Clickhouse 在腾讯的应用实践

今天给大家介绍 Clickhouse 在腾讯的应用实践, 主要分为两部分内容:
Clickhouse 的部署和管理
Clickhouse 在腾讯业务线的应用实践
Clickhouse 的部署和管理
Clickhouse 它自身是一个非常强大的数据处理的引擎,因为它非常专注数据处理的计算效率这一块,因此它周边的一些管理插件,其实还是比较弱的。
大家在做大数据的平台,以及在做一些平台产品的时候,其实管理和监控都是蛮重要的一部分。不然你的平台出了问题,业务提出挑战,说为什么查不出来,或者我的数据为什么慢?这时候平台如果没有一个合理的解释的话,平台必然是要背锅的。下面我们一起看一下 Clickhouse 在我们生产环境的部署情和监控管理。先给大家介绍一下我们的选型机器,因为 Clickhouse 它是一个服务于大数据场景的MPP数据库,那么它的应用场景是非常明确的,是一个“大数据”的快速查询场景。
这种情况下,其实它对于并发性要求不是特别的高,因为数据大,那么它对于磁盘的容量其实要求还反倒多一些,这样的话我们用一些廉价盘就是传统的这种sata盘来做这种的底层数据的存储。Clickhouse 虽然有这种主从同步,数据复制的机制,它的一个单机损坏的话,虽然你有备库可以做支撑查询,但是相对来说恢复的成本也是很高的。建议在单机之上使用raid5模式,也就是尽量在单机况下也能够保障它一些数据的安全性。
然后因为 Clickhouse 还有一个特性,就是它是一个share nothing的架构,就是说他不能避免一些情况下需要单机一些内存的排序的和处理一些大量的数据,这种情况下,它对于内存的要求其实也蛮高的,有的时候像内存如果不够它会出现oom,虽然他有一些可以扩展内存的方式使用磁盘去做一些额计算出来,但是相对来说性能会有影响。所以会选择内存稍微大一点的服务器。然回到网卡话,因为万兆网卡都是比较普及的了,千兆网卡在大数据应用的场景下是非常容易被打满的,容易影响到服务的稳定性,因此选择万兆网卡作为基础服务。
下面这是我们一个生产环境的部署方案:

首先笼统的说我们是一个读写分离的模式,数据写入我们使用这样一个外围的负载均衡机制来去写不同的分片,然后不同分配下都是双重备份的,这样的话就可以分散的去写数据。读的时候是用distribution表去读取数据,对 Clickhouse 有一定了解的话,就会疑惑,我们为什么不直接去写这个distribution表,这样不是峰更方便吗?这有有两点原因。
第一点就是专一
distribution表更多的工作应该是分发读取SQL和整合数据,是在读取的方面比较有优势,而非要利用它来做负载均衡进行数据写入,虽然可以,但是无意中增加的它的负担,再说外部独立部署一个负载均衡是一个非常简单的事情。把专有功能交给专有模块去做会更加合适,也更加稳定一些。
第二点就是在扩容方面比较平滑
因为 Clickhouse 比较粗犷,如果直接写distribution表的话,在扩容过程中难免会遇到一些问题,不够平滑。而这种方案可以按照以下步骤更加平滑的扩展服务:
安装新部署新的shard分片机器
批量修改当前集群的配置文件增加新的分片
