hive表
一、hive表抽取过程
1.抽取到hdfs成功后,就可以连接hive,创建外表了
建立外表
beeline -u jdbc:hive2://192.168.186.14:10010/default -n hdfs
CREATE external TABLE nj12345.case_info_ex(CASE_SERIAL STRING, CASE_TITLE STRING, CASE_REGISTER STRING, CASE_REGISTERNO STRING, CASE_DATE STRING, CASE_SOURCE STRING, CASE_SOURCE_DETAIL STRING, PHONE_NUMBER STRING, APPLICANT_NAME STRING, APPLICANT_SEX STRING, APPLICANT_AGE STRING, APPLICANT_ID STRING, CASE_TYPE STRING, CASE_ACCORD STRING, CASE_CONTENT STRING, CASE_PROCESS_TYPE STRING, CASE_ISPUBLIC STRING, CASE_ISVISIT STRING, CASE_ISURGENT STRING, CASE_MARK STRING, AREA_CODE STRING, CASE_SERIAL_TURN STRING, TSIGNTIME_BF STRING, TFDBACKTIME_BF STRING, TBACKTIME_BF STRING, RELATE_SERIAL STRING, ROWGUID STRING, OPERATEDATE STRING, CASE_AREA_CODE STRING)row format DELIMITED FIELDS terminated by '\t' location '/tmp/nj12345/case_info/';
2.然后就可以进行查询了,如果想对hive数据进行增删改,那么需要将数据导入到事务表中
建立事务表
CREATE TABLE nj12345.case_info(CASE_SERIAL STRING, CASE_TITLE STRING, CASE_REGISTER STRING, CASE_REGISTERNO STRING, CASE_DATE STRING, CASE_SOURCE STRING, CASE_SOURCE_DETAIL STRING, PHONE_NUMBER STRING, APPLICANT_NAME STRING, APPLICANT_SEX STRING, APPLICANT_AGE STRING, APPLICANT_ID STRING, CASE_TYPE STRING, CASE_ACCORD STRING, CASE_CONTENT STRING, CASE_PROCESS_TYPE STRING, CASE_ISPUBLIC STRING, CASE_ISVISIT STRING, CASE_ISURGENT STRING, CASE_MARK STRING, AREA_CODE STRING, CASE_SERIAL_TURN STRING, TSIGNTIME_BF STRING, TFDBACKTIME_BF STRING, TBACKTIME_BF STRING, RELATE_SERIAL STRING, ROWGUID STRING, OPERATEDATE STRING, CASE_AREA_CODE STRING)
clustered by (`CASE_SERIAL`) into 250 buckets STORED AS ORC;
3.外表数据导入到事务表
insert insto orc事务表 select * from 外表;
注意坑:
UPDATE case_result_info SET FINISH_NOTE= REPLACE(REPLACE(FINISH_NOTE, CHAR(10), ''), CHAR(13), '');
如果表中字段中含有换行符,那么不好意思,用上面语句把该字段中的换行符替换掉,再进行HDFS抽取。
二、分桶表
桶表是对数据进行哈希取值,然后放到不同文件中存储
创建一个桶表
create table bucket_table(id int,name string) clustered by(id) into 4 buckets;
加载数据
set hive.enforce.bucketing = true;
insert into table bucket_table select name from stu;
insert overwrite table bucket_table select name from stu;
PS:数据加载到桶表时,会对字段取hash值,然后与桶的数量取模。把数据放到对应的文件中。
三、分区表
Partition 对应于数据库的 Partition 列的密集索引
在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中
- 例如:
-
test表中包含 date 和 city 两个 Partition
则对应于date=20130201, city = bj 的 HDFS 子目录为:
/warehouse/test/date=20130201/city=bj
对应于date=20130202, city=sh 的HDFS 子目录为;
/warehouse/test/date=20130202/city=sh
创建表
create table partition_table(id int,name string) partitioned by(age int,high int);
alter table partition_table add partition (age=20,high=180);
insert into hive_test.partition_table PARTITION (age,high) values (1,'xubin',20,180);
insert overwrite table partition_table partition (age=20,high=180) select id,name from external_table where age =20 and high = 180;
