Building a mixed-lingual neural TTS system with only monolingual data
文章地址:https://arxiv.org/pdf/1904.06063v1.pdf
合成样例地址:https://angelkeepmoving.github.io/mixed-lingual-tts/index.htm
摘要
本文主要研究对象是Encoder-Decoder的TTS框架(如:Tacotron、DeepVoice等)。研究的主要问题是能否使用一种语言(中文)训练模型,完成合成多种语言(中英文)的目的。合成的质量考虑两个方面,合成的一句话中音色的一致性(不会出现奇怪的韵律和音色等)以及一句话中读音的自然度和清晰度(断句正确,读音清晰)。本文将实现一个这种跨语种合成的模型,并做一下实验及分析。
1 简介
1.1相关工作
早先的关于多语种合成的方法主要有:
(1)通过录制当人双语语料进行模型训练。
(2)共享HMM state,其状态映射同样是通过双语语料训练而得到。
(3)通过统一语言编码。
(4)通过统一音素。
1.2主要贡献
本文主要贡献如下:
(1)分析网络对音素表示的作用。
(2)speaker embedding对混合语句一致性的影响。
(3)phene embedding对合成语音的影响。
(4)单语言语种能否训练出多语种模型。
2 多语种TTS模型
2.1 多人平均模型
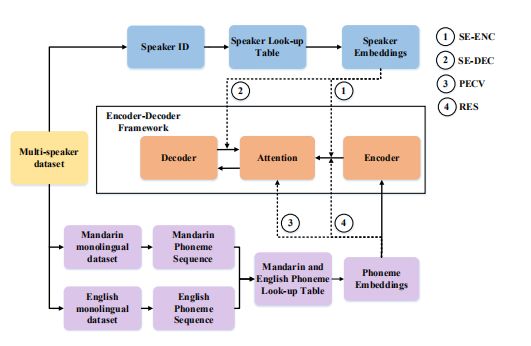
直接用单语种语料训练一个多语种合成模型是很困难的,所以本文用中文和英文混合语料训练了一个基础模型。在后面使用这种混合语料时,用字典法标出了speak embedding,但在分析phoneme embedding中,没有使用speaker embedding。
2.2 speaker Embedding
本文采用查表法使用speaker embedding(类似查数据库,一人有一条对应的embedding表示),speakerbedding与Encoder-Decoder网络联合进行训练(估计是类似expressive tacotron里面那样做)。由于speaker embedding所放的位置会影响最终合成语音的一致性(中英混读是是否像一个人的读音),本文采取两种策略进行对比实验,一种是放在Encoder的输出端,网络称为:SE-ENC,另外一种放在Decoder的输入端,网络称为:SE-DEC(其实类似做法百度和谷歌的相关项目都做过)。后面实验表明SE-DEC效果更好。
2.3 Phoneme Embedding


本文还研究了phoneme embedding对于最终合成语音自然度的影响。图1显示了原始的phoneme embedding结果,其中小写的是中文音素,大写的是英文音素。原始的中英文音素分布比较散乱,没有明显的区分度。图2显示了经过Encoder网络后的phoneme embedding聚类结果,显示出明显的区分度。作者猜测这可能是由于Encoder网络的输出受Decoder网络中的语音反馈影响以及对齐错误导致。
2.4 Phoneme-informed attention
根据2.3的分析,本文对研究了两种方式的phoneme embedding对注意力的影响。一种是给phoneme embedding加权重,使用了类似注意力机制的方法。 其部分基础公式如下,具体看论文:

另外一种就是做一个ResNet,将phoneme attention embedding加到encoder output中(实验证明resnet效果更好)。如下图:

