http header 消息通常被分为4个部分:general header即头部, request header即请求报文, response header即响应报文, entity header实体报文。HTTP部分看我的《图解HTTP》复习,另外这地址 也很全了。
本文章分为介绍http的Requests和response常用的字段,以及怎么解析文件类型(怎么网页,怎么解析Jason,怎么解析csv)。怎么回调和保存到csv,爬虫陷阱和解决方案等我还没看,有时间再更新吧。
Python中Requests的官方文档见:这里
Requests部分:

Responses 部分:
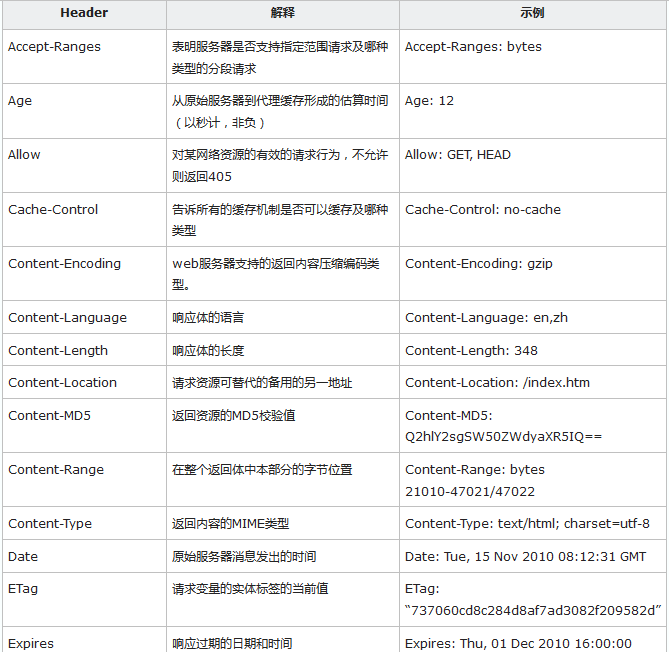
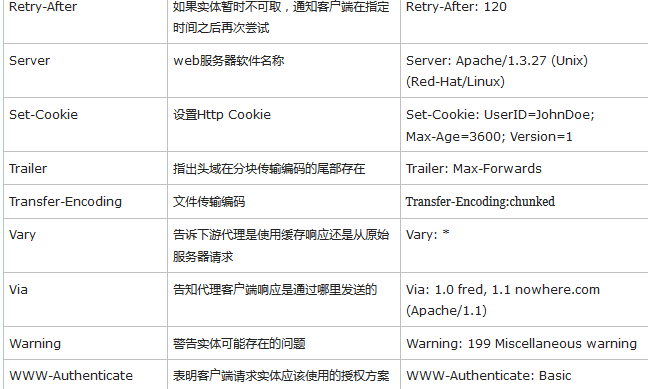
scrapy中的Requests和Response对象
Request请求方法:
scrapy.http.Request(url[, callback, method, headers, body, cookies, meta, encoding='utf-8', priority=0, dont_filter=False, errback])
其中calback是回调函数,headers是头部信息,
包含cookie的发起请求写法:
request_with_cookies = Request(url="http://www.example.com", cookies={'name': 'currency', 'value': 'USD', 'domain': 'example.com', 'path': '/currency'},meta={'dont_merge_cookies': True})
包含回调函数的请求写法:
def parse_page1(self, response):
item = MyItem()
item['main_url'] = response.url
request = scrapy.Request("http://www.example.com/some_page.html", callback=self.parse_page2)
request.meta['item'] = item
return request
def parse_page2(self, response):
item = response.meta['item']
item['other_url'] = response.url
return item
表单的请求方法:
from_response(response[, formname=None, formnumber=0, formdata=None, formxpath=None, clickdata=None, dont_click=False, ...])
