大数据学习之Linux基础
大数据学习之Linux基础
- 自定义Linux虚拟机安装
- 网络配置
- 1.node1网络配置
- 2.通过快照克隆虚拟机
- 3.配置其他三个节点虚拟机
- Linux简单命令
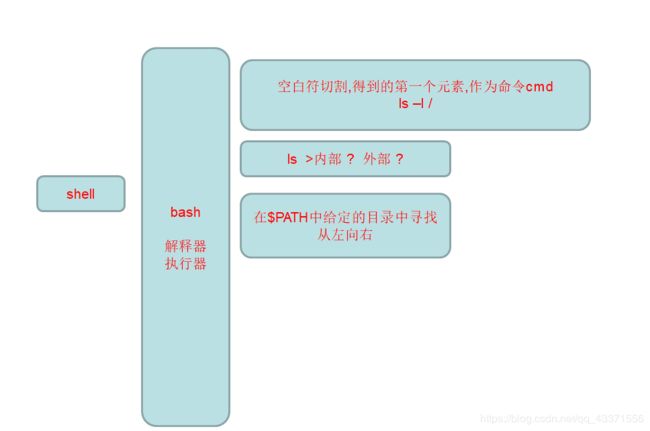
- shell命令运行原理图
- 1.关机与重启
- 2.判断命令的命令
- 3.常用功能命令
- 4.文件系统命令
- 文件系统层次化标准(File System Hierarchy Standard)
- 5.文本操作命令
- vi全屏文本编辑器
- 全屏编辑器模式
- 1.打开文件
- 2.关闭文件
- 3.编辑模式
- 4.末行模式
- 正则表达式
- 基本语法
- 举例1
- 举例2
- 文本处理命令
- cut命令(文本切分)
- sort命令(文本排序)
- wc命令: 统计数目
- 学习命令技巧:通过 `man 具体命令` 查询该命令如何使用
- 行编辑器
- sed 命令
- 通过正则式匹配 IP 地址,并替换最后的主机号
- awk 命令(文本分析工具命令)
- 统计报表:合计每人1月工资,0:manager,1:worker
- 用户与权限
- 用户组操作
- linux角色权限必会知识
- 权限操作
- Linux软件安装
- 编译安装
- rpm安装
- 小技巧 : 见到别人的命令很好用,自己如何安装
- yum安装
- 基本命令
- 阿里云CentOS的yum源
- 本地 yum 源
- 中文显示,查看帮助中文文档
- 中文显示
- 中文帮助文档设置
- 文本流和重定向
- 重定向
- shell 脚本编程
- Bash
- 含有shell命令的文件三种运行方式
- 变量
- 引用
- 表达式
- 编写shell 脚本案例——添加用户脚本
- 逻辑判断
- 流程控制
- if选择语句
- while循环语句
- for循环语句
- 编写shell 脚本案例——判断目录下最大文件
- 编写shell 脚本案例——递归子目录
自定义Linux虚拟机安装
点击新建虚拟机

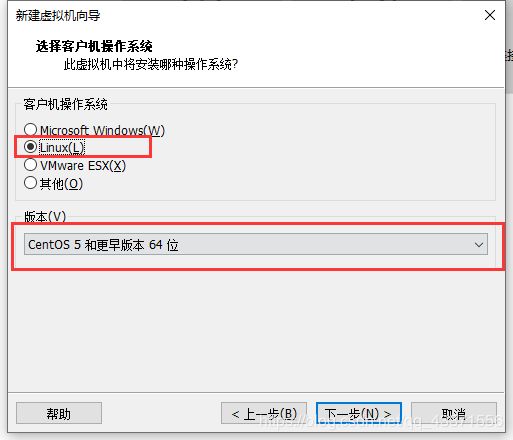
如果c盘有ssd,建议将虚拟机安装在c盘, 因为这样安装以后打开虚拟机更快.
同时, 建议新建一个目录, 来存放虚拟机
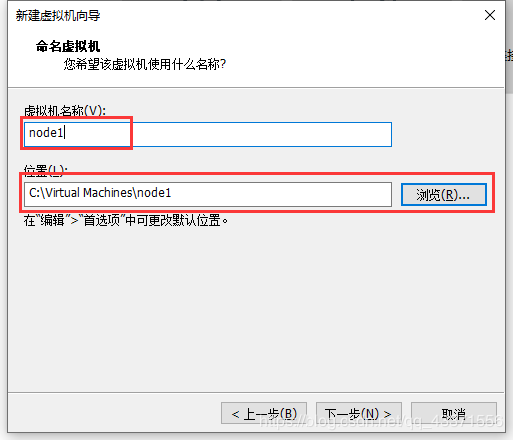

这里建议虚拟机的内存至少为 1024 MB


这里建议在100GB以上, 因为要跑大数据 .
但是我们需要明白的是在这里填100GB本地磁盘不会马上为虚拟机磁盘分配那么大的内存空间,
而是规定了虚拟机磁盘能使用c盘的最大容量, 以备不时之需
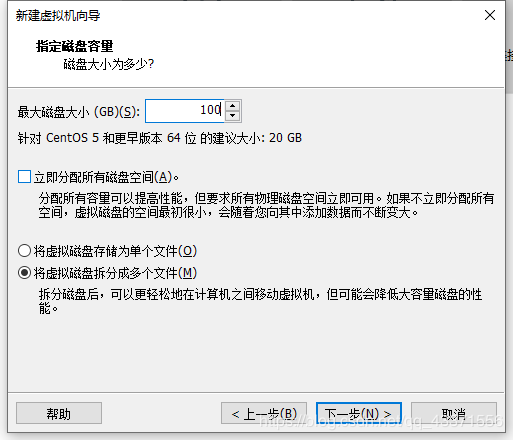
虚拟机磁盘文件存放目录
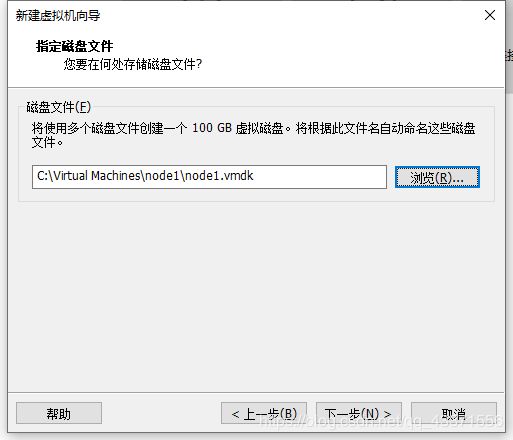

指定光盘映像文件, 已分享至百度云
链接:https://pan.baidu.com/s/1AVY_tOEbL-TYGJ7cpQ0eIw
提取码:md77
复制这段内容后打开百度网盘手机App,操作更方便哦
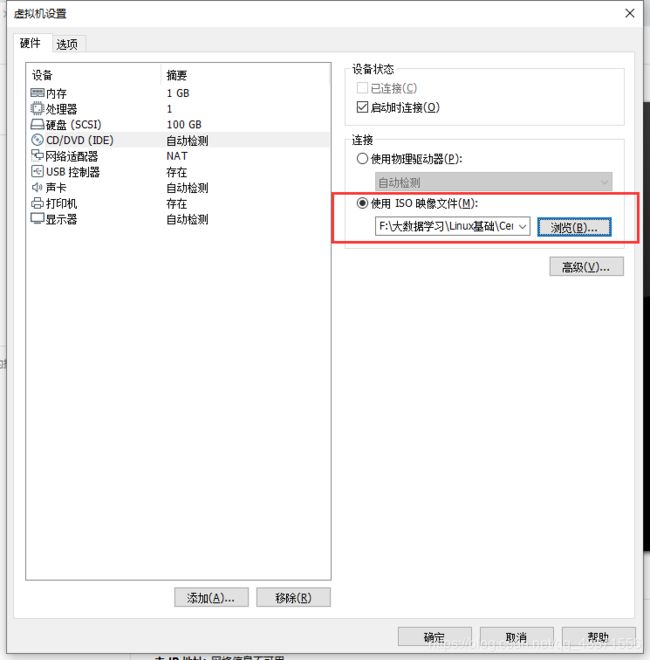
注意:
Linux 版本根据自己的Linux 版本选择。列如:我这用的是 CentOS-6.5-x86_64-minimal.iso,
所以选择 Linux 版本时选择时 Centos 64位
添加 ISO 镜像文件,之后开启虚拟机即可
等待初始化页面加载完成
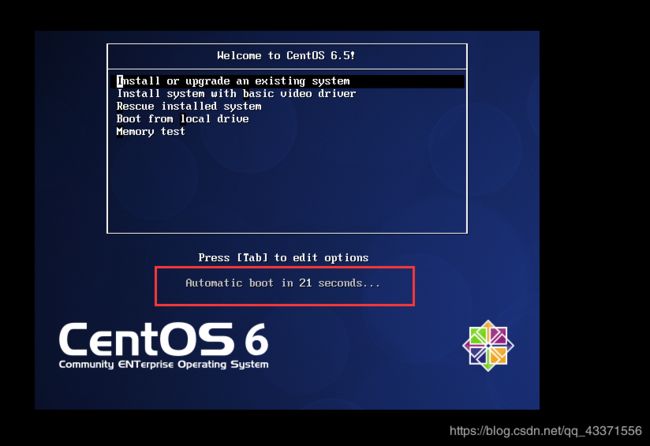
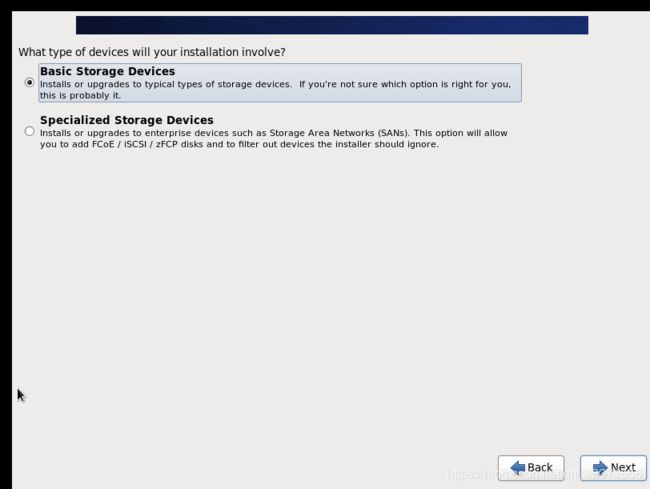
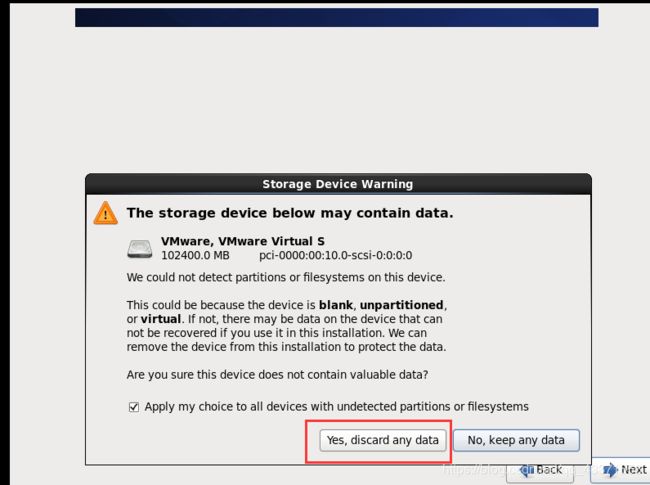
虚拟机安装配置(若特殊说明,则选择继续/OK/Next即可)
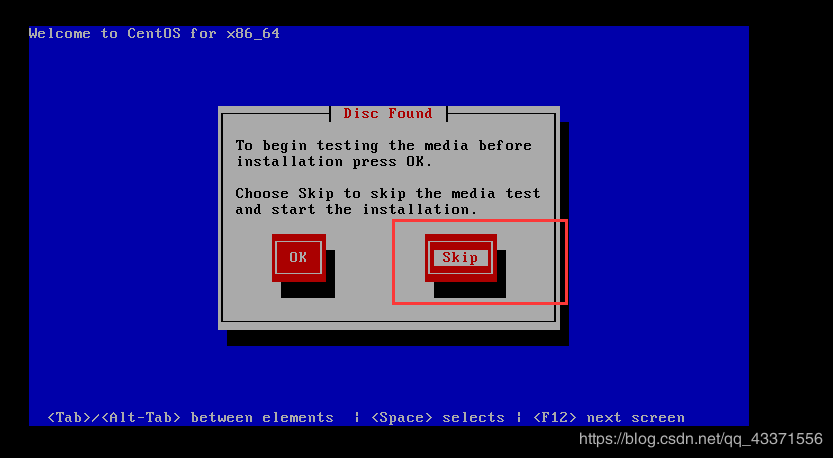
跳过磁盘检查,否则磁盘检查时间会很长(通过键盘的左右键+回车确定)
语言建议选择英文

时区选择, 建议选择 亚洲/上海,在这里选择了时区虚拟机中的时间就会和我们现在的时间同步
会为我们以后带来极大的便利,相信我这个过来人!!!