新shard上创建表结构
名字服务添加节点

在这个过程中你在做前三步的时候,对在线服务基本上是没有任何影响的OK了,并且你新上的节点也是没有任何数据写入的,当你完成了所有的检查之后,在负载均衡器中增加你的新节点,就能够保障一个平滑扩容了。
下面是 Clickhouse 写入策略的一个小分析:

Clickhouse 不是事务型的那种数据库它无法支持很高的并发,它服务于大数据,它更加适合这“大批量,少批次”的写入,所谓的大批量少批次,就是说把数据一批一批地组合在一起,一次性的去写入更多的数据,在我们线上测试的数据中大家可以看到, 2万条一个批次和100万一个批次的差别,我们主要看两块,一是磁盘的等待,它们基本上都是50%左右。
一个服务器,磁盘50%等待的时候就已经说明他的IO已经到达瓶颈了,还算是一个可以忍受的瓶颈,但它们的差别在哪?当插入2万的时候40%的磁盘等待已经出现了insert失败的错误, 100万的时候磁盘等待时间是54%磁盘IO要比2万的时候高,但是没有任何插入失败,说明服务器的利用率更高了。因此可以验证, Clickhouse 更适合这种大批量,少批次的写入模式。
下面的例子比较类似,是在说每一条数据的大小情况,用10K 和 100 B对比,大家可以看到10K的数据相对来说更加适合 Clickhouse 的写入情况。这个场景能就反推过来,一个应用场景所有的数据库在处理join的时候其实都是有一些瓶颈的,但是 Clickhouse 的优势是列宽,他是一个列式存储,对列宽基本上没有什么限制,因此我们可以建立一个更宽的大宽表,吧join的操作变成表查询操作,我昨天和ivan聊了一下,目前 Clickhouse 的列宽大概可以支持到1万列左右,在1万个月以下的时候,其实没有什么问题,都是非常好的,因此建议大家更多使用宽表来替代join。
以上介绍了 Clickhouse 的部署模式和写入模式,下面介绍一个立体监控模型。
Clickhouse 立体监控模型
大家在做平台的时候,很多情况下就会有一个分界点,就是跟业务之间分得太开,业务做业务的数据指标监控,平台做平台的监控。但其实平台有时也需要关注业务的这种指标数据,你业务数据出现了问题,反推平台一定是也出现了问题的。所以这种情况下就是说做平台的兄弟一定也是要建立一些业务方面的监控。例如空值或者是断线这样的一些监控指标其实是非常重要的。
然后在服务层,就是 Clickhouse 。很多时候不管是 Clickhouse 也好还是一些其他服务,大家很容易忽略它的错误日志,偶尔几条错误服务不crash的情况下大家关注不多。这种情况其实无意中就给你的服务埋下了一个很大的隐患,所谓千里之提溃于蚁穴。
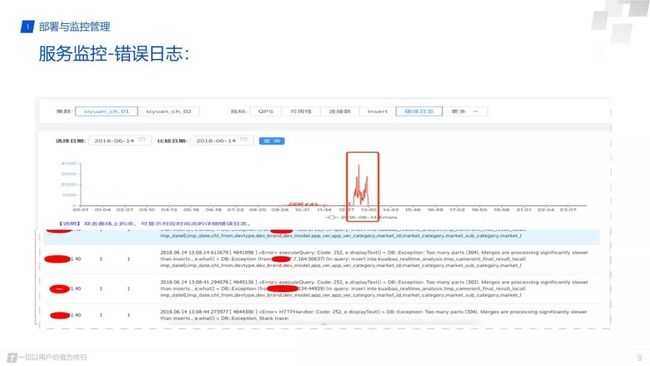
这种情况下,建议大家把log不断的记下来,当你的服务出现问题的时候完全可以去看出问题的时间点,你的错误log到底有多少?你的log内容到底是什么?这样可以提高你平台处问题时候的定位效率,也能提高你的平台的稳定性。
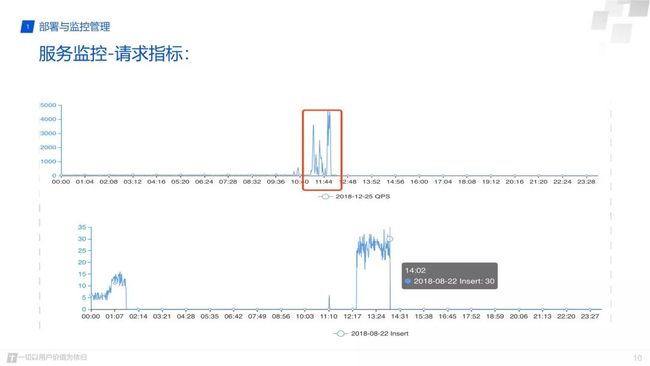