formnumber:当响应内容包含多个表单的时候用到
表单模拟登陆:
import scrapy
class LoginSpider(scrapy.Spider):
name = 'example.com' start_urls = ['http://www.example.com/users/login.php']
def parse(self, response):
return scrapy.FormRequest.from_response( response, formdata={'username': 'john', 'password': 'secret'}, callback=self.after_login )
def after_login(self, response):
# check login succeed before going on
if "authentication failed" in response.body:
self.log("Login failed", level=scrapy.log.ERROR)
return
Response对象:
属性有:url, status, headers, body, flags,request,metas,
文本处理常用方法:
response.body.decode(response.encoding)
response.xpath("**")
response.css("**")
上面是scrapy的部分,其他通用的内容还有:
熟悉请求类型+会话Session+请求头+请求实体(请求内容+参数等)+响应内容+响应状态码+cookie+重定向与请求历史+超时处理等。
请求类型:get,post,put,delete等。
GET与POST方法有以下区别:
(1) 在客户端,Get方式在通过URL提交数据,数据在URL中可以看到;POST方式,数据放置在HTML HEADER内提交。
对于表单的提交方式,在服务器端只能用Request.QueryString来获取Get方式提交来的数据,用Post方式提交的数据只能用Request.Form来获取
(2) GET方式提交的数据最多只能有1024 Byte,而POST则没有此限制。
(3) 一般来说,尽量避免使用Get方式提交表单,因为有可能会导致安全问题。比如说在登陆表单中用Get方式,用户输入的用户名和密码将在地址栏中暴露无遗。但是在分页程序中,用Get方式就比用Post好。
会话:持续跟踪会话信息,让发出的所有请求之间保持 cookie。
模拟浏览器,让网络机器人看起来像人类用户。
用法:
from requests import Request
Session s = Session()
req = Request('GET', url,
data=data , #data={'key1':'value1','key2':['value2','value3']}
headers=headers #headers={'user-agent':'my-app/0.0.1'},模拟浏览器
# files=files ,files = {'file': open('report.xls', 'rb')}
)
prepped = s.prepare_request(req)
# do something with prepped.body
# do something with prepped.headers
resp = s.send(prepped,
stream=stream,
verify=verify,#验证 SSL 证书
proxies=proxies,#使用代理proxies={"http":"https":"http://10.10.1.10:1080",}
cert=cert,
timeout=timeout #超时时间
)
print(resp.status_code)
r.headers #访问服务器返回给我们的响应头部信息
r.request.headers #得到发送到服务器的请求的头部
但是网站用cookie跟踪你的访问过程,如果发现了爬虫异常行为就会中断你的访问,比如特别快速地填写表单,或者浏览大量页面。要想正确使用cookie,用PhantomJS方法。
from selenium import webdriverdriver = webdriver.PhantomJS(executable_path='')
driver.get("http://pythonscraping.com")
driver.implicitly_wait(1)
print(driver.get_cookies())
请求报文的媒体类型有:网页,jason数据,txt文本,csv文件,表单等。pdf,word,docx这里不做解释了。大家看《python网络数据采集》这本书,针对每个媒体类型的分析和代码都有写。
解析网页:
find方法,css选择器,lxml,正则表达式。这篇 文章解释的很清楚了,要好好看啊!!
