Java多线程与并发(3):线程安全性详解
上篇文章多线程基础和线程安全性介绍了在多线程并发的情况下的线程安全问题和出现的底层原因、Java内存模型以及八种同步操作和对应的同步规则,并且在文章结尾介绍了什么是线程安全性以及线程安全性体现的三个方面:原子性、可见性和有序性,本篇主要介绍Java工具类与之体现的线程安全性,之所以介绍这部分内容,就是想让大家了解并且能够熟练运用Java给我们封装好的适合在多线程并发运行的环境下工具类,提高我们对多线程程序的开发效率,并且后续会介绍Java很多与多线程并发相关的工具类,下面我们介绍线程安全性在一Java工具类中的应用。
原子性
先回顾一下原子性:提供了数据的互斥访问,同一时刻只能有一个线程来对它进行操作。结合我在多线程基础和线程安全性的介绍,原子性其实就是确保多个线程在同时要对某个共享数据进行操作的时候,如果第一个线程对这个共享数据拷贝副本到本地内存的时候,就锁定这个数据,防止后续的其他线程对该共享数据进行操作。接下来我们看下Java中的原子性-atomic
java.util.concurrent.atomicatomic包下面有如下这些类,我们抽部分进行实例讲解
(1)java.util.concurrent.atomic.AtomicInteger
先看下面的示例(注释记得看):
package com.mmall.concurrency.example.atomic;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicInteger;
/**
* Created by Administrator on 2019/4/13.
*/
public class AtomicIntegerTest {
public static AtomicInteger atomicInteger = new AtomicInteger(0); // 创建静态的原子类Integer对象初始值为0的
public static int count = 0; // 非原子类 用来对比
public static void main(String[] args) throws Exception{
ExecutorService executorService = Executors.newCachedThreadPool();
CountDownLatch countDownLatch = new CountDownLatch(2000); // 用来控制主线程在所有任务执行完成之后再执行打印结果
for (int i = 0; i < 2000; i++){ // 并发执行对atomicInteger的加一任务的次数
executorService.execute(() -> { // 线程池拿线程去执行任务
atomicInteger.incrementAndGet();
count++;
countDownLatch.countDown();
});
}
countDownLatch.await(); // 在没有完全执行所有任务前,main线程在此处等待
executorService.shutdown(); // 关闭线程池
System.out.println("atomicInteger:" + atomicInteger.get()); // 所有任务执行完之后打印出最后的结果
System.out.println("count:" + count);
}
}
该示例中用到了CountDownLatch类,如果有不了解可以查下相关内容,其实它在该例子中使用的目的就是用来控制在打印结果(main线程做的事)前确保两千次加一的任务(线程池中的线程做的事)都执行完了再打印,不然main线程将for循环执行完后,并发情况下可能还有很多线程处于正在执行加一任务的中间状态(这就涉及到线程所处的几个状态和CPU调度的原因,不难理解),此时main线程继续向下执行打印语句的时候其实是还有很多线程没被执行完,不处于最终算完的状态,所以这个只是用来控制这样的流程的,通过这个例子相信大家也可以体会到CountDownLatch类的用法了。
上面用了AtomicInteger和普通的Int类型的数据进行同步操作来对比,最终结果是:atomicInteger的值稳定为2000,但是count最终的结果都不固定,大家可以贴下代码运行看看,count的值不稳定的原因在多线程基础和线程安全性文章中有一个相似的例子并且详细描述了底层的原因,我们来看下AtomicInteger是如何做到线程安全的原因:
我们先看上面实例执行语句的底层实现(不同版本的JDK会有变化,大家重点关注思路):
我将运行的局部代码贴出来:其中atomicInteger.incrementAndGet()执行的是如下AtomicIntger的incrementAndGet()方法

该方法其实再是执行Unsafe的getAndAddInt方法