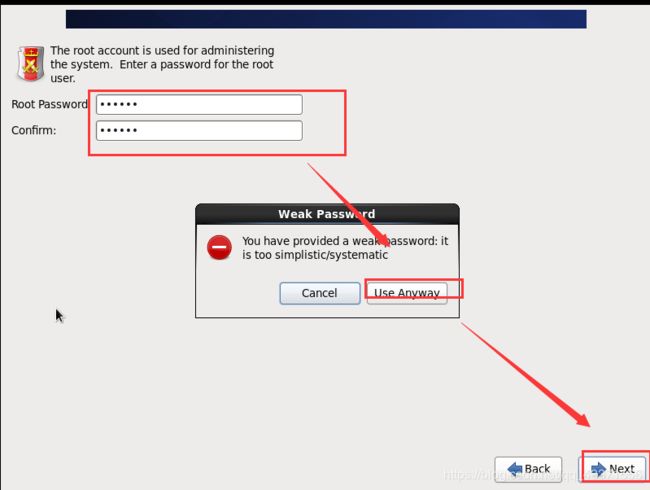
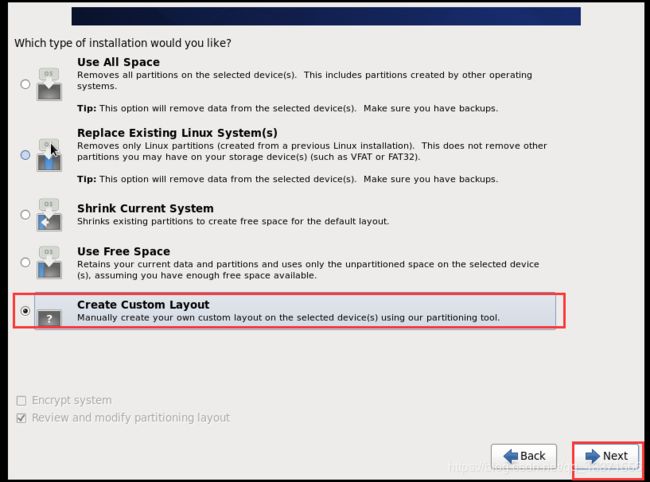
进行磁盘分区, 这里要进行三个分区
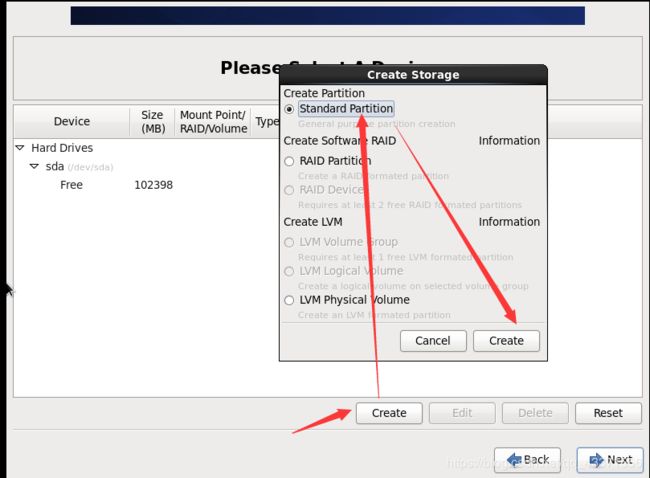
创建第一个分区
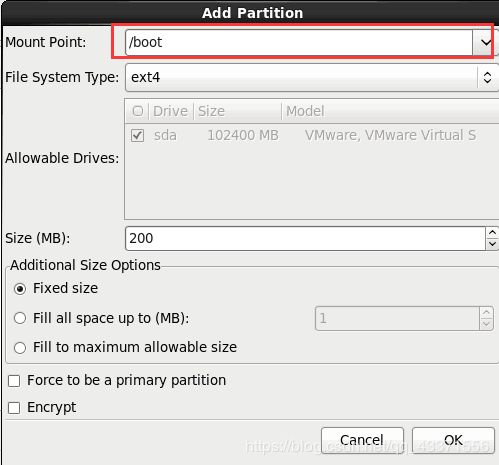
创建第二个分区
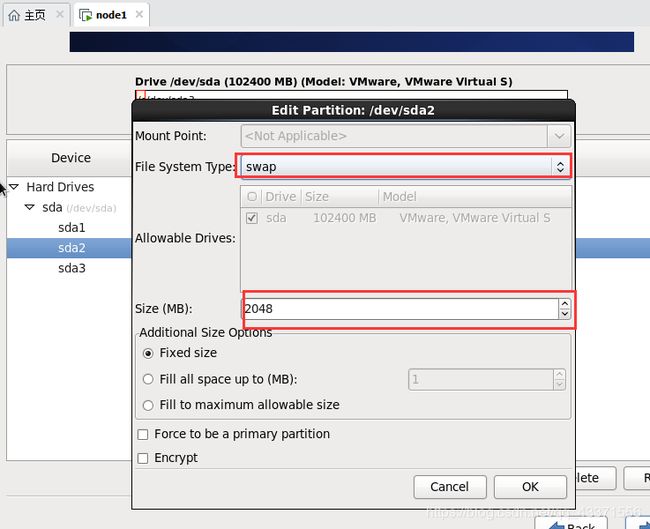
创建第三个分区
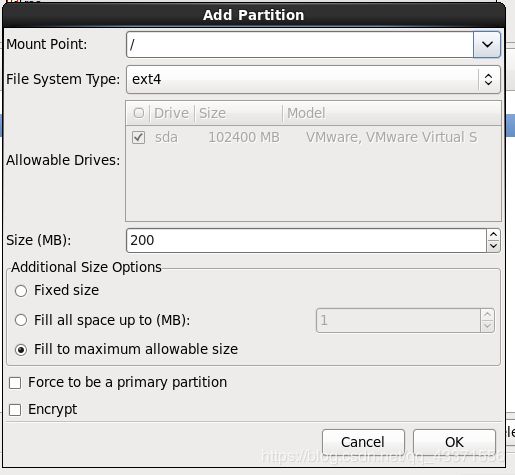
三个分区配置好以后,效果如下,点击next
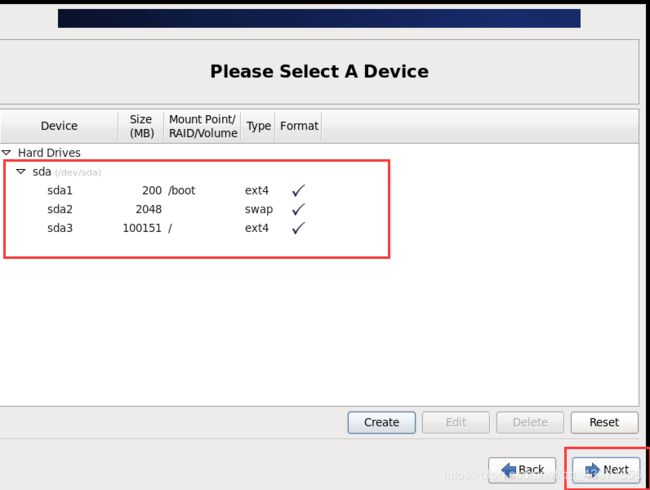
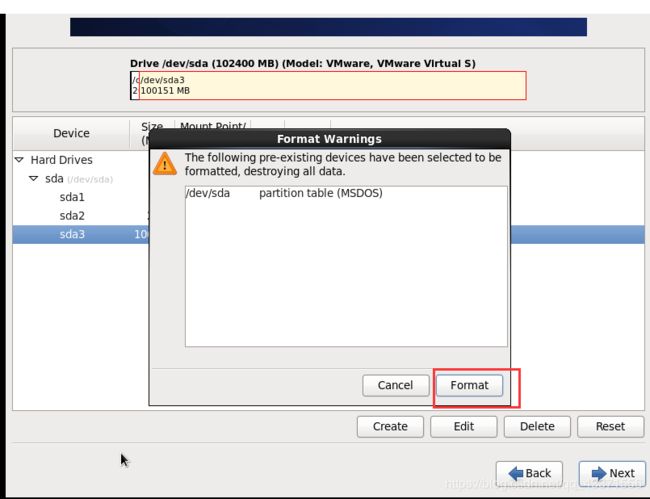
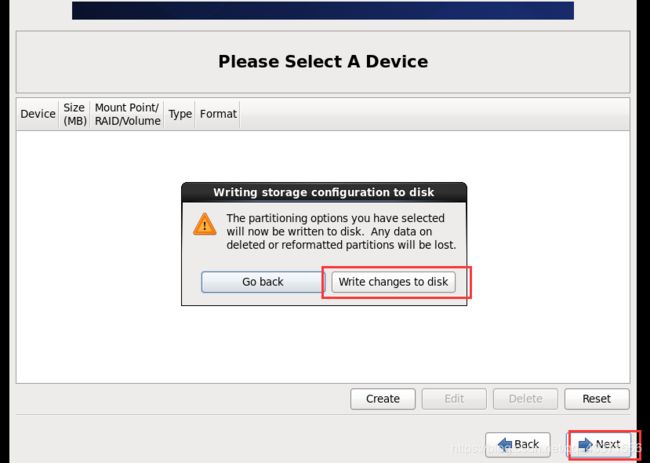
文件下载完毕后继续Next
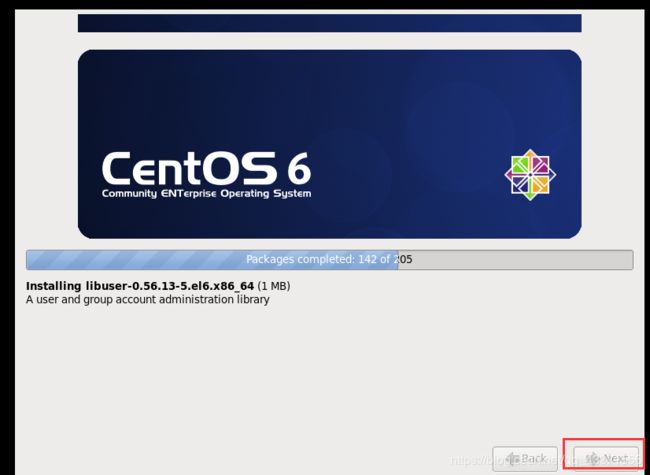
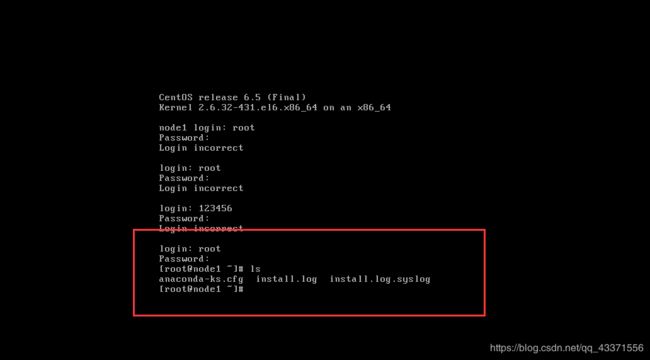
重启, 然后输入用户名密码, 输入ls后出现下面三个文件代表安装成功
网络配置
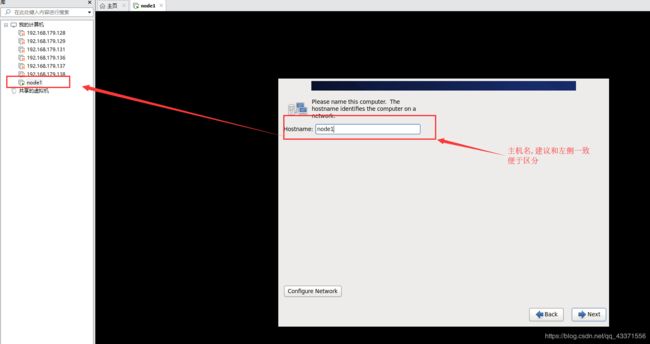
1.node1网络配置
.配置静态IP
vi /etc/sysconfig/network-scripts/ifcfg-eth0
编辑内容
# ifcfg-eth0 网卡配置,使用打开后编辑,
# ONBOOT=on 开机自启
# BOOTPROTO=static 表示 IP 使用静态IP
DEVICE=eth0
TYPE=Ethernet
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.179.140 #这里需要根据自己的网段填写
NETMASK=255.255.255.0
GATEWAY=192.168.170.2
DNS1=144.144.144.144
DNS2=8.8.8.8
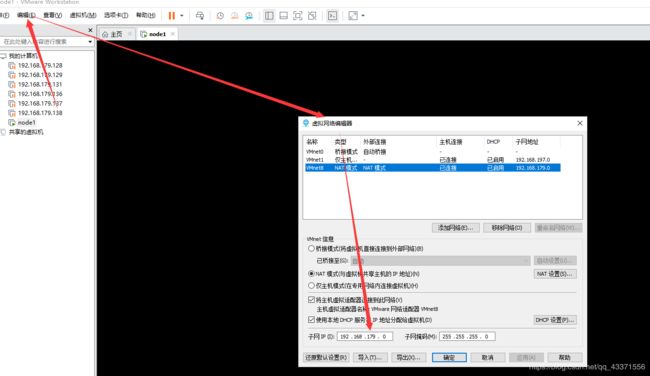
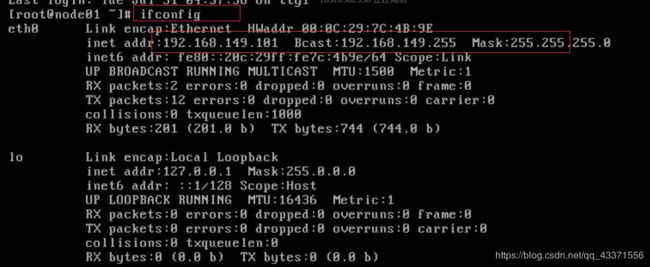
查看网段 由下图可以看出我的网段为 192.168.179.0
因此可以在 192.168.179.3-192.168.179.254 之间进行配置
删除mac地址映射文件
cd /etc/udev/rules.d
rm 70-persistent-net.rules -f
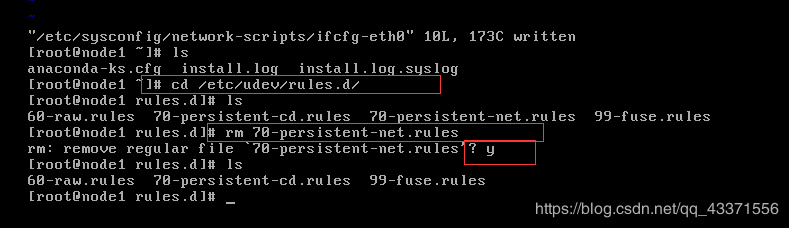
查看自己的ip配置是否正常
ifconfig
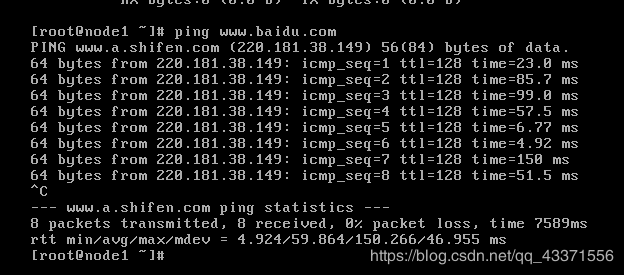
最后ping一下百度
2.通过快照克隆虚拟机
关闭虚拟机poweroff,创建快照
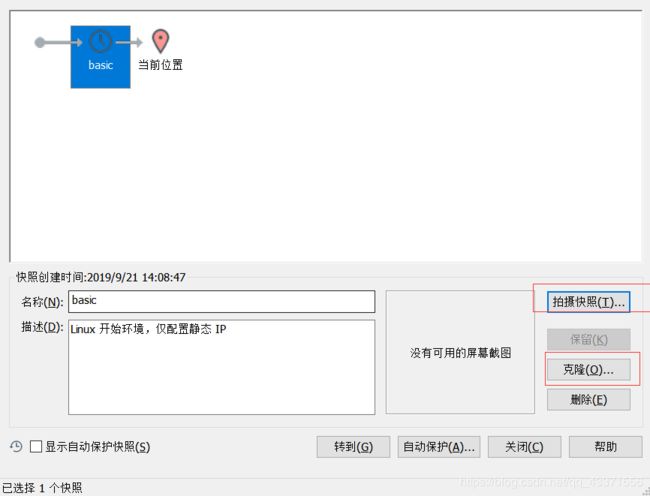
通过快照克隆虚拟机
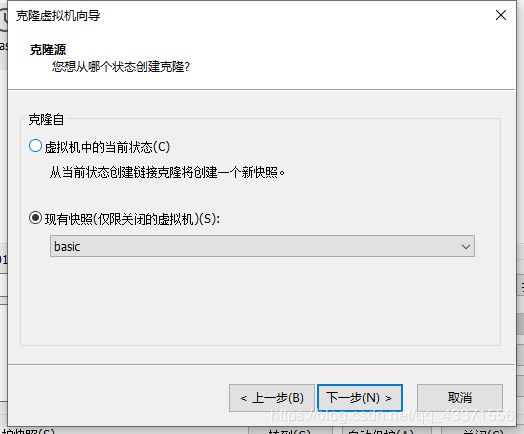
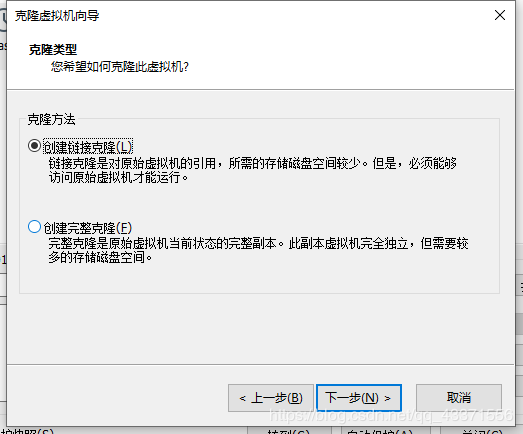
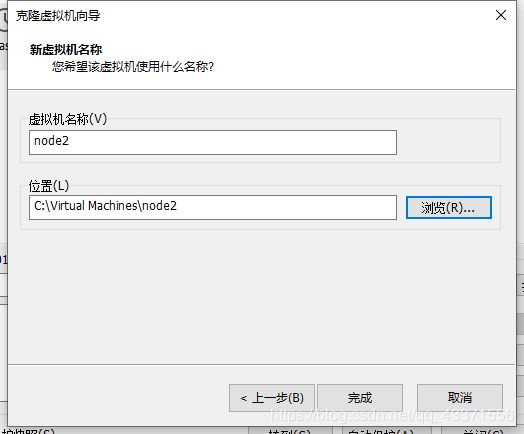
这样以次再创建两个,一共四个
克隆后的文件完全一样, 也就是说登陆账号和密码也同我们第一个虚拟机一样
3.配置其他三个节点虚拟机
1.修改每台虚拟机的ip(ip地址依次+1),
2.删除mac映射文件(.rules文件 ,如图1),
3.修改主机名( vi /etc/sysconfig/network ) ,重启令其生效即可(图2)
注意 : 阿里云服务器修改主机名 hostnamectl set-hostname 主机名 ,然后重启即可
图1
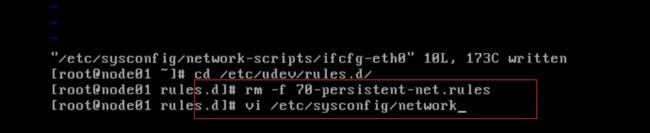
图2: 修改主机名(依次为node2,node3,node4)