insert overwrite table partition_table partition (age=21,high=180) select id,name from external_table where age =21 and high = 180;
四、ETL抽取
操作步骤
1.建立外表
CREATE external TABLE t_rk_baseinfo_5kwexternal
(
ROW_ID STRING, SYNC_SIGN STRING, SYNC_ERROR_DESC STRING, OperateType STRING, SYNC_Date STRING, XiaQuCode STRING, Name STRING, NameEN STRING, NameUsed STRING, Sex STRING, Nation STRING, Birthday STRING, BirthPlace STRING, Age STRING, Native STRING, Nationality STRING, IdcardType STRING, Idcard STRING, IdcardBeginDate STRING, IdcardEndDate STRING, Political STRING, MaritalStatus STRING, Faith STRING, MilitaryService STRING, Height STRING, Weight STRING, BloodType STRING, Mobile STRING, Telephone STRING, RegionAddress STRING, Address STRING, PostCode STRING, EMail STRING, Health STRING, FamliyDiseaseHis STRING, IdDeath STRING, DeathDate STRING, Type STRING, PersonGuid STRING, HabCode STRING, AgeArea STRING, HouseholdType STRING, Education STRING, baidulat STRING, baidulng STRING)
row format delimited fields terminated by ‘\t’;
;
2.文件抽取至HDFS



3.创建事务表
clustered by (ROW_ID) into 3 buckets
stored as orc TBLPROPERTIES (‘transactional’=‘true’);
备用:LOAD DATA INPATH ‘/path/to/local/files’ into table t_rk_baseinfo;
4.hdfs到外表
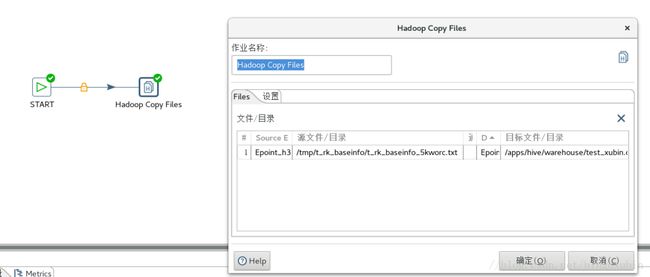
5.外表到事务表
insert into 事务表 select * from 外表;
四、手动到tdh
1.访问星环客户端,下载TDH_Client压缩包
2.到该目录,解压压缩包,./init.sh
3.source init.sh
4.输入export HADOOP_USER_NAME=hdfs
5.导入oracle的驱动包到/opt/TDH_Client/sqoop/lib下
6.sqoop import --connect “jdbc:oracle:thin:@192.168.186.36:1521/ORCL” --username epoint --password 11111 --target-dir /data/sqoop/bo_user/CAR_HAILING2 -m 1 --query “select * from CAR_HAILING2 where $CONDITIONS” --fields-terminated-by “\001” --hive-drop-import-delims --null-string ‘\N’ --null-non-string ‘\N’ --outdir /tmp/sqoop_jar
7.create external table if not exists EX.ex_CAR_HAILING2 (TIME STRING,PLATE_NUM STRING,
DETECTOR_NUM STRING
) row format DELIMITED FIELDS terminated by ‘\001’ stored as textfile location ‘/data/sqoop/bo_user/CAR_HAILING2’;
8.create table if not exists CAR_HAILING2 (TIME STRING,PLATE_NUM STRING,
DETECTOR_NUM STRING
) clustered by (TIME) into 250 buckets STORED AS ORC 每个桶大概200M,所以22G数据,设置110个桶,如果是ORC事务表,每个桶不超过100M,设置为250
9.INSERT INTO DEFAULT.CAR_HAILING2 SELECT * FROM ex.CAR_HAILING2
五、orc文件读取
支持增删改查建表:
create table orc_table(id int, name string) clustered by (id) into 4 buckets stored as orc
TBLPROPERTIES ('transactional'='true');
区分:
create table orc_table_asorc (id int,name string) stored as orc;
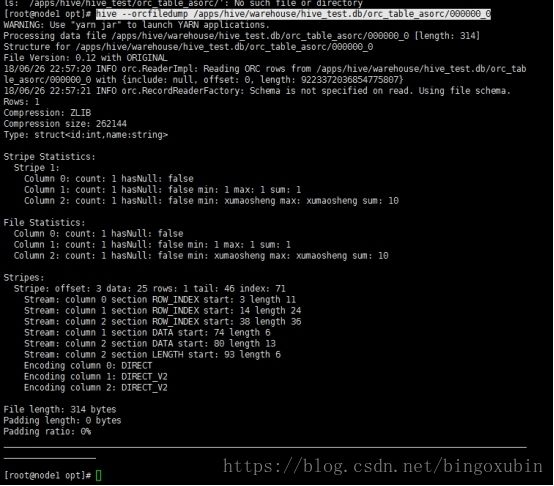
读取orc文件命令:
hive存储为orc时,orc格式正常无法打开访问,是乱码,需通过命令行的方式查看:
hive --orcfiledump /apps/hive/warehouse/hive_test.db/orc_table_asorc/000000_0
六、blob处理