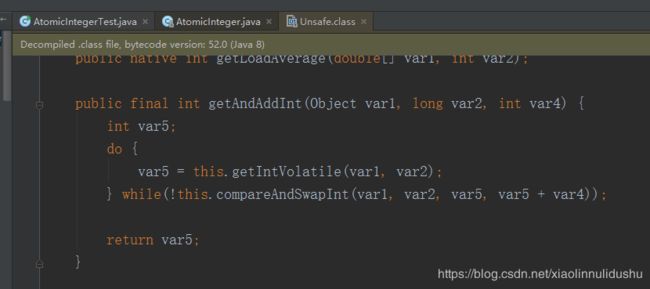
其中还有getIntVolatile和compareAndSwapInt分别是两个native修饰的方法,属于Java底层封装的代码由非Java语言实现:


整个执行流程就是上面这样的,现在我们来解释一下代码,其实代码逻辑很简单,只是我们不有几处是不知道是什么:
- 1.valueOffset是什么
- 2.native修饰的getIntVolatile方法的作用
- 3.native修饰的compareAndSwapInt方法作用
valueOffest是什么:
我们看下AtomicInteger的部分代码:
三个属性字段:Unsafe类型的unsafe、Long类型的valueOffset、和用volatile修饰的整形value,另外静态代码块中是valueOffset赋值,其实Unsafe里面的方法都是native修饰的方法,具体可以查询这个类的方法详解,我们来看下网上的一段对unsafe.objectFieldOffset的功能介绍:
RednaxelaFX 写道
sun.misc.Unsafe是JDK内部用的工具类。它通过暴露一些Java意义上说“不安全”的功能给Java层代码,来让JDK能够更多的使用Java代码来实现一些原本是平台相关的、需要使用native语言(例如C或C++)才可以实现的功能。该类不应该在JDK核心类库之外使用。
JVM的实现可以自由选择如何实现Java对象的“布局”,也就是在内存里Java对象的各个部分放在哪里,包括对象的实例字段和一些元数据之类。sun.misc.Unsafe里关于对象字段访问的方法把对象布局抽象出来,它提供了objectFieldOffset()方法用于获取某个字段相对Java对象的“起始地址”的偏移量,也提供了getInt、getLong、getObject之类的方法可以使用前面获取的偏移量来访问某个Java对象的某个字段。
每个JVM都有自己的方式来实现Java对象的布局。Oracle/Sun HotSpot VM所使用的Java对象布局可以参考这篇博客:http://www.codeinstructions.com/2008/12/java-objects-memory-structure.html
(这篇内容其实并不是太完整但只是入门凑合看看是够了。另外它只针对32位的JDK6的HotSpot VM的默认配置。)
同事Aleksey Shipilev专门写了个小工具来显示Java对象的布局:
https://github.com/shipilev/java-object-layout
总结一下就是valueOffset的值就是一个内存地址的偏移量,是实例属性value相对于它所在的实例对象(AtomicInteger)的”起始地址“的偏移量,或者来说就理解为我们在上面示例测试代码中构造AtomicInteger的时候,堆内存中会为这个对象分配一块内存空间,而valueOffset就是描述其中实例属性value所在这个实例对象的这块内存空间的具体内存位置(如果对JVM内存模型内容不够了解可以看我的那几篇文章),其作用会在下面介绍。
native修饰的getIntVolatile方法的作用
具体方法描述:
public native int getIntVolatile(Object var1, long var2);该方法有两个参数:Object var1, 和long var2
- var1:就是我们构造的AtomicInteger实例对象
- var2:就是valueOffset,我们已经知道它是什么了
作用:就是根据这两个参数去主内存(多线程基础和线程安全性里的主内存)中找当前value在内存的实时值,valueOffset的作用就是在这里用到。
native修饰的compareAndSwapInt方法作用
这里就有个Java的名词缩写:CAS(Compare and Swap),意思就是比较并且替换,当然替换是有条件的
具体方法描述:
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);- var1:就是我们构造的AtomicInteger实例对象
- var2:就是valueOffset,我们已经知道它是什么了
- var4:int数值,用来和内存的值进行对比
- var5:int数值,用来给内存value值赋的新值(替换)
作用:就是用来比较并且替换内存中的值的,具体点就是拿var4和用var1、var2找到内存中value的值做比较,如果相等则将var5的值替换为value的值,并且返回true,否则不替换并且返回false。
到这一步之后我们就剩下解释getAndAddInt方法啦,这个方法里面的逻辑也就是确保了AtomicInteger是线程安全的