Linux简单命令
shell命令运行原理图
1.关机与重启
| 名称 | 命令 |
|---|---|
| 关机 | poweroff / init 0 |
| 重启 | reboot / init 6 |
2.判断命令的命令
type 具体命令:命令类型(外部命令 & 内部命令)
help:内部命令帮助 help:内部命令清单,附带语法格式,描述
help 具体内部命令 具体命令的介绍
man 具体命令 :帮助手册manual,比help更加强大( yum install man man-pages -y )
whereis 具体命令 : 定位命令位置
file 具体文件:查看文件详细信息 (ELF 表示二进制文件)
echo:打印到标准输出; $PATH: 环境变量:路径,$LANG 语言

3.常用功能命令
ls 显示目录内容 ll --i
pwd 显示当前目录的绝对路径
cd 切换目录
mkdir 文件夹 -p {}
cp 复制 -r
mv 移动
touch 创建文件夹、文件
type 命令名 查看指定命令的文件的存放位置 外部命令 & 内部命令
cat 查看文件内容
ps -fe 进程列表( 分析ps命令type ps man ps)
echo $$ 当前shell的PID
4.文件系统命令
df -h :查看磁盘分区
mount/unmout 挂载/卸载磁盘文件

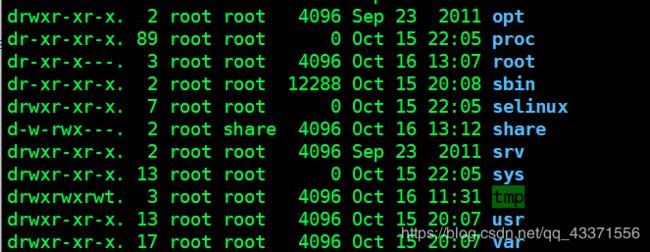
文件系统层次化标准(File System Hierarchy Standard)
位于linux根目录下, 可以直接访问 eg: cd /root,cd /var
| 文件名 | 作用 |
|---|---|
| /boot | 系统启动相关的文件,如内核、initrd,以及grub(bootloader) |
| /dev | 设备文件 |
| /etc | 配置文件 |
| /home | 用户的家目录,每一个用户的家目录通常默认为/home/USERNAME |
| /root | 管理员的家目录 |
| /lib | 库文件 |
| /media | 挂载点目录,移动设备 |
| /mnt | 挂载点目录,额外的临时文件系统 |
| /opt | 可选目录,第三方程序的安装目录 |
| /proc | 伪文件系统,内核映射文件 |
| /tmp | 临时文件 |
| /var | 可变化的文件 |
| /bin | 可执行文件, 用户命令 |
| /sbin | 管理命令 |
系统启动必须:
/boot: 存放的启动Linux 时使用的内核文件,包括连接文件以及镜像文件。
/etc:存放所有的系统需要的配置文件和**子目录列表,**更改目录下的文件可能会导致系统不能启动。
/lib:存放基本代码库(比如c++库),其作用类似于Windows里的DLL文件。几乎所有的应用程序都需要用到这些共享库。
/sys: 这是linux2.6内核的一个很大的变化。该目录下安装了2.6内核中新出现的一个文件系统 sysfs 。sysfs文件系统集成了下面3种文件系统的信息:针对进程信息的proc文件系统、针对设备的devfs文件系统以及针对伪终端的devpts文件系统。该文件系统是内核设备树的一个直观反映。当一个内核对象被创建的时候,对应的文件和目录也在内核对象子系统中
指令集合:
/bin: 存放着最常用的程序和指令
/sbin: 只有系统管理员能使用的程序和指令。
外部文件管理:
/dev :Device(设备)的缩写, 存放的是Linux的外部设备。 注意:在Linux中访问设备和访问文件的方式是相同的。
/media:类windows的其他设备,**例如U盘、光驱等等,识别后linux会把设备放到这个目录下。
/mnt:临时挂载别的文件系统的,我们可以将光驱挂载在/mnt/上,然后进入该目录就可以查看光驱里的内容了。
临时文件:
/run:是一个临时文件系统,存储系统启动以来的信息。当系统重启时,这个目录下的文件应该被删掉或清除。如果你的系统上有 /var/run 目录,应该让它指向 run。
/lost+found:一般情况下为空的,系统非法关机后,这里就存放一些文件。
/tmp:这个目录是用来存放一些临时文件的。
账户:
/root:系统管理员的用户主目录。
/home:用户的主目录,以用户的账号命名的。
/usr:用户的很多应用程序和文件都放在这个目录下,类似于windows下的program files目录。
/usr/bin: 系统用户使用的应用程序与指令。
/usr/sbin: 超级用户使用的比较高级的管理程序和系统守护程序。
/usr/src: 内核源代码默认的放置目录。
运行过程中要用:
/var:存放经常修改的数据,比如程序运行的日志文件(/var/log 目录下)。
/proc:管理内存空间虚拟的目录,是系统内存的映射,我们可以直接访问这个目录来,获取系统信息。这个目录的内容不在硬盘上而是在内存里,我们也可以直接修改里面的某些文件来做修改。
扩展用的:
/opt:默认是空的,我们安装额外软件可以放在这个里面。
/srv:存放服务启动后需要提取的数据**(不用服务器就是空)**
5.文本操作命令
基本命令
| 命令 | 作用 |
|---|---|
| cat | 显示全部文本文件内容 |
| more | 逐页显示文本文件内容 |
| less | 一次性读取全部文件内容,相比more,可以往回看 |
| head | 显示前 n 行的内容 |
| tail | 显示后 n 行的内容 |
| |
管道 |
通过管道显示profile文件第6行的数( 可以在将来用于数据的读取 )