再往下的话是这样的,是一个业务请求指标,这样一个请求指标的监控平台上有的时候也会容易忽略的。比如业务忽然找到平台,说我的查询慢了,我的插入太慢了,为什么?这个时候就有了业务请求指标的话,你可以跟他今天,昨天,上一个小时数据数据去做对比,比如插入的数据是昨天十倍或者是三五倍,那平台如果慢了,就可以明确的说明原因,是业务增长导致的,需要进行优化或者进行扩容,这样对于业务它有一个平台使用的预期,对平台的信任感也会增加,而不会因为只是发现过载了,就去扩容,盲目的去找了一圈原因也不知道为什么过载了。
下面是扫描详情的这种监控,刚才说的前面的那几种监控,例如错误日志暴涨,负载高了,这种情况基本说明平台已经出问题了,更多的时候需要防患于未然。这就需要下面的扫描结果集监控和查询耗时的监控,属于亚健康性状态的监控,就说作为一个 Clickhouse 服务平台,要经常去关注一下,查询的扫描集和结果集,以及它的查询耗时,提前把查询耗时长,结果集大的询亚健康任务找出来进行优化,省得慢查询造成服务的堵塞把平台拖死影响到业务,特别是混合业务的支撑很容易因为, A业务把平台打垮了,B业务找过来说我的业务可用了,比起出现问题后大家手忙脚乱的解决问题,这种亚健康状态监控是非常重要。


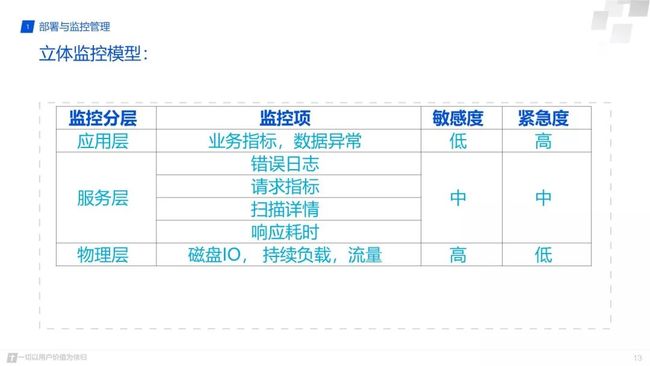
经过上面举例,归纳起来就是这样一个立体监控模型,我们从应用层,服务层,物理层。这样三层去把 Clickhouse 的监控做得更细一点。物理层这一块我刚才没有去举任何的例子了,因为这块东西是大家都比较通用的,就是磁盘的IO,持续的负载,还有流量。刚才有朋友问, Clickhouse 在cpu上面的消耗。其实 Clickhouse 对CPU的性能压榨是很高的,它的CPU偶尔飙到百分之百是在集中计算数据,他不像是事务性并发数据库那样需要支持高并发,因此对于波浪形的CPU彪高的监控并没有太大意义。
更重要的是IO的瓶颈。这种立体监控模型,对敏感度来说的话,肯定是应用层次最低的,就是说应用层出问题了,一定是就是说从底到上物理层,就是说首先是服务器的IO或者负载高了,然后影响到 Clickhouse 的写入慢,或者是查询耗时长了,或者写入失败了,然后再体现在业务指标出问题了,监控敏感度是一层层降低的,但所谓的监控的紧急度的话,反而是反过来是一个从高到低的,我业务处就是应用业务出问题了,一定是要第一时间去响应去解决这个问题, 已经影响到业务了,你的SLA 也就受到了挑战。相对于物理层和服务层的这种层级的监控,出现一些慢SQL,或者一些高负载的情况,我们是可以有时间提前去把这种亚健康的状态解决掉,更好的保障平台的稳定性。
Clockhouse在性能上面是非常优秀的,但是技术圈里面没有银弹,无论什么东西,都需要合理的使用方式才能发挥出它最大的价值,希望大家能够在我的分享中得到一些启发让自己的 Clickhouse 平台更加稳定, 但是他同时就说是也需要大家有一个合理的使用方式和一个合理的管控方式,让这个平台更加稳定。
Clickhouse 在腾讯游戏业务线的应用实践
主要从四个方向进行介绍。