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}该方法是个do-while循环,首先调getIntVolatile去主内中拿最新的value的值,然后调compareAndSwapInt尝试进行比较并且替换的操作,如果成功则结束循环,否则又去主内存中拿最新的value的值再进行比较并且替换的尝试,一直这样循环,从而做到了线程安全,大家仔细体会体会,我们模拟一下两个线程同时进入到这个方法里面的场景:
线程A和线程B
- 线程A执行到this.getIntVolatile(var1, var2)拿到内存中此时value的值并赋值给了var5。
- 此时CPU切换让线程B执行,从给var5赋值并且执行到了this.compareAndSwapInt(var1, var2, var5, var5 + var4),此时B拿到的var5和内存中的value值对比是相等的,所以就执行了替换并返回true然后结束了do-while循环,此时主内存中的value的值为var5+var4的新值。
- 然后CPU切换到A线程,此时A执行this.compareAndSwapInt(var1, var2, var5, var5 + var4),在比较的时候,发现自己带的var5是与此时的value的值不相等,所以会再次循环去调用var5 = this.getIntVolatile(var1, var2),再去比较才会结束循环。
到这里我们就结合并发的例子将AtomicInteger的原理讲完啦,atmoic下的常用的AtomicBoolean、AtomicLong其实逻辑和原理都是类似的,大家如果把上面的讲解看懂后再去分析另外的这几个的源码就很简单了,我们就不逐个介绍了,大家可以看看源码或者也参照上面的并发例子写一个相关的示例。
另外提一下atomic里面还有个LongAdder的类,该类也是线程安全的,作用和AtomicLong是一样的,那为什么又会多出一个一样功能的类呢?当然牛逼的前人是有他们更深入全面的考虑滴。首先我们来分析一下AtomicLong的这种实现思路的缺点:底层是通过do-while循环去进行CAS,在高并发的情况下有些线程是会长时间在do-while死循环的,这就存在性能问题,所有并发的线程都是对这一个数据在尝试CAS操作(也可以形容为单点操作嘛),竞争就非常激励同时也会降低性能,那LongAdder这个类就是为了缓解这种压力和提升效率而设计的,它的总体思路就分散高并发情况下各个线程对数据的操作,其实最底层也是进行CAS的操作,我在这里就不详细介绍该类的源码和详细的设计思路啦,不然本文篇幅会增加不少,大家可以去网上搜下AtomicLong相关的文章(https://www.jianshu.com/p/30d328e9353b 我看了这篇文章),源码是非常值得学习和反复研读,可以好好体会其中的设计思路,我们也应该向前人学习这种态度,对事情更加全面周全的考虑。
下面再看下其他的几个atomic包下面的几个举例。
(2)java.util.concurrent.atomic.AtomicReference和java.util.concurrent.atomic.AtomicIntegerFieldUpdater
先看下面的示例:
package com.mmall.concurrency.example.atomic;
import java.util.concurrent.atomic.AtomicReference;
/**
* Created by Administrator on 2019/4/13.
*/
public class AtomicReferenceTest {
private static AtomicReference atomicReference = new AtomicReference<>(0);
public static void main(String[] args) {
atomicReference.compareAndSet(0, 2); // 如果当前值是0,则更新为2
atomicReference.compareAndSet(0, 1);
atomicReference.compareAndSet(1, 3);
atomicReference.compareAndSet(2, 4);
atomicReference.compareAndSet(3, 5);
System.out.println("atomicReference:" + atomicReference);
}
}
package com.mmall.concurrency.example.atomic;
import lombok.Getter;
import java.util.concurrent.atomic.AtomicIntegerFieldUpdater;
/**
* Created by Administrator on 2019/4/13.