3 实验及分析
3.1实验设置
本文仅对女说话人进行实验,采用了35个中文女声,35个英文女声,中文女声每人大概500句,总共大概17197句,大概17小时数据,英文用的vctk里面的35个女声数据,总共14464句,大概8小时数据。我觉得这里数据可能有点失衡,中英文语料数量差别有点大,不过TTS语料的确是贵,英文开源的好语料(录音棚级别)基本没有。
音频采样一致使用24KHz,提取mel谱维度为80,线性谱维度1024。声码器使用griffin-lim。
3.2 实验分析
评估方法,AB偏好。即给AB两句话,人工评估A好、B好还是差不多。评估人数18人,每种语料句子数30句(A、B各30句)。
3.2.1 SE-ENC与SE-DEC比较

3.2.2 SE-DEC 与 Re-Train AVM
SE-DEC与重训练AVM模型(先训练平均模型,再用目标人单人数据继续训练)比对。

3.2.3 训练数据的选择
比对不同数据集对最终模型的影响,本文三个数据集:(1)中文数据集:(CORPUS-MAN。(2)英文数据集:CORPUS-ENG;混合数据集:CORPUS-MIX。



3.2.4 phoneme embedding的使用
phoneme embedding一种为加权法,网络为:SE-DEC-PECV,另外一种为残差法,名称为:SE-DEC-RES。

