零基础学nlp【7】 BERT ,transformer应用,预训练模型
零基础学nlp【7】 BERT
论文:Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
1 前言
本来今天准备写 convolutional sequence to sequence 这一篇论文的,但是下午看了两个小时完全没有看懂,然后顺便看了看这篇很新的BERT论文,发现里面使用的就是上一篇文章提到的self-attention模型,于是决定趁热打铁,先看这一篇,有关cnn seq2seq的下次有需要再看吧。。。。。
2 主要内容
文章题目Bert: Pre-training of deep bidirectional transformers for language understanding,这一句话其实就很准确的概括了文章的所有内容。
- 首先是Pre-training,联想在cv领域中的迁移学习,由于一些特定的任务数据集太少无法建立大型的CNN,所以将一些大型的CNN结构先在大型的数据集上训练,使得模型在特征提取,特征理解等方面有了较好的效果,之后再在特定的数据集上进行fine-tuning(即训练,稍微调整参数),用来获得好的效果。这篇文章也是一样,提出的BERT就是一个定义好的模型并且在指定的数据集上进行训练获得了一个基础模型,之后迁移学习,对不同的任务在基础模型上进行fine-tuning,完成指定任务的建模。
- 其次是bidirectional这是论文提出的和之前的几个模型不同之处,即模型的transformer是双向的,这主要是因为用来预训练的任务的特殊性,让其能够得到双向的模型。
- 再是transformer这个就是上一节中提到的self-attention模型,论文使用了这个结构进行模型的构建,具体的参数在3.1提到。
作者就是首先建立了一个 基于transformers搭建的模型,之后再特定的训练任务上训练使得模型具有bidirectional的特性,之后将这个 Pre-training 的模型迁移学习到其他多个任务上进行fine-tuning,得到的结果都表现出了sota的效果!!
3 细节
3.1模型结构
BERT的模型结构主要采用了transformer模块,下图展示了该模块
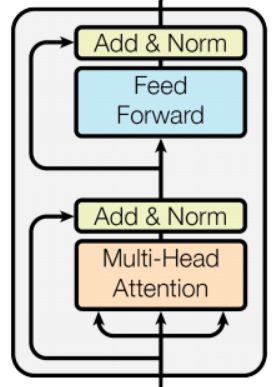
具体的里面每一个小方块的内容参考这篇博客。
对于这样的模块,作者分别构建了BERT(base)模型和BERT(large)模型,base模型是为了和之前的模型作比较(即参数大小差不多相等,说明模型的取胜不是仅依靠模型的大),large模型则获得了更好的效果。两者定义如下:
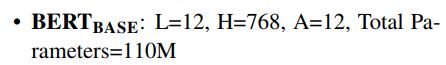
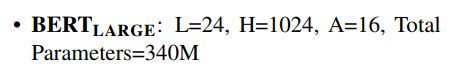
其中L是层数即使用了L个transformer堆叠;H是隐层的维数,在以往很多任务中使用512,现在看来都变大了;A是transformer中multi-head attention 中head的个数,具体的参考之前的文章。
3.2模型的输入
模型的输入的embeddings如下图所示:
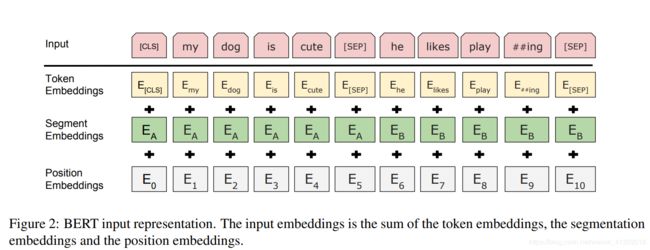
有以下几个特点
- 采用的是wordpiece embeddings 技术,之前没听说过,但是从图上看就是playing分成了play和##ing。才用这个方法建立了包含30000个词的字典。
- 最长输入是512个词,并且用position embeddings加入位置信息
- 每一个输入序列的第一个embedding是一个特殊的类别符,是用于做分类任务的。
- 输入序列可以是一个段落(包含好几个句子),使用【sep】分割,并且在embedding时用segment embeddings标记出(同一个句子的segment embeddings相同)。
3.3预训练
预训练采用了两个任务一个是masked LM,一个是next setence prediction
Masked LM
该任务是随机的将一段话中的几个标记概率性的改变,然后让模型预测这个标记的值,是一种无监督的训练方式,具体的改变如下:

next sentence prediction
预测两句话是不是上下文关系

通过这两个任务的训练,使得得到的transformer可以更好的获得上下文的关系即双向性。
4 结论
之后作者用训练好的大模型在特定的任务上去训练,迁移学习的构造由每个不同的任务决定如下图,结果表明,在所有例子上都得到了最好的效果。
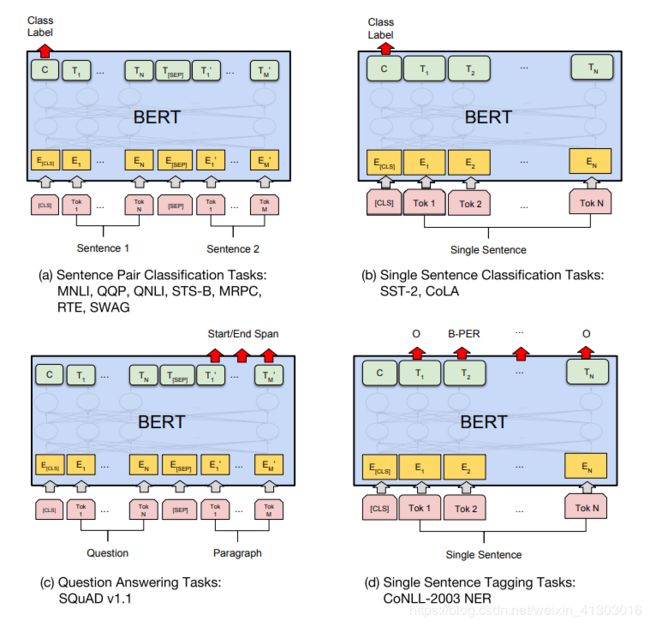
最后作者还做了详细的分析实验,分析这个框架中每个部分对bert整体性能的影响究竟有多大,内容非常充足。
思考
我个人觉得这篇文章非常厉害,从整体思想到训练方法的实际操作都很有创造性,并且文章做的工作也很充足。这篇文章集之前之大成,比如多任务训练,self-attention,迁移学习等技术做成了一个非常好的标准模型。
大家有什么论文可以推荐一下吗,知识图谱方面的也可以!!
【零基础学nlp,争取每天看一篇文章,大家有建议,或者我理解错的地方请批评指正。希望有人能和我一起学!!!!】