*/
public class AtomicIntegerFieldUpdaterTest {
private static AtomicIntegerFieldUpdater atomicIntegerFieldUpdater =
AtomicIntegerFieldUpdater.newUpdater(AtomicIntegerFieldUpdaterTest.class, "countField"); // 指定该对象中countField字段名
public volatile int countField = 1;
public static void main(String[] args) {
AtomicIntegerFieldUpdaterTest atomicIntegerFieldUpdaterTest = new AtomicIntegerFieldUpdaterTest();
if (atomicIntegerFieldUpdater.compareAndSet(atomicIntegerFieldUpdaterTest, 1, 2)) {
System.out.println("1.curCountField update success:" + atomicIntegerFieldUpdaterTest.countField);
}
if (atomicIntegerFieldUpdater.compareAndSet(atomicIntegerFieldUpdaterTest, 1, 3)) {
System.out.println("2.curCountField update success:" + atomicIntegerFieldUpdaterTest.countField);
} else {
System.out.println("3.curCountField update failed:" + atomicIntegerFieldUpdaterTest.countField);
}
}
}
这个类其实都是比较简单的,通过看源码底层也是CAS的操作,具体在实际的场景中可以考虑用到这样两个类。
atomic包下面的类就介绍完啦,大家了解了CAS的底层原理,其实也就体现了线程安全性-原子性,CAS底层原理没有说对数据的互斥访问,而是体现了同一时刻只有一个线程能对这个共享数据操作,从而也就体现了原子性而做到线程安全。另外在Java中还提供了对数据的互斥访问机制来实现原子性,那就是锁!这是高并发情况下为了做到线程安全的一个主要的机制,也是挺大一块内容所在,在java中有两大类锁机制:
- sysnchronized :依赖JVM,本文先讲解这个
- Lock :依赖特殊的CPU指令,通过代码实现(比如ReentrantLock),这个我们后续文章会详细介绍
sysnchronized的使用
sysnchronized关键字有四种修饰方式:
- 修饰类:括号括起来的部分,作用于所有实例对象
- 修饰代码块:大括号括起来的代码,作用于调用的对象
- 修饰静态方法:整个静态方法,作用于所有实例对象
- 修饰方法:整个静态方法,作用于所有对象
来看个简单应用例子:
package com.mmall.concurrency.example.sync;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* Created by Administrator on 2019/4/14.
*/
public class SynchronizedTest {
public static int countSafe = 0;
public static int countUnSafe = 0;
public static void main(String[] args) throws Exception {
SynchronizedTest synchronizedTest1 = new SynchronizedTest();
SynchronizedTest synchronizedTest2 = new SynchronizedTest();
ExecutorService executorService = Executors.newCachedThreadPool();
CountDownLatch countDownLatch = new CountDownLatch(1000);
for (int i = 0; i < 1000; i++){
executorService.execute(() ->{
synchronizedTest1.test1();
synchronizedTest2.test2();
countDownLatch.countDown();
});
}
countDownLatch.await();
System.out.println("countSafe : " + countSafe);
System.out.println("countUnSafe : " + countUnSafe);