vi全屏文本编辑器
打开对 vim的支持
yum install -y vim
全屏编辑器模式
编辑模式:按键具有编辑文本功能:默认打开进入编辑模式
输入模式:按键本身意义
末行模式:接受用户命令输入
1.打开文件
vim /path/to/somefile
vim +# :打开文件,并定位于第#行
vim +:打开文件,定位至最后一行
vim +/PATTERN : 打开文件,定位至第一次被PATTERN匹配到的行的行首
2.关闭文件
末行模式
:q 退出 没有动过文件
:wq 保存并退出 动过了,不后悔
:q! 不保存并退出 动过了,后悔了
:w 保存
:w! 强行保存
:wq <==> :x
3.编辑模式
移动光标
字符
h: 左;j: 下;k: 上;l: 右
单词
w: 移至下一个单词的词首
e: 跳至当前或下一个单词的词尾
b: 跳至当前或前一个单词的词首
行内
0: 绝对行首
^: 行首的第一个非空白字符
$: 绝对行尾
行间
G:文章末尾
3G:第3行
gg:文章开头
翻屏
ctrl f (front上一页)
ctrl b (backend 下一页)
删除&替换单个字符
x:删除光标位置字符
3x:删除光标开始3个字符
r:替换光标位置字符
删除命令 :
d3 删除3行数据
dw 删除一个单词(delete word)
dd 删除一行
复制粘贴&剪切( p相当于粘贴键的作用 )
yw +p 复制一个单词
yy +p 复制一行数据
撤销&重做
u 撤销
ctrl+r 重做 撤销的操作
. 重复上一步的操作
4.末行模式
set:设置
set nu 显示行号
set nonu 隐藏行号
set readonly 设为只读
查找
:/after 查找和after相同的单词+n,N 跳到下一个
s查找并替换
# 语法
s/str1/str2/gi
#替换查找从当前光标处,到文件末尾处
eg: .,$s/str1/str2/gi
/:临近s命令的第一个字符为边界字符:/,@,#
g:当前行内全部替换(若没有选择,则替换当前行的第一个替换)
i:忽略大小写
范围
n:行号
.:当前光标行
+n:偏移n行
$:末尾行,$-3
%:全文
末行模式技巧
:Gd 清空内容
:.,$d 删除从当前光标到末尾所有行
:n,md 删除从第 n 行到 m 行的所有内容
:n,my 复制从第 n 行到 m 行的所有内容
正则表达式
基本语法
grep: 显示匹配行
v: 反显示
e: 使用扩展正则表达式(如果不不开启, 需要在 "(",")"等操作符前加反斜杠
匹配操作符
\ 转义字符
. 匹配任意单个字符
[1249a],[^12],[a-k] 字符序列单字符占位
^ 行首(在中括号外),在[^] 表示取反 eg: [^0-9] 第一个字符不为数字
$ 行尾
\<,\>:\<abc 单词首尾边界
| 连接操作符
(,) 选择操作符
\n 反向引用
重复操作符:
? 匹配0到1次
* 匹配0到多次
+ 匹配1到多次
{n} 匹配n次
{n,} 匹配n到多次
{n,m} 匹配n到m次
与扩展正则表达式的区别:grep basic
\?, \+, \{, \|, \(, and \)
匹配任意字符
.*
举例1
#在未扩展正则表达式时,若匹配规则中含有 ?,+,{,},|,(,) ,都需要通过 \ 转义,否则匹配不到
#查询a.txt中包括4位整数的行,
grep "\(^[0-9]\|[^0-9][0-9]\)[0-9]\{2\}\([0-9][^0-9]\|[0-9]$\)" a.txt
#查询文件a.txt中含有单词you的内容
grep "\" a.txt
举例2
#创建并编辑test文件
vim test
#文件内容
• aaabbcaaa
• aa bbc aaa
• bb bbc bbb
• asgodssgoodsssagodssgood
• asgodssgoodsssagoodssgod
• sdlkjflskdjf3slkdjfdksl
• slkdjf2lskdjfkldsjl
#查询含有a的行
grep "a" test
#a出现3次a的行
grep "a\{3\}" test
#以aaa开头的行
grep "\ test
#出现aaa这个单词行,而如果aaa代表单词,则它的前后需要有空格,即 空格aaa空格
grep "\" test
#出现b的行
grep "b" test
#出现b为2-3次的行
grep "b\{2,3\}" test
文本处理命令
cut命令(文本切分)
cut:显示切割的行数据
d:自定义分隔符
s:不显示没有分隔符的行
f:选择显示的列
显示被空格空格分隔后的列数为1-3的行数据
![]()
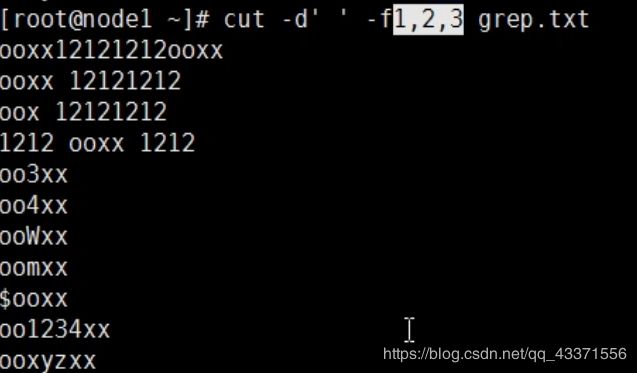
显示含有空格分隔符,1-3列的行数据,对上面命令的优化

通过冒号分隔, 获取分割后第一列的行数据
![]()
按照每一行的首字母排序

sort命令(文本排序)
sort:排序文件的行
n:按数值排序
r:倒序
t:自定义分隔符
k:选择排序列
u:合并相同行
f:忽略大小写
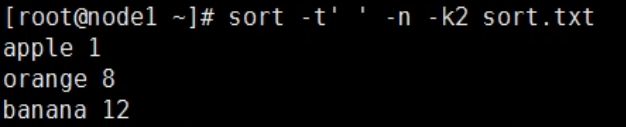
按空格分隔符分隔后第二列数据进行排序
(即对后面的数字进行排序,但是不是比较数值大小,只是单纯的比较第一个数字大小,相同然后进行下一位比较…依次类推)
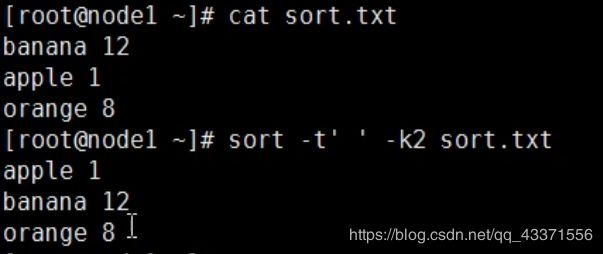
按空格分隔符分隔后第二列数据进行排序( 对数值排序, 对上一步的优化)
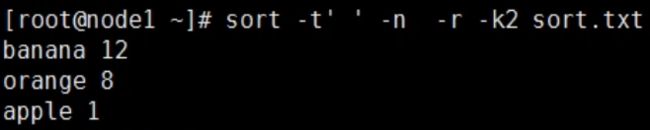
按空格分隔符分隔后第二列数据进行排序( 对数值进行倒序排序 )
wc命令: 统计数目
word count:包括行数, 单词数, 以及字节数(包括空格符)

学习命令技巧:通过 man 具体命令 查询该命令如何使用
eg: man wc
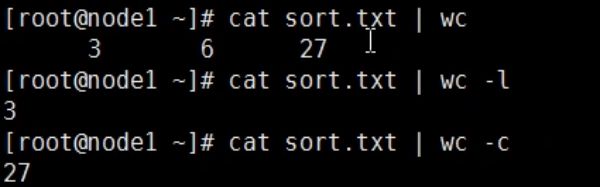
通过管道去除文件名信息
行编辑器
sed 命令
# 查看用法
man sed
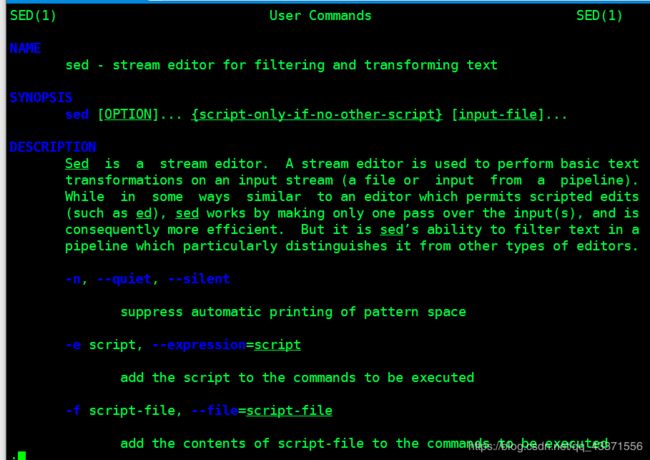
中文解释(可以开启man命令的中文解释)
sed [options] 'AddressCommand' file ...
-n: 静默模式,不再默认显示模式空间中的内容
-i: 直接修改原文件
-e SCRIPT -e SCRIPT:可以同时执行多个脚本
-f /PATH/TO/SED_SCRIPT
-r: 表示使用扩展正则表达式
d: 删除符合条件的行;
p: 显示符合条件的行;
a \string: 在指定的行后面追加新行,内容为string
\n:可以用于换行
i \string: 在指定的行前面添加新行,内容为string
r FILE: 将指定的文件的内容添加至符合条件的行处
w FILE: 将地址指定的范围内的行另存至指定的文件中;
s/pattern/string/修饰符: 查找并替换,默认只替换每行中第一次被模式匹配到的字符串*
g: 行内全局替换
i: 忽略字符大小写
s///: s###, s@@@
\(\), \1, \2
sed:行编辑器Address
可以没有
给定范围
查找指定行/str/
复制第二行数据
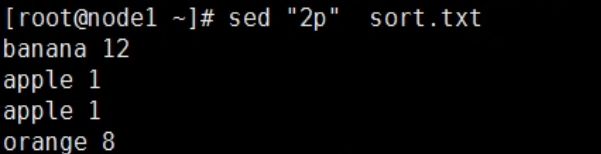
复制第二行数据, 只显示复制的内容, 不再默认显示模式空间中的内容