package epoint.mppdb_01.h3c;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import java.sql.Blob;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import org.apache.commons.net.ftp.FTPClient;
import org.apache.commons.net.ftp.FTPReply;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class MySQLblobToMPPphoto {
// MySQL连接
public static Connection getMySQLConnection() throws Exception {
String MySQLDRIVER = "com.mysql.jdbc.Driver";
String MySQLURL = "jdbc:mysql://192.168.186.13:3306/bigdata_scene03_rktj";
String MySQLUSERNAME = "root";
String MySQLPASSWORD = "Gepoint";
Connection MySQLconn = DriverManager.getConnection(MySQLURL, MySQLUSERNAME, MySQLPASSWORD);
return MySQLconn;
}
// MPP连接
public static Connection getMPPConnection() throws Exception {
String MPPDRIVER = "com.MPP.jdbc.Driver";
String MPPURL = "jdbc:MPP://192.168.186.14:5258/bigdata_scene03_rktj";
String MPPUSERNAME = "mpp";
String MPPPASSWORD = "h3c";
Connection MPPconn = DriverManager.getConnection(MPPURL, MPPUSERNAME, MPPPASSWORD);
return MPPconn;
}
//
public static void getMySQLblobToHDFS() throws Exception {
Connection conn = getMySQLConnection();
ResultSet rs = null;
try {
String sql = "select ROW_ID,photo from t_rk_baseinfo_blob limit 10";
Statement prest = conn.prepareStatement(sql);
rs = prest.executeQuery(sql);
while (rs.next()) {
int row_id = rs.getInt(1);
Blob photo = rs.getBlob(2);
System.out.println(row_id + " " + photo);
InputStream in = photo.getBinaryStream();
OutputStream out = new FileOutputStream("H:/photo/" + row_id + ".jpg");
int len = 0;
byte[] buffer = new byte[1024];
while ((len = in.read(buffer)) != -1) {
out.write(buffer, 0, len);
}
upload("H:/photo/" + row_id + ".jpg");
}
prest.close();
rs.close();
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关闭连接
if (conn != null) {
try {
conn.close();
conn = null;
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) throws Exception {
getMySQLblobToHDFS();
}
// HDFS附件上传
public static void upload(String uploadpath) throws Exception {
Configuration conf = new Configuration();
URI uri = new URI("hdfs://192.168.186.14:8020");
FileSystem fs = FileSystem.get(uri, conf, "HDFS");
Path resP = new Path(uploadpath);
Path destP = new Path("/photo");
if (!fs.exists(destP)) {
fs.mkdirs(destP);
}
fs.copyFromLocalFile(resP, destP);
fs.close();
System.out.println("***********************");
System.out.println("上传成功!");
}
// HDFS附件下载
public static void download() throws Exception {
Configuration conf = new Configuration();
String dest = "hdfs://192.168.186.14:/photo/11.png";
String local = "D://11.png";
FileSystem fs = FileSystem.get(URI.create(dest), conf, "hdfs");
FSDataInputStream fsdi = fs.open(new Path(dest));
OutputStream output = new FileOutputStream(local);
IOUtils.copyBytes(fsdi, output, 4096, true);
System.out.println("***********************");
System.out.println("下载成功!");
}
}