首先是我们游戏数据分析的业务背景,我们为什么要在我们腾讯游戏中做一些数据分析,然后是我们自研的数据分析引擎TGMars,对于其中的画像系统使用的的是 Clickhouse 。我们也有自己的分布式查询画像服务,至于为什么要进行替换,后面也将从第三点进行一些介绍 ,最后简单的介绍下我们平台对 Clickhouse 的使用。
给大家介绍一下,我们腾讯游戏数据分析的一个场景作图。然后从这张图上我们可以看出我们在底层的大数据基础平台上构建了一个pass应用平台,基于我们的pass能力构成了最上层的sass系统,游戏运营小伙伴可以在我们的系统上去实时的进行数据分析,任务配置,营销活动,从而提高我们的游戏服务质量。
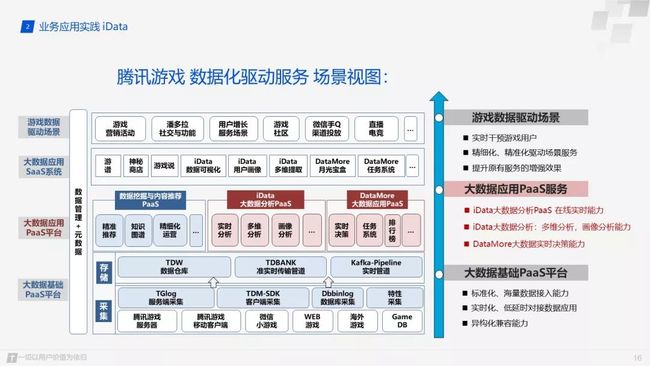
我们首先看下最下层的大数据基础平台,其主要分为数据的采集和存储。如果大家都玩游戏的化可能会有一个明显的感觉,如果游戏有几毫秒的延迟,体验起来就会特别差,所以数据的采集也是我们投入较大的一块。关于存储,我们会将数据落地到数据仓库tdw,同时也有我们也有自己的实时传输管道,保证数据实时的消费落地展示。在我们基础的数据处理平台上我们形成了一个pass化的大数据服务平台,主要分为三个方向。
首先是我们的挖掘分推荐方向,通过对数据的处理训练达到精准的推荐,比较常见的是我们微信游戏中的游戏推荐。接着是我目前所在的idata产品中心,我们主要做游戏的实时数据的在线统计分析,比如我们的实时在线用户,实时游戏收入,实时的创角等,同时我们也提供用户的多维提取和画像分析等,在画像分析中,我们目前就是使用的 Clickhouse 。最后就是我DataMore的大数据应用服务,提供大数据的实时决策能力。
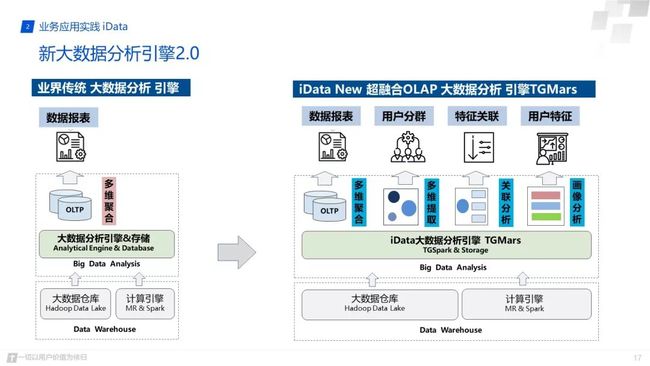
下面对我们的数据分析引擎做些简单的介绍,比对于业界传统的大数据分析引擎,我们可以明显的发现,我们提供更多更强大的能力。传统的大数据分析引擎通过spark或者hadoop对数据进行多维的聚合操作,形成了自己的报表分析结果。我们根据游戏数据的特点构建了自己的快速分析引擎,首先是对spark的定制修改,形成了TGSpark,它在游戏的多维聚合下推过程中具有更好的运行效率,然后我们对数据也进行了特点的处理,构建了自己的存储系统。在我们的底层引擎上我们构建了自研的报表服务,可以像tableau一样进行数据的托拉拽和数据展示。当然多维分析,多维提取和用户画像的功能也是比不可少的。
这里演示下我们的多维提取和透视分析,右上角的是我们的多维提取功能,用户通过指标选择他们想要提取的数据信息 ,比如最近流失的用户和 用户等级大于10级的用户,指标之间也可以进行各种组合,然后在我们的引擎上对结果进行快速的提取,提取到相关信息后用户可以对它进行画像分析,透视分析等操作。

右下图是用户的透视分析,通过对指标的托拉拽,获取用户需要的结果。新的画像系统目前还在灰度阶段,目前只在游戏平台部进行小规模的使用。其实我们旧的画像系统多维下钻分析效率也蛮快的,对于亿级数据的10维以下的分析基本上是秒级分析出结果。