案例1:爬取一个词条下的所有链接和子链接。
思路:1)一个函数getLinks,可以用维基百科词条/wiki/< 词条名称> 形式的URL 链接作为参数,然后以同样的形式返回一个列表,里面包含所有的词条URL 链接。2) 一个主函数,以某个起始词条为参数调用getLinks,再从返回的URL 列表里随机选择一个词条链接,再调用getLinks,直到我们主动停止,或者在新的页面上没有词条链接了,程序才停止运行。
完整的代码如下所示:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
random.seed(datetime.datetime.now())
def getLinks(articleUrl):
html = urlopen("http://en.wikipedia.org"+articleUrl)
bsObj = BeautifulSoup(html)
return bsObj.find("div", {"id":"bodyContent"}).findAll("a",
href=re.compile("^(/wiki/)((?!:).)*$"))
links = getLinks("/wiki/Kevin_Bacon")
while len(links) > 0:
newArticle = links[random.randint(0, len(links)-1)].attrs["href"]
print(newArticle)
links = getLinks(newArticle)
案例2:访问链接深度少于1000的整个网站
一个常用的费时的网站采集方法就是从顶级页面开始(比如主页),然后搜索页面上的所有链接,形成列表。再去采集这些链接的每一个页面,然后把在每个页面上找到的链接形成新的列表,重复执行下一轮采集。。在代码运行时,把已发现的所有链接都放到一起,并保存在方便查询的列表里(下文示例指Python 的集合set 类型)。为了全面地展示这个网络数据采集示例是如何工作的,不再限制爬虫采集的页面范围,只有“新”链接才会被采集,之后再从页面中搜索其他链接。只要遇到页面就查找所有以/wiki/ 开头的链接,也不考虑链接是不是包含分号。(提示:词条链接不包含分号,而文档上传页面、讨论页面之类的页面URL 链接都包含分号。)一开始,用getLinks 处理一个空URL,其实是维基百科的主页,因为在函数里空URL 就是http://en.wikipedia.org。然后,遍历首页上每个链接,并检查是否已经在全局变量集合pages 里面了(已经采集的页面集合)。如果不在,就打印到屏幕上,并把链接加入pages 集合,再用getLinks 递归地处理这个链接。
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
pages = set()
def getLinks(pageUrl):
global pages
html = urlopen("http://en.wikipedia.org"+pageUrl)
bsObj = BeautifulSoup(html)
for link in bsObj.findAll("a", href=re.compile("^(/wiki/)")):
if 'href' in link.attrs:
if link.attrs['href'] not in pages:
# 我们遇到了新页面
newPage = link.attrs['href']
print(newPage)
pages.add(newPage)
getLinks(newPage)
getLinks("")
案例3:收集整个网站的链接标题和正文的第一个段落
和往常一样,决定如何做好这些事情的第一步就是先观察网站上的一些页面,然后拟定一个采集模式。通过观察几个维基百科页面,包括词条和非词条页面,比如隐私策略之类的页面,就会得出下面的规则。
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
pages = set()
def getLinks(pageUrl):
global pages
html = urlopen("http://en.wikipedia.org"+pageUrl)
bsObj = BeautifulSoup(html)
try:
print(bsObj.h1.get_text())
print(bsObj.find(id="mw-content-text").findAll("p")[0])
print(bsObj.find(id="ca-edit").find("span").find("a").attrs['href'])
except AttributeError:
print("页面缺少一些属性!不过不用担心!")
for link in bsObj.findAll("a", href=re.compile("^(/wiki/)")):
if 'href' in link.attrs:
if link.attrs['href'] not in pages:
# 我们遇到了新页面
newPage = link.attrs['href']
print("----------------\n"+newPage)
pages.add(newPage)
getLinks(newPage)
getLinks("")
解析jason:
import json
from urllib.request import urlopen
def getCountry(ipAddress):
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
responseJson = json.loads(response)
return responseJson.get("country_code")
print(getCountry("50.78.253.58"))
读取文本:
1)读取整个文件:
from urllib.request import urlopen
textPage = urlopen("http://www.pythonscraping.com/pages/warandpeace/chapter1.txt")
print(textPage.read().rstrip())
2)逐行读取文件并存入列表:
from urllib.request import urlopen
filename='pi_txt"
with open(filename) as file_ob:
lines=file_ob.readline()
for line in lines:
print(textPage.read().rstrip())
读取CSV:
data = urlopen("http://pythonscraping.com/files/MontyPythonAlbums.csv")
.read().decode('ascii', 'ignore')
dataFile = StringIO(data)
csvReader = csv.reader(dataFile)
for row in csvReader:
print(row) #逐行读取文件并存入到列表
提交表单:
import requests
params = {'firstname': 'Ryan', 'lastname': 'Mitchell'}
r = requests.post("http://pythonscraping.com/files/processing.php", data=params)
print(r.text)
响应内容:
文本:requests.get('https://github.com/timeline.json') >>>r.text
二进制:不写了,这里,官方有。
响应状态码:
r.status_code,2XX OK;4XX 客户端错误 ;5XX 服务器错误响应
设置超时时间:timeout=0.001
超时处理:
def set_timeout(session,*arg)
retryTimes=20;
while retryTimes>0:
try
return session.post(*arg)
except:
............