另外,还对比了SE-DEC-RES和没加RES的SE-DNC。

4 总结
总结大概有以下几点:
(1)多人平均模型对最终模型有好处,且平均模型训练数据包含最终目标人数据更好。
(2)speaker embedding对语音一致性比较重要,同时speaker embedding的输入位置对结果也有影响,放在Decoder输入端效果优于放在Encoder输出端。
(3)虽然单语种语料可以训练出跨语种合成模型,但是有双语种语料更好。
(4)phoneme attention信息对合成语音的一致性及自然度都有好处。
另外,单语言训练的模型在混合语料的合成音上,有明显的过度音,效果不佳。
5 参考文献
[1] C. Traber, K. Huber, K. Nedir, B. Pfifister, E. Keller, and B. Zell
ner, “From multilingual to polyglot speech synthesis,” in Sixth
European Conference on Speech Communication and Technology,
1999.
[2] J. Latorre, K. Iwano, and S. Furui, “Polyglot synthesis using a
mixture of monolingual corpora,” in Proceedings.(ICASSP’05).
IEEE International Conference on Acoustics, Speech, and Signal
Processing, 2005., vol. 1. IEEE, 2005, pp. I–1.
[3] H. Liang, Y. Qian, and F. K. Soong, “An HMM-based bilingual
(Mandarin-English) TTS,” Proceedings of SSW6, 2007.
[4] Y. Qian, H. Cao, and F. K. Soong, “HMM-based mixed-language
(Mandarin-English) speech synthesis,” in 2008 6th International
Symposium on Chinese Spoken Language Processing. IEEE,
2008, pp. 1–4.
[5] Y. Qian, H. Liang, and F. K. Soong, “A cross-language state shar
ing and mapping approach to bilingual (Mandarin–English) TTS,”
IEEE Transactions on Audio, Speech, and Language Processing,
vol. 17, no. 6, pp. 1231–1239, 2009.
[6] J. He, Y. Qian, F. K. Soong, and S. Zhao, “Turning a mono
lingual speaker into multilingual for a mixed-language TTS,” in
Thirteenth Annual Conference of the International Speech Com
munication Association, 2012.
[7] B. Ramani, M. A. Jeeva, P. Vijayalakshmi, and T. Nagarajan,
“Voice conversion-based multilingual to polyglot speech synthe
sizer for Indian languages,” in 2013 IEEE International Confer
ence of IEEE Region 10 (TENCON 2013). IEEE, 2013, pp. 1–4.
[8] S. Sitaram and A. W. Black, “Speech synthesis of code-mixed
text.” in LREC, 2016.
[9] S. Sitaram, S. K. Rallabandi, S. Rijhwani, and A. W. Black, “Ex
periments with cross-lingual systems for synthesis of code-mixed
text.” in SSW, 2016, pp. 76–81.
[10] K. R. Chandu, S. K. Rallabandi, S. Sitaram, and A. W. Black,
“Speech synthesis for mixed-language navigation instructions.” in
INTERSPEECH, 2017, pp. 57–61.
[11] F.-L. Xie, F. K. Soong, and H. Li, “A KL divergence and DNN
approach to cross-lingual TTS,” in 2016 IEEE International Con
ference on Acoustics, Speech and Signal Processing (ICASSP).
IEEE, 2016, pp. 5515–5519.[12] B. Li, Y. Zhang, T. Sainath, Y. Wu, and W. Chan, “Bytes are all
you need: End-to-end multilingual speech recognition and syn
thesis with bytes,” arXiv preprint arXiv:1811.09021, 2018.
[13] S. Arik, J. Chen, K. Peng, W. Ping, and Y. Zhou, “Neural voice
cloning with a few samples,” in Advances in Neural Information
Processing Systems, 2018, pp. 10 019–10 029.
[14] E. Nachmani, A. Polyak, Y. Taigman, and L. Wolf, “Fitting new
speakers based on a short untranscribed sample,” arXiv preprint
arXiv:1802.06984, 2018.
[15] Y. Jia, Y. Zhang, R. Weiss, Q. Wang, J. Shen, F. Ren, P. Nguyen,
R. Pang, I. L. Moreno, Y. Wu et al., “Transfer learning from
speaker verifification to multispeaker text-to-speech synthesis,” in
Advances in Neural Information Processing Systems, 2018, pp.
4480–4490.
[16] Y. Taigman, L. Wolf, A. Polyak, and E. Nachmani, “Voiceloop:
Voice fifitting and synthesis via a phonological loop,” arXiv
preprint arXiv:1707.06588, 2017.
[17] A. Gibiansky, S. Arik, G. Diamos, J. Miller, K. Peng, W. Ping,
J. Raiman, and Y. Zhou, “Deep voice 2: Multi-speaker neural text
to-speech,” in Advances in neural information processing systems,
2017, pp. 2962–2970.
[18] W. Ping, K. Peng, A. Gibiansky, S. O. Arik, A. Kannan,
S. Narang, J. Raiman, and J. Miller, “Deep voice 3: 2000-speaker
neural text-to-speech,” Proc. ICLR, 2018.
[19] C. Li, X. Ma, B. Jiang, X. Li, X. Zhang, X. Liu, Y. Cao, A. Kan
nan, and Z. Zhu, “Deep speaker: an end-to-end neural speaker
embedding system,” arXiv preprint arXiv:1705.02304, 2017.
[20] R. J. Skerry-Ryan, E. Battenberg, X. Ying, Y. Wang, and R. A.
Saurous, “Towards end-to-end prosody transfer for expressive
speech synthesis with tacotron,” 2018.
[21] D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine trans
lation by jointly learning to align and translate,” arXiv preprint
arXiv:1409.0473, 2014.
[22] C. Veaux, J. Yamagishi, K. MacDonald et al., “Superseded-CSTR
VCTK corpus: English multi-speaker corpus for CSTR voice
cloning toolkit,” 2016.
[23] J. Shen, R. Pang, R. J. Weiss, M. Schuster, N. Jaitly, Z. Yang,
Z. Chen, Y. Zhang, Y. Wang, R. Skerrv-Ryan et al., “Natural
TTS synthesis by conditioning wavenet on mel spectrogram pre
dictions,” in 2018 IEEE International Conference on Acoustics,
Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 4779–
4783.
[24] D. Griffifin and J. Lim, “Signal estimation from modifified short
time fourier transform,” IEEE Transactions on Acoustics, Speech,
and Signal Processing, vol. 32, no. 2, pp. 236–243, 1984.
[25] Y. Wang, R. Skerry-Ryan, D. Stanton, Y. Wu, R. J. Weiss,
N. Jaitly, Z. Yang, Y. Xiao, Z. Chen, S. Bengio et al.,
“Tacotron: Towards end-to-end speech synthesis,” arXiv preprint
arXiv:1703.10135, 2017.