,即发生缺页,这个时候内核会使用 mmap 把这个文件从磁盘上直接映射到你的进程(虚拟)地址空间,这个时候你就能直接读写映射后的地址了。
因为在调用shmget()时,我们已经创建了文件系统shm中的一个同名文件与共享内存区域相对应,因此,调用shmat()的过程相当于映射文件系统shm中的同名文件过程。
第三步,进程之间共享数据
做完前面的两步,我们就可以利用搭好的桥梁来共享数据了,整个共享的过程中只拷贝一次数据:从输入文件到共享内存区,之后用户进程就可以直接读取了。
进程之间在共享内存时,会一直保持共享区域,直到通信完毕为止,这样,数据内容一直保存在共享内存中,并没有写回文件。共享内存中的内容往往是在解除映射时才写回文件的。因此,采用共享内存的通信方式效率是非常高的。
3.System V 共享内存的特点
1.系统V共享内存中的数据,从来不写入到实际磁盘文件中去;而通过mmap()映射普通文件实现的共享内存通信可以指定何时将数据写入磁盘文件中。注:前面讲到,系统V共享内存机制实际是通过映射特殊文件系统shm中的文件实现的,文件系统shm的安装点在交换分区上,系统重新引导后,所有的内容都丢失。
2.系统V共享内存是随内核持续的,即使所有访问共享内存的进程都已经正常终止,共享内存区仍然存在(除非显式删除共享内存),在内核重新引导之前,对该共享内存区域的任何改写操作都将一直保留。
3.System V 共享内存这种IPC机制中,进程真实所共享的内存是特殊文件系统shm中的那个同名文件。
共享内存允许两个或多个进程共享一给定的存储区,因为数据不需要来回复制,所以是最快的一种进程间通信机制。共享内存可以通过mmap()映射普通文件(特殊情况下还可以采用匿名映射)机制实现,也可以通过系统V共享内存机制实现。应用接口和原理很简单,内部机制复杂。为了实现更安全通信,往往还与信号量等同步机制共同使用,实现进程同步。