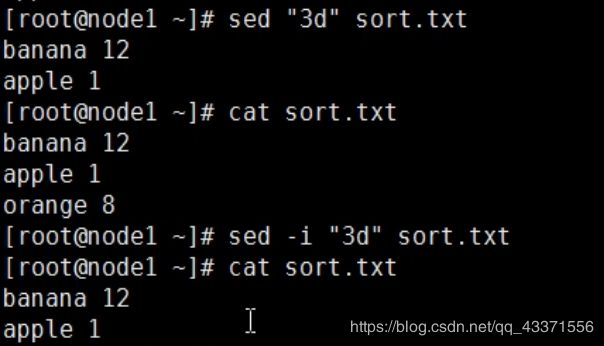
删除第三行数据, 需要注意的是现在只是显示执行后的预览
1.如果想要这个命令生效 ,需要添加 -i (相当于数据库中的commit)
2. "3d"相当于 3line delete
3. 在开发时, 需要我们灵活使用. 不要首先使用 -i ( 操作提交 ) ,而是先预览无误后提交
预览在第2行 后 添加新行
a: after

执行在第2行 前 插入一行字符sxt
-i : 执行命令
i\string : 指定行前
![]()
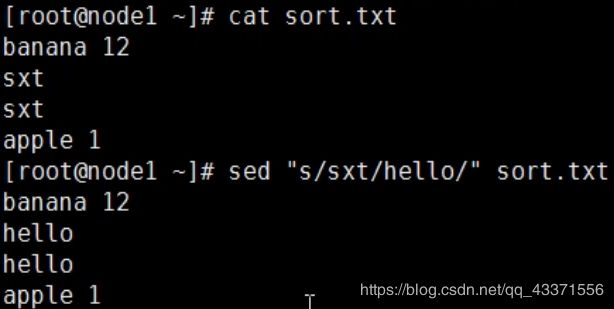
预览行编辑将字符串 “sxt” 替换成 "hello"
通过正则式匹配 IP 地址,并替换最后的主机号
#预览
sed "s/\(IPADDR=\(\([0-9]\|[1-9][0-9]\|1[0-9][0-9]\|2[0-4][0-9]\|25[0-5]\)\.\)\{3\}\).*/\1144/" ifcfg-eth0
#提交
sed "s/\(IPADDR=\(\([0-9]\|[1-9][0-9]\|1[0-9][0-9]\|2[0-4][0-4]\|25[0-5]\)\.\)\{3\}\).*/\1$num/" -i ifcfg-eth0

awk 命令(文本分析工具命令)
awk是一个强大的文本分析工具。
相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。
简单来说awk就是把文件逐行的读入,(空格,制表符)为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk -F '{pattern + action}' {filenames}
支持自定义分隔符(-F"自定义分隔符")
支持正则表达式匹配
支持自定义变量,数组 a[1] a[tom] map(key)
支持内置变量
ARGC 命令行参数个数
ARGV 命令行参数排列
ENVIRON 支持队列中系统环境变量的使用
FILENAME awk浏览的文件名
FNR 浏览文件的记录数
FS 设置输入域分隔符,等价于命令行 -F选项
NF 浏览记录的域的个数*
NR 已读的记录数*
OFS 输出域分隔符
ORS 输出记录分隔符
RS 控制记录分隔符
支持函数
print、split、substr、sub、gsub
支持流程控制语句,类C语言
if、while、do/while、for、break、continue
调用 print函数输出分割符分割后的第一列的数据
F 指定分割符
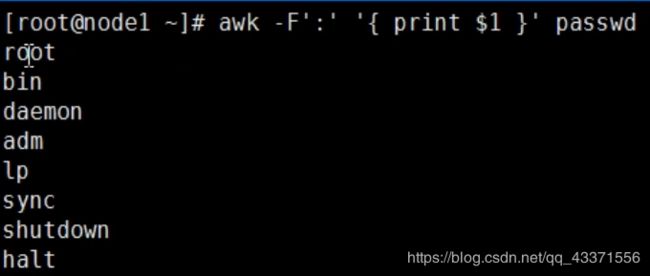
只是显示/etc/passwd的账户:CUT
awk -F':' '{print $1}' passwd
只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以逗号分割,而且在所有行开始前添加列名name,shell,在最后一行添加"blue,/bin/nosh"(cut,sed)
awk -F':' 'BEGIN{print "name,shell"} {print $1 "," $7} END{print "blue,/bin/nosh"}' passwd
搜索/etc/passwd有root关键字的所有行
awk '/root/ { print $0}' passwd
相当于如下cut命令
![]()
统计报表:合计每人1月工资,0:manager,1:worker
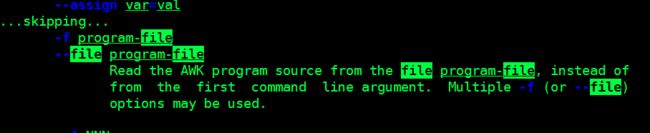
man awk
/file #查找到下一行,可以看到awk不仅支持命令,而且支持脚本文件
q #退出介绍
思路:先编写脚本,通过脚本运行该报表文件
# 报表内容
Tom 0 2012-12-11 car 3000
John 1 2013-01-13 bike 1000
vivi 1 2013-01-18 car 2800
Tom 0 2013-01-20 car 2500
John 1 2013-01-28 bike 3500
编写脚本
调用split分割第3列数据并且分割依据"-"进行分割
如果月份等于01
将第一列(姓名)作为数组下标
name[$1]+=$5 将相同数组下标元祖的值进行求和
END方法中遍历name数组,然后输出结果
{
split($3,date,"-");
if(date[2]=="01"){
name[$1]+=$5
}
}
END{
for(i in name){
print i "\t" name[i]
}
}
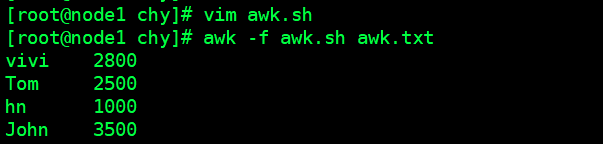
通过脚本文查询报表文件
# -f 脚本文件名
awk -f awk.sh awk.txt
用户与权限
基本用法
id 打印输出有效用户的自身的ID 和 所在组的 ID
useradd 添加用户
userdel 删除用户
groupadd 添加组
groupdel 删除组
passwd 设置或修改密码
sudo 提升权限
su 切换用户
ReadMe:
- 添加用户后,会自动为该用户添加邮箱文件,
如果删除文件,不仅需要存在/home下删除用户,还要去/var/spool/mail/中删除同名的邮箱文件 - 修改密码, root用户
passwd修改root用户密码;passwd 用户名修改指定用户密码; 普通用户passwd只能修改自己密码 - 创建角色和密码后, 可以在xshell中通过
ssh 用户名@用户所在ip进行登录.
而且,这些创建的普通用户只能进行简单的文件查看功能.这里就引入了用户组的操作,通过用户组完成权限的分配
用户组操作
添加用户组, 查看各用户id
groupadd 新建用户组名
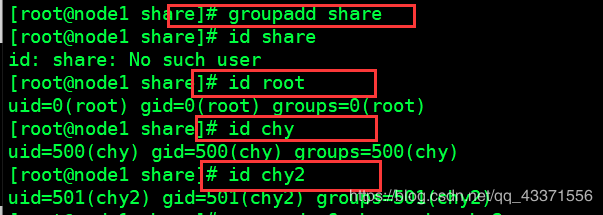
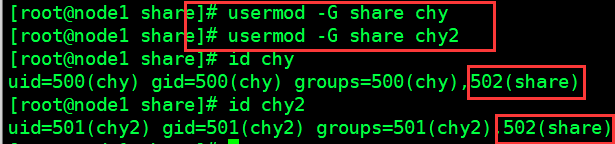
将两个普通用户添加到用户组 share中, 并再次查看用户id ,确认是否分配成功
usermod -G 用户组名
更改权限 ,为文件赋予指定组
#chown 文件所属原用户组:现用户组 文件名
chown root:share share/
# 给指定文件添加 用户组的读权限
# 第一组 rwx 代表文件所有者权限,第二组 r-x 代表用户组权限,第三组 r-x 代表其他用户权限。
# 权限分类: r:读权限 w:写权限 x:执行权限(打开文件夹也需要读权限)
# 角色 a:所有角色 u:所属用户 g:用户组 o:其他
chmod g+r share/
# 或者更改文件的所有者
chown -R chy share/
# 撤回其他用户读写执行权限
# 注意这里修改权限后需要重新登陆用户组的用户才能生效
chmod o-r--w-x share/
linux角色权限必会知识
1. 下图各列参数作用:
文件权限 连接数 文件所有者 用户组 文件大小 修改日期 文件名
2 .第一列参数意义:
第一组 rwx 代表文件所有者权限,第二组 r-x 代表用户组权限,第三组 r-x 代表其他用户权限。
3. 权限分类:
r:读权限 w:写权限 x:执行权限(打开文件夹也需要读权限)
4. 角色分类
a:所有角色 u:文件所有者 g:用户组 o:其他
了解更多相关知识请前往
权限操作
| 命令 | 作用 |
|---|---|
| r | 读权限 r=4 |
| w | 写权限 w=2 |
| x | 可执行权限 x=1 |
| usermod | 修改用户权限 |
| chown | 修改文件的属主和属组 |
| chmod | 修改文件操作权限 (RWX) augo |
注意
权限有两种表示方式, 一种字母方式 : r:读权限 w:写权限 x:执行权限(打开文件夹也需要读权限)
还有一种是数字方式: r4w2x1 ,我们可以通过数字的形式同时为文件所有者_用户组_其他用户赋予权限
但是所做的所有修改对于root 用户来说是形同虚设的( root牛皮!!!)
例如:
# 赋予所有用户读权限
chmod 444 filename/ chmod a+x filename
#赋予所有用户所有权限
chmod 777 filename/ chmod a+wrx filename
Linux软件安装
编译安装
主要体会./confiure , make ,make install 的区别
# 1. 检查操作系统 ,检查编译环境
yum install gcc
# pcre 依赖库
yum search pcre
yum install pcre-devel
# openssl
yum install opssl-devel
# 2.上传并解压
tar -zxf nginx-1.8.0.tar.gz
# 3.在解压目录下生成编译依赖关系
./configure
# 4.编译安装
make & make install
#5. 进入nginx的命令管理目录,启动
cd /user/sxt/nginx/sbin
./nginx
# 7.浏览器访问测试
输入虚拟机地址即可
rpm安装
Redhat提供了rpm管理体系
已经编译的软件包:针对不同的平台系统编译目标软件包
操作系统维护安装信息 ,软件包包含依赖检查,但还需人为解决
# rpm安装:
-ivh filename
--prefix
# rpm升级:
-Uvh
-Fvh
rpm卸载:
-e PACKAGE_NAME
# rpm查询 ,配合管道一起使用 ,例如 rpn -qa |grep jdk
rpm -qa : 查询已经安装的所有包
rpm -q PACKAGE_NAME: 查询指定的包是否已经安装
rpm -qi PACKAGE_NAME: 查询指定包的说明信息
rpm -ql PACKAGE_NAME: 查询指定包安装后生成的文件列表
rpm -qc PACEAGE_NEME:查询指定包安装的配置文件
rpm -qd PACKAGE_NAME: 查询指定包安装的帮助文件
rpm -q --scripts PACKAGE_NAME: 查询指定包中包含的脚本
# 查询文件是由哪个rpm包安装生成的(与type(查看命令所在目录)命令一起使用)
rpm -qf /path/to/somefile
# 如果某rpm包尚未安装,需查询其说明信息、安装以后会生成的文件
rpm -qpi /PATH/TO/PACKAGE_FILE
rpm -qpl
小技巧 : 见到别人的命令很好用,自己如何安装
例如 ifconfig命令
1.查看该命令所在文件夹 type ifconfig
ifconfig is /sbin/ifconfig
2.查询该目录下的 jar包 rpm -qf /sbin/ifconfig
net-tools-1.60-110.el6_2.x86_64
3.搜索 yum search net-tools 不要加版本
================================ N/S Matched: net-tools =================================
net-tools.x86_64 : Basic networking tools
4.安装 yum install net-tools
5.使用
yum安装
基本命令
# yum命令:
yum repolist
yum clean all
yum makecache
yum update
# 查询:
yum list
yum search
yum info
# 安装&卸载:
yum install
remove|erase
# yum命令:分组
yum grouplist
yum groupinfo
yum groupinstall
yum groupremove
yum groupupdate
阿里云CentOS的yum源
# 1.进入镜像仓库
cd /etc/yum.repos.d/
# 2.创建用于备份的文件夹(更换源失败可以从备份文件获取)
mkdir backup
# 3.将镜像文件移动到备份文件中
mv CentOS-* backup/
# 4.下载wget命令支持包
yum install -y wget
# 5. 下载阿里镜像,下载以后 yum.repos.d文件下回多出一个文件CentOS-Base.repo(图1)
# 阿里云镜像站地址 https://opsx.alibaba.com/mirror
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
# 我们可以查看这个文件 ,这个文件中存放了许多安装地址
cat CentOS-Base.repo
# 6.清除本地缓存的jar包依赖关系(图2)
yum clean all
# 7.重新添加阿里的依赖关系缓存(图3)
yum makecache
如果安装出现如下错误http://mirrors.aliyuncs.com/centos/6/updates/x86_64/repodata/repomd.xml: [Errno 14] PYCURL ERROR 56 - "Failure when receiving data from the peer"
需要根据repo文件变量的变化,可以修改repo文件把所有$releasever替换成6
# 执行替换操作
sed -i 's/\$releasever/6/' CentOS-Base.repo
# 清理并重新生成yum缓存
yum clean all
# 重新yum makecache, 出现图4说明安装成功
yum makecache
#如果还出现错误 ,运行如下sed语句 ,清空缓存 ,并重新生成缓存
sed -i '/mirrorlist/d' CentOS-Base.repo
sed -i 's/\$releasever/6/' CentOS-Base.repo
sed -i '/\ [addons\]/,/^$/d' CentOS-Base.repo
sed -i 's/RPM-GPG-KEY-CentOS-5/RPM-GPG-KEY-CentOS-6/' CentOS-Base.repo
图1