下面对我们的画像系统简单的介绍下,分析我们为什么要对其进行改造。我们画像系统的主要功能就是数据导入和数据的展示,因此整个画像系统的设计也是围绕这两个主要的功能进行的设计。系统主要分为三个方面,调度层,存储节点,执行节点。
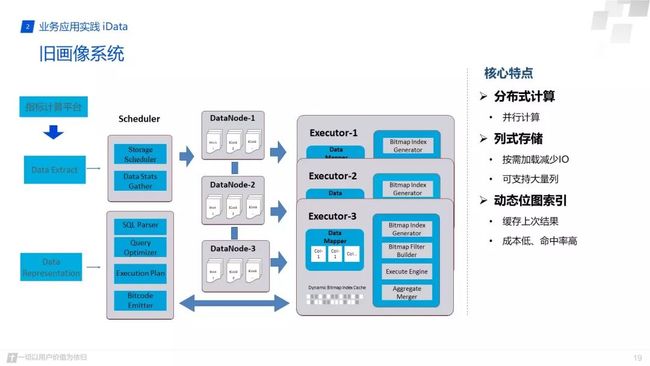
首先进行数据的导入时,我们会在调度服务上选择出主节点,对数据进行切分然后均匀的存储在各存储节点上,同时也会对数据进行一些元信息的统计,方便数据展示时快速获取一些关键信息,存储节点中我们将数据进行列式存储,以及数据的分片处理和压缩等。在数据展示层,用户可以通过托拉拽形成sql,我们主调度层会对sql进行解析,解析完成后我们对sql进行优化,形成我们的DAG执行计划下发到各直接节点进行查询,我们查询时会通过jit将sql转换层字节码信息,加快查询效率。同时在执行层中我们有自己的位图缓存技术,在每次下钻查询过程中会进行动态位图索引匹配,加快查询效率,最终由主节点进行查询结果汇总输出。

我们的分布式查询服务引擎其实也是一个MPP架构模式,查询效率也很快为什么我们还要打算用 Clickhouse 进行替换?主要可能是因为下面几个原因,首先就是它的扩展性比较差,不支持数据的扩展和修改,如果用户在我们系统上提取一个用户包然后进行画像分析,假如是从去年9月10号到今年10月10号提到一些数据包,然后进行分析,过了几天他又想多分析几天的数据,比如从去年9月10号到10月20号,中间就是差10月10号到10月20号的数据,我们不支持的数据增加和修改,所以它只有重新提取,然后重新导入,所以说它的扩展性就是有些问题。
然后数据类型只是数字类型,因为我们为了加快它的查询效率,那时候只做数字类型,因为我们画像时只需要做一些统计类的信息,但是随着业务方需求的变化,单一的数字类型已经不能满足我们的需求了。同时当数据量达到了10亿级别以上,维度分析达到十几维,效率就会有所下降,查询效率就基本上到了分钟级别。
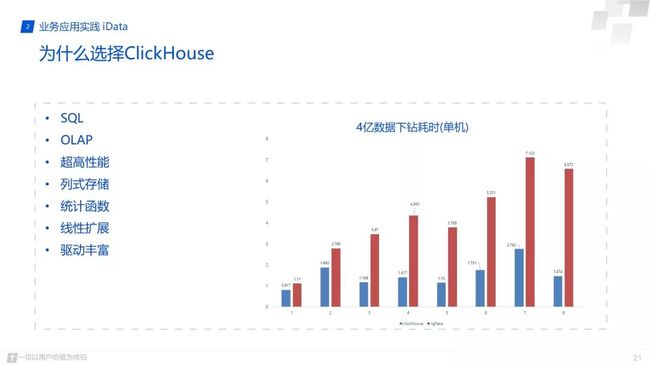
也是因为这些原因我们需要进行一些改造或者替换,后面发现对它改造的代价其实还是蛮大的,我们就去调研了一些主流的olap分析系统,最终我们被 Clickhouse 强大的功能所吸引,也就决定通过它进行替换。首先最重要一点应该可能就是它超高的查询效率,这里给了一个简单的多维下钻分析,在四亿的数据多维下钻分析中,在低纬度的分析中其实画像和 Clickhouse 都能在秒级内查询出结果,因为这里的对比图是单机运行的,所有比实际生产环境还是慢很多的,但是当维度增加时 Clickhouse 的强大之处就展示出来了。
同时 Clickhouse 还有其它一些非常优秀的能力,比如它的SQL能力,聚合函数能力,还有它的目前正在完善的机器学习能力等等。建议大家也可以搭建个环境去体验下,使用起来真的很好,必须吹一下。
然后下面介绍一下,通过一个实例介绍下我们是如何通过 Clickhouse 满足我们以前做起来比较麻烦的需求。比如说map类型的数据处理,我们接到业务方的数据格式是map类型,需要对其中的业务信息进行统计,这个map的key可以理解为游戏代号,value值可以理解为游戏的登录吧,在最开始的游戏登录统计分析中,我们时在tdw上进行计算,通过hive自带的sql对map进行切分然后进行汇总统计,数据量其实也就十几亿吧,但是整个结果计算下来竟然花费了十多分钟吧。