重定向与请求历史:Response.history
用一种智能的方法来检测客户端重定向是否完成, 首先从页面开始加载时就“ 监视”DOM 中的一个元素, 然后重复调用这个元素直到Selenium 抛出一个StaleElementReferenceException 异常;也就是说,元素不在页面的DOM 里了,说明这时网站已经跳转:
from selenium import webdriverimport time
from selenium.webdriver.remote.webelement
import WebElementfrom selenium.common.exceptions
import StaleElementReferenceException
def waitForLoad(driver):
elem = driver.find_element_by_tag_name("html")
count = 0
while True:
count += 1
if count > 20:
print("Timing out after 10 seconds and returning")
return
time.sleep(.5)
try:
elem == driver.find_element_by_tag_name("html")
except StaleElementReferenceException:
return
driver =webdriver.PhantomJS(executable_path='')
driver.get("http://pythonscraping.com/pages/javascript/redirectDemo1.html")
waitForLoad(driver)
print(driver.page_source)
下载数据写入文件:
1)专门写个抓取回调基类,供各个爬虫方法使用 2)为链接爬虫添加缓存支持 3)磁盘缓存 或者 数据库缓存
这部分没看 ,等有时间看吧。
流程是:调用open方法并赋予写入模式w(读取模式是r,附加模式是a),如果没有这个文件会自动创建文件然后调用writte方法写入数据。
filename="wr.txt"
with open(filename,"w") as file_ob:
file_ob.write("i love solve questions")
爬虫陷阱和困难有:
1)用隐含字段阻止网络数据采集的方式主要有两种。第一种是表单页面上的一个字段可以用服务器生成的随机变量表示。如果提交时这个值不在表单处理页面上,服务器就有理由认为这个提交不是从原始表单页面上提交的,而是由一个网络机器人直接提交到表单处理页面的。绕开这个问题的最佳方法就是,首先采集表单所在页面上生成的随机变量,然后再提交到表单处理页面。
2)第二种方式是“蜜罐”(honey pot)。如果表单里包含一个具有普通名称的隐含字段(设置蜜罐圈套),比如“用户名”(username)或“邮箱地址”(email address),设计不太好的网络机器人往往不管这个字段是不是对用户可见,直接填写这个字段并向服务器提交,这样就会中服务器的蜜罐圈套。服务器会把所有隐含字段的真实值(或者与表单提交页面的默认值不同的值)都忽略,而且填写隐含字段的访问用户也可能被网站封杀。
如CSS 属性设置display:none 进行隐藏;电话号码字段name="phone" 是一个隐含的输入字段;邮箱地址字段name="email" 是将元素向右移动50 000 像素(应该会超出电脑显示器的边界)并隐藏滚动条
3)图片验证码与动态网页抓取JavaScript
google chrome,右键-》审查元素-》network-》清空,点击加载更多--》出现对应的get链接,寻找type=text/html,点击查看get参数或者request url。
4)去重与自然语言处理NLTK
5)监控网站随时更新情况,并发下载。估算网站大小方法,是在谷歌搜索site:xxx.com看搜索结果统计多少条。
避免爬虫陷阱的方案:
1)查看robots文件 2)两次下载之间添加延时 3)图像识别:Pillow+Tesseract+NumPy 4)cookie与代理服务器,避免IP 地址被封杀 5)Selenium 单元测试 等
查看robots文件:用python的robotparser模块解析robots文件,以避免下载禁止爬取的URLcan_fetch(user_agent,url),如果结果值为false,则是目标网站robots.txt禁止用户代理为user_agent变量值的爬虫爬取网站.
两次下载之间添加延时:设置延时的间隔值,下次下载时判断上次访问时间self.domains.get(urlparse(url).netloc)与当前时间的时间差sleepsecs是否在间隔时间内, 如果是,则线程睡眠time.sleep(sleepsecs)
其他的部分还没学到,先把网络抓取部分先把它熟透了吧。