图2
图3
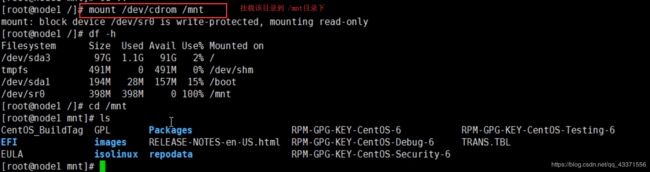
本地 yum 源
1.为当前虚拟机挂载镜像文件
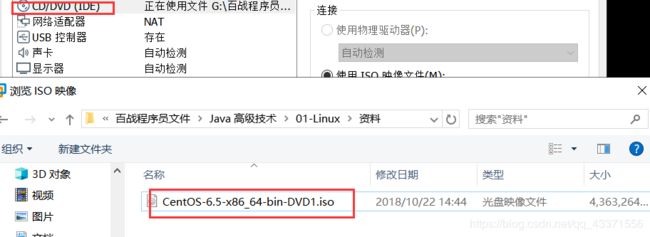
# 2.挂载 cdrom (mount 被挂载文件 挂载文件)
mount /dev/cdrom /mnt
# 3.备份CentOS-Base.repo文件
cd /etc/yum.repos.d/
cp CentOS-Base.repo CentOS-Base.repo.backupAliYuan
# 4.修改CentOS-Base.repo,文件只保留下面内容(图1)
#[base]
name=local
failovermethod=priority
baseurl=file:///mnt
#gpgchkeck= 有1和0两个选择,分别代表是否是否进行gpg校验,如果没有这一项,默认是检查的。
gpgcheck=1
#当某个软件仓库被配置成 enabled=0 时,yum 在安装或升级软件包时不会将该仓库做为软件包提供源。使用这个选项,可以启用或禁用软件仓库。
enable=1
# 5. 重新安装依赖缓存(图2)
yum makecache
# 6. 安装想使用的软件,例如 mysql(无需联网)
yum install mysql-server
重启后, 在使用本地源时,建议查看镜像文件是否被挂载(图3)
df -h
如果没有被挂载 ,重新挂载一下( 取消挂载命令是umount )
mount /dev/cdrom /mnt
# 如果下载不上,建议首先查看挂载设置连接状态图4 ,然后重新挂载一下,如果实在没有就更换为阿里数据源
步骤:
取消本地挂载,
删除本地CentOS-Base.repo ,
放开/重新下载阿里的CentOS-Base.repo,
清除并重新下载依赖关系
图1

图2

图3
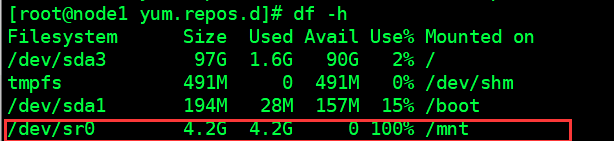
图4
中文显示,查看帮助中文文档
中文显示
# yum 的 repo 变成aliyun || 本地DVD
# 1. 如果使用本地源, 查看列表是否含有中文包
yum grouplist | grep Chinese Support
# 2.如果存在直接下载(使用阿里源的直接执行这一步)
# 注意: 存在空格的必须使用 " "引上
yum groupinstall "Chinese Support"
#3 .查询当前语言, 如果显示的是en_US.UTF-8
echo $LANG
# 4. 更换语言为中文,可以通过ll查看是否配置成功(下图)
LANG=zh_CN.UTF-8

中文帮助文档设置
前提 :执行上面的中文显示的支持
# 1. 访问阿里镜像站, 下载epel源 ,网站地址 https://opsx.alibaba.com/mirror?lang=zh-CN
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo
# 2. 下载中文支持下的依赖
yum repolist
# 3. 依次执行如下命令
yum clean all
yum makecache
yum search man-pages
yum install man man-pages man-pages-zh-CN
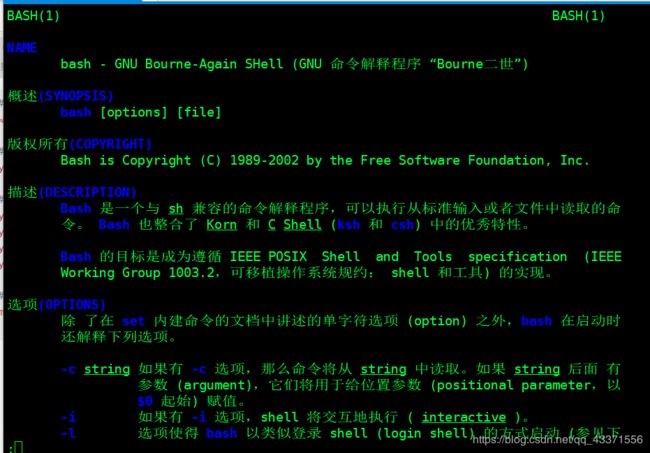
# 4. 测试帮助命令是否变为中文(如下图)
man bash
# 5. 注意 :每次重启后 ,如果中文显示不出来了, 需要执行如下命令 ,
# 因为LANG命令是对每一个bash而言的(一个窗口对应一个bash)
LANG=zh_CN.UTF-8
注意 : 即使安装了中文包, 也不是每个命令都会被翻译成中文
文本流和重定向
# 文件描述符fd
cd /proc/$$/fd +tab键 ( $$就会转换成进程当前shell的id)
# 查看文件描述符fd目录(图1)
ll
0 标准输入
1 标准输出
2 错误输出
# 利用管道与进程id查看当前进程新消息, 再由当前进程寻找他的父进程(图2)
# 也就是说我们每次发起请求, 都会在服务端开启一个虚拟终端
ps -ef | grep 6564
ps -ef | grep 6560
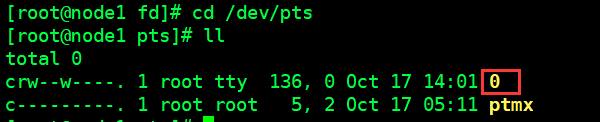
# 我们可以进入父进程所在目录查看虚拟终端(图3)
# 如果创建一个窗口执行第一个操作 ,虚拟终端id就会从0加1, 一次类推
# 在Linux中. 一切皆文件!!!
# 所有命令, 功能都可以映射成文件 ,都有012这种输入输出方式
cd dev pts
图1
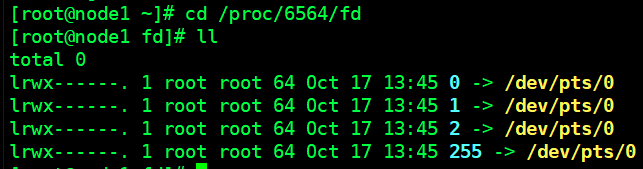
图2
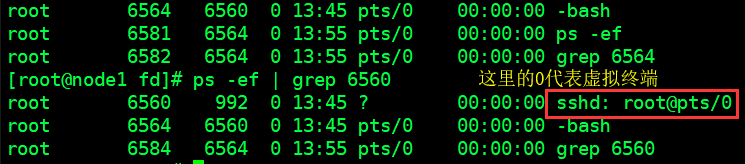
图3
重定向
输出重定向
#输入重定向
# 见图1
1>xxx 标准输出覆盖重定向
1>>xxx 标准输出追加重定向
# 见图2
2>xxx 错误覆盖重定向
2>>xxx 错误追加重定向
# 在一个文件中如果同时输出标准输出内容和错误内容
# 1.使用普通重定向 ,会发现不会出现错误音效(图3) ,原因是在执行ls时, 首先会扫描文件是否存在 ,然后输出文件信息将原来的错误信息
# 2.因此, 如果使用追加重定向时 ,无论顺序如何 ,都会首先打印错误信息(图4)
# 3. 文件描述符+">&"+重定向符号详细形式
# 注意: 左边文件描述符(1,2)与重定向符号之间是不能有空格的 ,但是右边可以, 所以建议都不要留空格
ls / /error 2>&1 1>&eee
ls / /error 1>&fff 2>&1
# 4.特例(简写形式) :>&或者&> xxx 向 xxx 文件添加错误和标准输出信息(图5)
ls / /error >& ggg
ls / /error &> hhh
图1
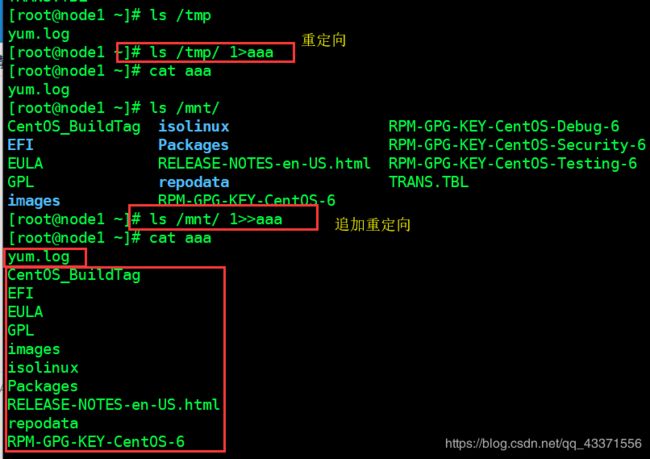
图2
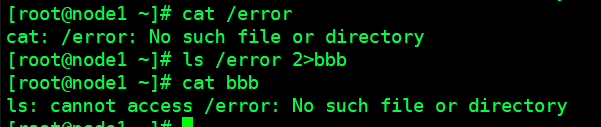
图3
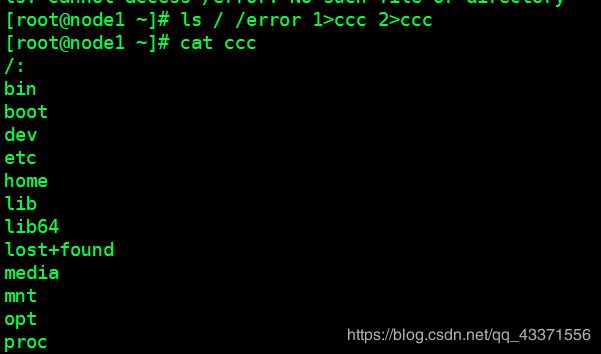
图4
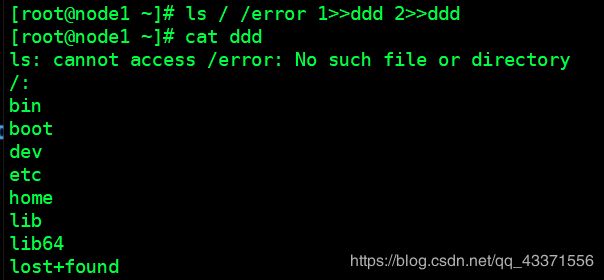
图5
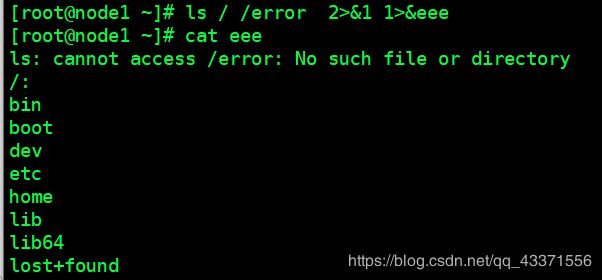
图6
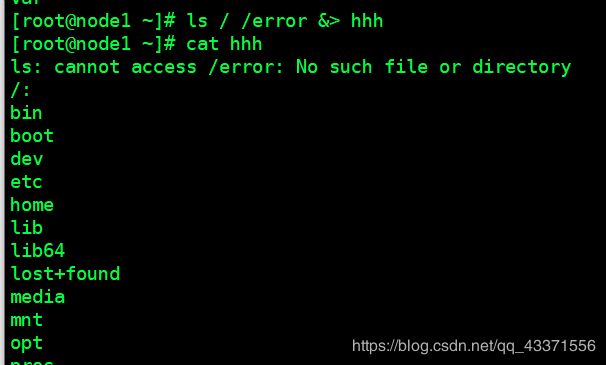
输入重定向
# 输出重定向
#语法
<<< 从字符串中读取输入
<<E 从键盘中读取输入,E表示结束符
< 从文件中读取输入
[root@node01 input]# read aaa <<<"HelloWord"
[root@node01 input]# echo $aaa
HelloWord
[root@node01 input]# read aaa<
> ljasf
> ajlsdfj;la
> ;ajdfkl
> GG #跟 GG 一样,表示输入退出
# 输出aaa第一行数据
[root@node01 input]# echo $aaa
ljasf
# input.sh 脚本
cat <<AABB
print error info
AABB
echo "you know me .."
# 执行
source input.sh
[root@node01 input]# cat 0< /etc/in
init/ init.d/ inittab inputrc
[root@node01 input]# cat 0< /etc/inittab
全重定向
# 全重定向:socket案例
# 创建文件描述符8
exec 8<> /dev/tcp/www.baidu.com/80
# 发送请求, 将信息写入8中
echo -e "GET / HTTP/1.0\n" >& 8
# 输出8的信息(图下图)
cat <& 8
shell 脚本编程
Bash
linux的发布版本之一——Redhat/CentOS——系统默认安装的shell叫做bash,即Bourne Again Shell,它是sh(Bourne Shell)的增强版本。Bourn Shell 是最早行起来的一个shell,创始人叫Steven Bourne,为了纪念他所以叫做Bourn Shell,检称sh。
含有shell命令的文件三种运行方式
第一种 source 文件名(图2)
第二种 . 文件名 (图3)
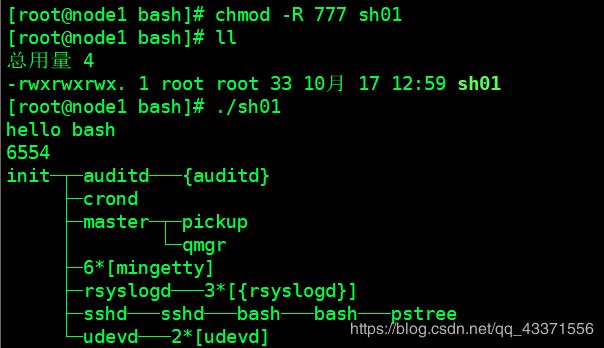
第三种 赋予该文件执行权限 chmod -R 777 文件名 , 执行该文件 ./文件名 (图4)
注意:
一定要写成 ./test.sh,而不是 test.sh,运行其它二进制的程序也一样,
直接写 test.sh,linux 系统会去 PATH 里寻找有没有叫 test.sh 的,而只有 /bin, /sbin, /usr/bin,/usr/sbin 等在 PATH 里,
你的当前目录通常不在 PATH 里,所以写成 test.sh 是会找不到命令的,要用 ./test.sh 告诉系统说,就在当前目录找。
想要具体了解shell编程可通过这里进行学习
图1 :含有脚本的文件 sh01