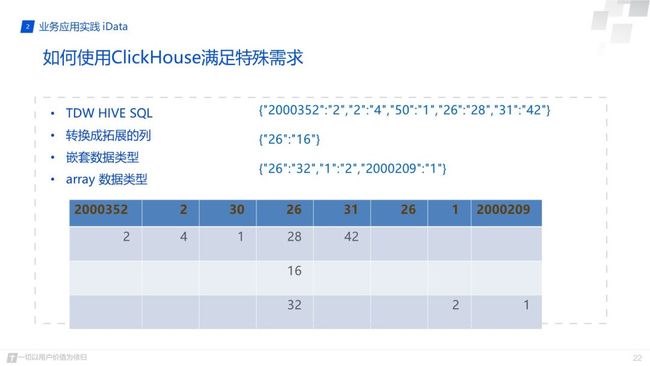
然后我们将数据进行处理导入到我们画像系统中,也就是将map转换成可扩展的列,每个key值对应单独的一列,对每一列进行统计计算,这样查询效率是变快了,几秒中就能查询出结果,但是游戏数据增多我们需求在对映射关系进行一些修改,所有使用起来也就没那么方便。但是我们使用 Clickhouse 后发现处理这样的需求真是不要太简单了,它支持嵌套的数据类型和数组类型,因此我们选择数据导入时将其转换成对应的数据格式进行导入,然后进行一个简单的sql就能查询出最终的结果。
下面这两个sql就是嵌套数据类型和数组类型的查询方式,sql统计非常简单,进行array join就能查询出每个key值sum的结果。通过查询结果我们也可以发现,它的效率也是非常高的,整个查询结果仅仅花费了0.3秒,这还是在我们集群比较小的情况下的结果。同时 Clickhouse 的其它一些函数也能满足我们的一些特殊需求,所有感觉非常棒。

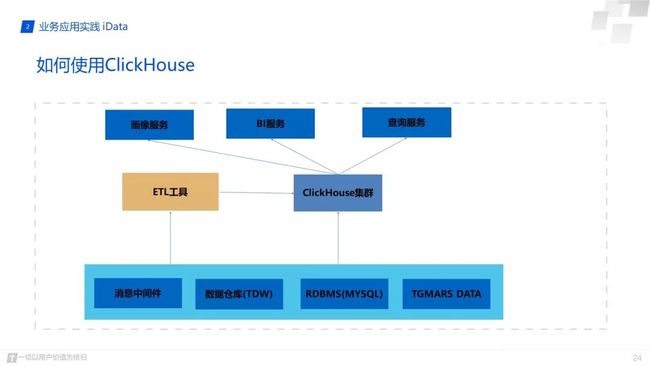
后面说下我们目前对 Clickhouse 的使用。最下面的使我们不同类型的数据源,TDW数据源主要是hdfs出库文件,RDBMS数据源,我们自己的TGMars数据源,还有消息中间件数据源。目前消息中间件这快运用的比较少,因为我们做实时数据有自己的一套druid和storm,运行比较稳定,因此这块我们目前只做了些功能验证测试。接下来就是我们使用较多的tdw和tgmars数据源,我们通过自己的etl服务工具进行数据源的转换,因为 Clickhouse 其实适合大批量小批次的写所有我们通过etl工具进行控制,同时也会对数据进行监控,保证数据完整性。
其实 Clickhouse 也可以直接通过 MySql引擎实现一些小的功能,比如数据库处于不同实例中,我们可以通过 Clickhouse 进行跨实例的join 操作,这块我在测试使用时还是比较感兴趣的。数据导入到 Clickhouse 后,我们就将基于它做一些服务应用开发,比如我们的画像服务,BI系统,以及查询服务。当然我们也将打算通过它做一些增强分析相关的工作,目前第一步正在进行游戏指标的统计,接着可能会进行NLP处理,最终使用 Clickhouse 出结果。
最后就是我们近期的展望,后面会做一些增强分析的工资,就可能会用到更多的机器学习算法,刚刚从俄罗斯团队上的分享中也了解到目前他们也在这方面投入的更多力量,期望后续我们也能很好的使用上。然后就是执行计划的分析,其实这个也不算必须的,因为我们可以从query log中查看到对应的信息,但是用习惯explain后还是比较喜欢这种方式。最后就是集群管理方面,其实集群的搭建和管理还不是那么的方便,希望后续官网提供更好的方案供使用者使用。
以上是关于 Clickhouse 的分享。

文中 PPT 源文件可以点击下方知乎小程序或者 阅读原文 获取!