图2
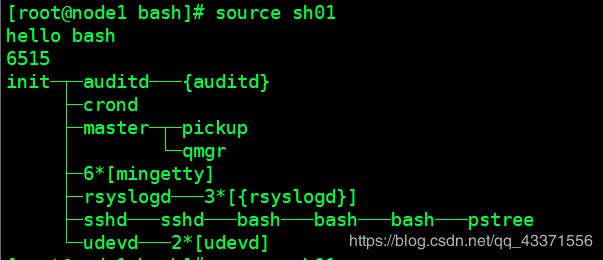
图3
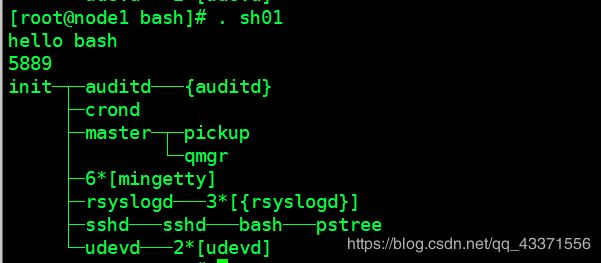
图4
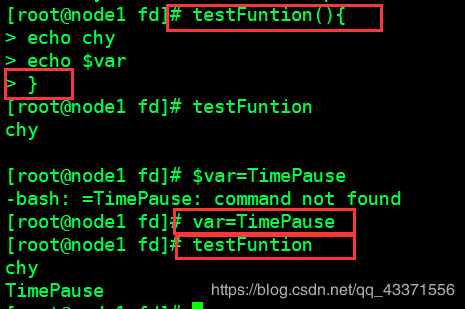
变量
# 语法
# 本地:(图1)
当前shell拥有
生命周期随shell
# 局部:
只能local用于函数
# 位置:(图2)
$1,$2,${11} 从脚本文件后,读取参数
# 特殊
$#: 位置参数个数(图3,图4,图5)
$*: 参数列表,双引号引用为一个字符串
$@: 参数列表,双引号引用为单独的字符串
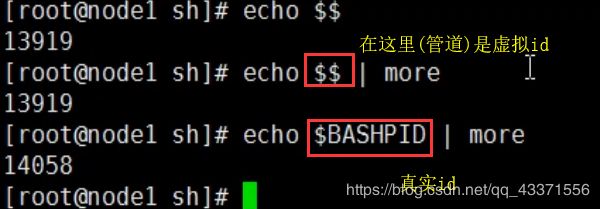
$$:当前 shell 的 PID:接收者(图6)
$BASHPID:真实
管道 *
$?:上一个命令退出状态
- 0 成功
-other: 失败
# 变量
export 定义环境变量: 不管开启了多个字bash,都会引用系统变量
导出到子 shell
fork() Copy On Write 时间复杂度 O(1)
适用用于函数
unset: 取消变量
set: 查看shell 的变量
图1
# 创建shell文件
vim test.sh
# 编辑内容
echo $1
echo $2
# 发现a,b自动被shell文件接收并输出(图2)
source test.sh a b
图2
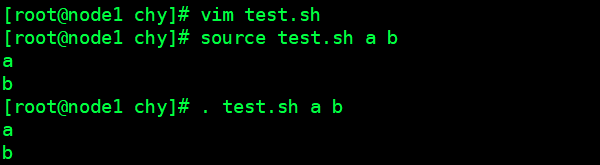
图3
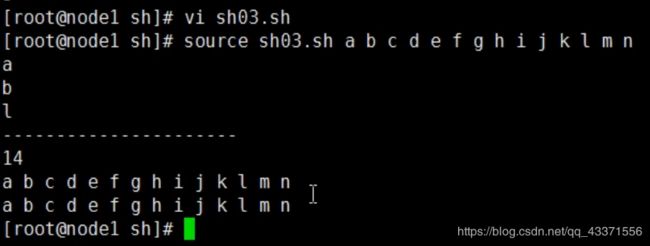
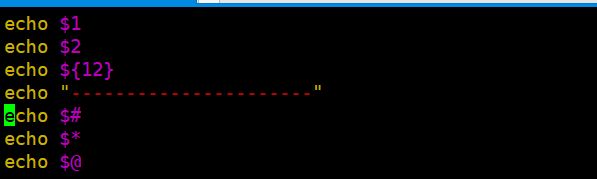
图4
在管道里创建子bash时 , 它会继承父bash
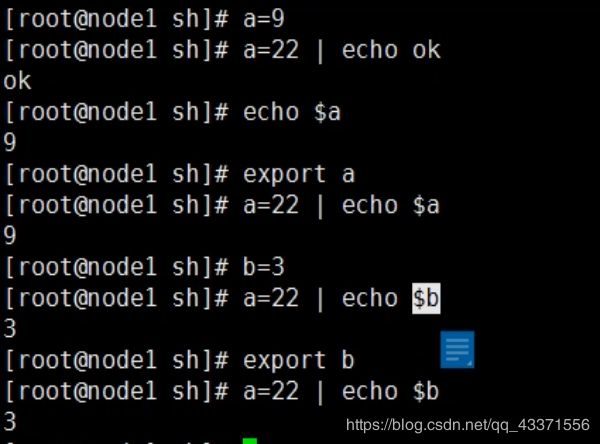
图5
但是在文件中执行子bash时, 他不会继承父bash的值, 只有export ,他才会继承他的值
而且 ,不能跨bash
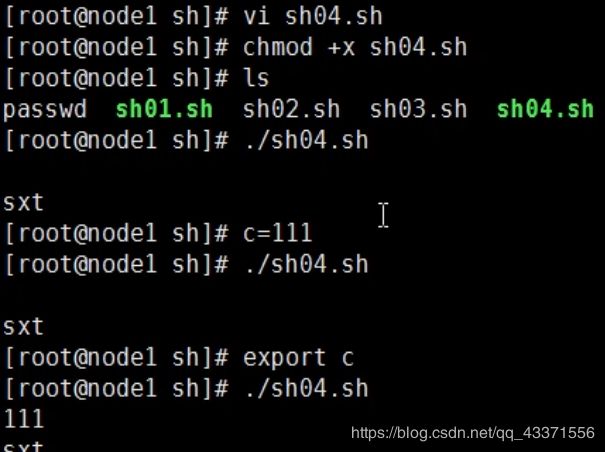

图6
引用
双引号:弱引用,参数扩展
单引号:强引用,不可嵌套
花括号扩展不能被引用
命令执行前删除引用
[root@node01 sh]# kk=12
[root@node01 sh]# echo "$kk"
12
[root@node01 sh]# echo '$kk'
$kk
# 花括号扩展不能被引用
[root@node01 b]# cp "/etc/{passwd,inittab}" ./
cp: cannot stat `/etc/{passwd,inittab}': No such file or directory
命令替换
# 基本语法
反引号:`ls -l /`
$(ls -l /)
可以嵌套
[root@node01 sh]# echo "`echo 123`"
123
[root@node01 sh]# abc=$(echo $(echo "sxt"))
[root@node01 sh]# echo $abc
sxt
[root@node01 sh]# abc=$(ls -l /)
[root@node01 sh]# echo $abc
total 98 drwxrw-r-x. 3 root root 4096 Sep 22 13:53 abc dr-xr-xr-x. 2 root root 4096 Sep 22 21:34 bin dr-xr-xr-x. 5 root root 1024 Sep 21 19:29 boot drwxr-xr-x. 18 root root 3680 Sep 22 21:45 dev drwxr-xr-x. 76 root root 4096 Sep 22 21:45 etc drwxr-xr-x. 4 root root 4096 Sep 22 13:04 home dr-xr-xr-x. 8 root root 4096 Sep 22 14:16 lib dr-xr-xr-x. 10 root root 12288 Sep 22 21:34 lib64 drwx------. 2 root root 16384 Sep 21 19:28 lost+found drwxr-xr-x. 2 root root 4096 Sep 23 2011 media drwxr-xr-x. 2 root root 4096 Sep 23 2011 mnt drwxr-xr-x. 2 root root 4096 Sep 23 2011 opt dr-xr-xr-x. 87 root root 0 Sep 22 21:45 proc dr-xr-x---. 5 root root 4096 Sep 23 03:26 root dr-xr-xr-x. 2 root root 12288 Sep 22 17:58 sbin drwxr-xr-x. 7 root root 0 Sep 22 21:45 selinux drwxrwx---. 2 root share 4096 Sep 22 13:51 share drwxr-xr-x. 2 root root 4096 Sep 23 2011 srv drwxr-xr-x. 13 root root 0 Sep 22 21:45 sys drwxrwxrwt. 3 root root 4096 Sep 23 02:02 tmp drwxr-xr-x. 14 root root 4096 Sep 22 17:50 usr drwxr-xr-x. 17 root root 4096 Sep 21 19:28 var
表达式
# 算术表达式(图1,图2)
let 算术运算表达式
let C=$A+$B
$[算术表达式]
C =$[$A+$B]
$((算术表达式))
C=$(($A+$B))
expr 算术表达式
注意:表达式中各操作数及运算符之间要有空格。而且要使用命令引用
C=`expr $A + $B`
help let
# 条件表达式(图3)
[ expression ]
test expression
[[ expression ]]
help test
图1
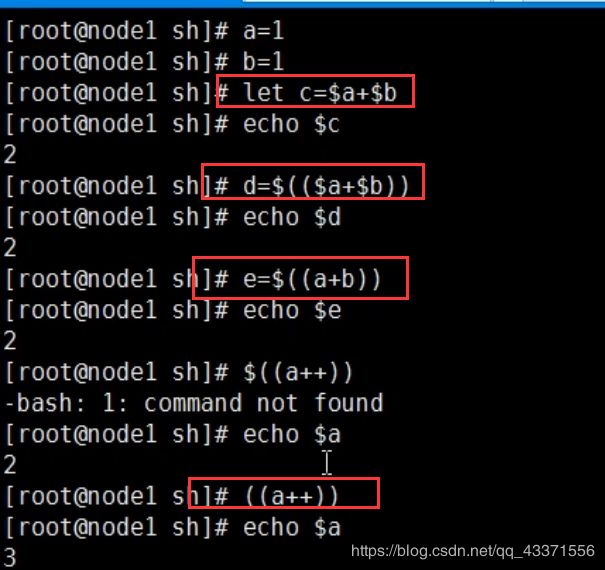
图2
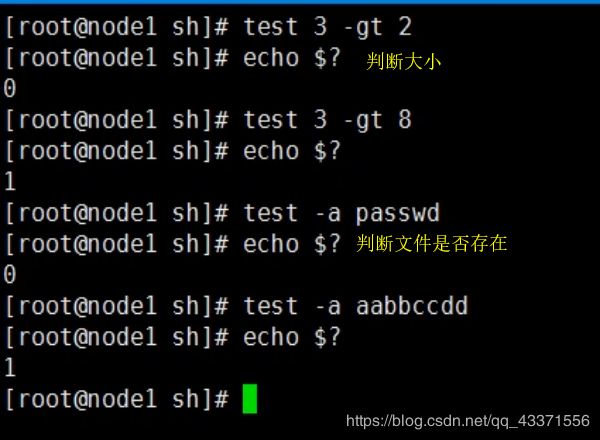
图3

编写shell 脚本案例——添加用户脚本
明确需求
添加用户
用户密码同用户名
静默运行脚本
避免捕获用户接口
程序自定义输出
脚本内容
第二行判断参数,
第三行判断用户是否存在,
第四行添加用户密码并解决数据回显,
第五行解决权限不足问题
#! /bin/bash
[ ! $# -eq 1 ] && echo "args error!" && exit 2
id $1 >& /dev/null && echo "user exist!" && exit 3
useradd $1 >& /dev/null $$ echo $1 | passwd --stdin $1 >& /dev/null && echo "add user successful!!!" && exit 4
echo "user add fail for no why" && exit 5
总结 :
脚本使用的意义就是实现项目启动自动化 ,在大型分布式项目部署的时候 ,可能有几十甚至上百个服务需要启动 ,
这个时候, 脚本自动化实现就显得尤为重要了
逻辑判断
# 判断命令是否被执行? 返回值为0代表执行 ,非0代表执行失败
# 在Linux中的条件判断中 ,返回0代表是true ,非0代表false ,区别java
echo $?
# 逻辑判断
command1 && command2
command1 || command2
流程控制
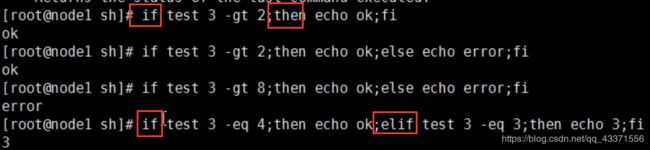
if选择语句
man if
NAME
if - 有条件的执行脚本
总览 SYNOPSIS
if expr1 ?then? body1 elseif expr2 ?then? body2 elseif ... ?else? ?bodyN?
________________________________________________________________________________
描述 DESCRIPTION
if 命令把 expr1 作为一个表达式来求值(用与 expr 求值它的参数相同的方 式)
。 这个表达式的值必须式一个 boolean 值(一个数值值,这里 0 是假而任何其他
数值都是真;或者是一个字符串值,比如 true 或 yes 是真而 false 或 no 是
假) ;如果它是真通过把 body1 传递给 Tcl 解释器来执行它。否则把 expr2 作
为一个表达式来求值并且如果它是真则执行 body2,以此类推。如果没有表达式 被
求值为真则执行 bodyN 。then 和 else 是可选的“噪音词”用来使命令易读。可
以有任意数目的 elseif 子句,包括零个。BodyN 与 else 可同时省略。命 令
的 返 回 值是被执行的那个脚本的返回值,如果没有表达式是非零并且没有 bodyN
则返回空串。
参见 SEE ALSO
expr(n), for(n), foreach(n)
关键字 KEYWORDS
boolean, conditional, else, false, if, true
while循环语句
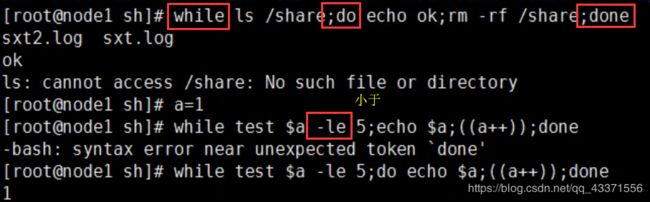
man while
NAME
while - 在条件满足时重复的执行脚本
总览
while test body
描述
while 命令把 test 作为一个表达式来求值(用与 expr 求它的参数的值相同的方
式)。这个表达式的值必须是一个正确的 boolean 值;如果它是真值则把 body 传
递给 Tcl 解释器来执行它。一旦执行了 body 则再次求值 test ,并重复处理直到
最终 test 求值出一个假 boolean 值。可以在 body 中执行 Continue 命令来终止
这 个循环的当前重复操作(iteration),并可以在 body 中执行 break 命令来导致
while 命令立即终止。while 命令总是返回一个空串。
注意: test 应该总是包围在花括号中。如果不是,在 while 命令开始执行之前 将
进 行变量替换,这意味着循环体所做的变量变更将不考虑在这个表达式中。这将很
可能导致无限循环。如果 test 被包围在花括号中,变量替换被推迟到求值这个 表
达 式的时候(在每次循环重复操作之前),所以变量的变化将是可见的。例如,尝试
下列脚本并在 $x<10 两边分别加上和不加花括号:
set x 0
while {$x<10} {
puts "x is $x"
incr x
}
for循环语句
man for
________________________________________________________________________________
NAME
for - ‘‘For’’ 循环
总览 SYNOPSIS
for start test next body
________________________________________________________________________________
描述 DESCRIPTION
For 是一个循环命令,在结构上类似与 C 语言的 for语句。start、next、和body
参数必须是 Tcl 命令串,而 test 是一个表达式串。for 命令首先调用 Tcl 解释
器来执行 start。接着它重复的把 test作为一个表达式来求值;如果结果是非零则
它在 body 上调用 Tcl 解释器,接着在 next 上调用 Tcl 解释器,接着重复这 个
循环。在 test 被求值为 0 的时候命令终止。如果body 中调用了 continue 命
令则在 body 的当前执行中的所有剩余的命令都被跳过;处理继续,在 next 上调
用 Tcl 解释器,接着对 test 求值。 等等. 如果在 body 或 next 中调用 break
命令,则 for 命令将立即返回。break 和 continue 命令的操作类似于在 C 语
言中相应的语句。For 返回一个空串。
注意: test 应当总是在花括号中包围着。如果不是这样,在 for 命令开始之前就
作了变量替换,这意味着在循环体中做的变量变更在表达式中将不被考虑。将导 致
一 个 无限循环。如果 test 被包围在花括号中,变量替换将延迟,直到表达式求
值(在每次循环重复之前),所以变量的变更将是可见的。例如,尝试在 $x<10 周围
有和没有一对花括号的下列脚本:

反引号就是esc下面的那个按键!!!
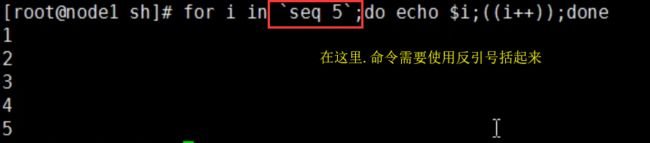
编写shell 脚本案例——判断目录下最大文件
思路
用户给定路径
输出文件大小最大的文件
递归子目录
脚本内容
#! /bin/bash
oldIFS=$IFS
IFS=$'\n'
for i in `du -a $1 | sort -nr `;
do filename=`echo $i | awk '{print $2}'`;
if [ -f $filename ];
then echo $filename break;fi
done
IFS=$oldIFS
运行测试
![]()
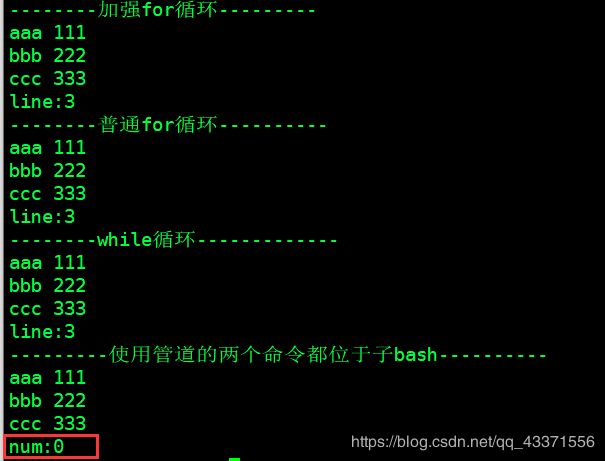
编写shell 脚本案例——递归子目录
被遍历的文件file.txt
aaa 111
bbb 222
ccc 333
#! /bin/bash
oldIFS=$IFS
IFS=$'\n'
echo "--------加强for循环---------"
num=0;
for i in `cat file.txt`;
do echo $i;
((num++))
done
echo "line:$num"
IFS=$oldIFS
echo "--------普通for循环----------"
line=0;
lines=`cat file.txt | wc -l`
for ((i=1;i<=lines;i++));
do echo `head -$i file.txt | tail -1`
((line++))
done
echo "line:$line"
echo "--------while循环-------------"
num=0
while read line;
do echo $line
((num++))
done <file.txt
echo "line:$num"
echo "---------使用管道的两个命令都位于子bash,其他位于父bash----------"
num=0
cat file.txt | while read line;
do echo $line
((num++))
done
echo "num:$num"
运行测试