executorService.shutdown();
}
public void test1(){
synchronized (this){ // 同步代码块
for (int i = 0; i < 10; i++){
countSafe = countSafe + 1;
}
}
}
public void test2(){
for (int i = 0; i < 10; i++){
countUnSafe = countUnSafe + 1;
}
}
public synchronized static void test3(){ // 修饰静态方法
for (int i = 0; i < 10; i++){
countSafe = countSafe + 1;
}
}
public void test4(){ // 修饰一个类
synchronized (SynchronizedTest.class){ // 修饰一个类,用这个类的类类型作为锁对象
for (int i = 0; i < 10; i++){
countSafe = countSafe + 1;
}
}
}
public synchronized void test5(){ // 修饰一个方法
for (int i = 0; i < 10; i++){
countSafe = countSafe + 1;
}
}
}
test1的方法当中加了synchronized同步代码块后,for这段代码块就会被互斥访问,在整个执行for时间段内只会被成功加锁的那个线程执行,即使在执行期间被切换到其它的线程来尝试执行,但是都因为拿不到锁而被阻塞等待,每个线程都会依次执行玩for循环,对里面的共享数据countSafe的访问是互斥的,同一时刻只会有一个线程访问它,这也就起到了线程安全,而test2最终并发执行之后countUnSafe的值是不稳定的,没有加互斥访问的限制,其实和之前的非线程安全例子的原理是一样
其实对于初学者来说,synchronized的四种修饰方式并没有什么问题,主要是不太了解像test1()方法的synchronized(this)中的this的值的作用(也就是上面说的作用范围),大家可以就把它当做一把锁,对于所有要进入到synchronized这块同步的内容里面的时候,都要先去尝试拿这把锁,如果拿到了才能进入到同步代码里面进行执行,如果没有拿到就只能在外面乖乖等着,那这里就要注意一点就是如果要做到同一时刻只能一个线程进入到同步代码块里面的话,那这把锁肯定只能是唯一的一把(对于这块代码来说),如果有多把那就起不到线程安全的作用了,比如下面这个方法就是非线程安全的:
public void test(){
synchronized (new Object()){ // 每次都是一把新的锁
for (int i = 0; i < 10; i++){
countSafe = countSafe + 1;
}
}
}我们来分析上面例子中每个方法其对应的锁对象:
1.现在我们来看上面例子中的test1方法,进入用synchronized修饰的代码块的锁为this,表示为执行本方法实例对象,那如果写成下面的形式的话,每次都实例一个新的对象去执行test1方法,虽然操作的都是共享数据countSafe,但是每次执行的时候所有线程都能够拿到对应的锁进入到同步代码块,也是非线程安全的。

2.再来看下test4方法中锁为SynchronizedTest.class,也就是一个类类型,看过我虚拟机相关的文章的同学应该知道一个类的类类型(Class)在整个程序运行期间是唯一一个的,那如果我们继续想上面截图那样,在for循环里面执行:
new SynchronizedTest().test4();即使每个线程在执行的时候都是创建新的实例去执行具体的test4()方法,最终也会是线程安全的,因为锁只有一个。
3.对于初学者来说修饰静态方法的test3()和修饰实例方法test5()会有个疑问:这两种方式的锁呢?,其实大家仔细想想就知道了,静态方法属于对应的类的,实例方法是属于对应的实例(这里说的有点粗糙),所以很容易就知道test3的方式也是有锁的,对应的锁和test4是一样的,test5和test1的锁是一样的,为对应执行该方法的实例对象。
到这里就简单介绍完了synchronized的用法,本篇文章没有详细介绍synchronized的底层原理,主要是介绍线程安全性中原子性的互斥机制实现的方式之一,有兴趣的同学可以去网上查下资料,有很多详细的文章讲解,后续有时间我也会更新的。下面我们介绍线程安全性——可见性
可见性
先回顾一下可见性:一个线程对主内存的数据修改可以及时的被其他线程观察到。
导致共享变量在线程间不可见的原因可以规律以下三点:
- 线程交叉执行
- 重排序结合线程交叉执行
- 共享变量更新后的值没有在工作内存与主存间及时更新
在这里提一下前面介绍的synchronized在JMM的两条规定,这个规定也就起到让共享变量达到可见性的目的:
- 线程解锁前,必须把共享变量的最新值刷到主内存。
- 线程加锁前,先从被加锁区域相关的共享变量先从自己工作内存当中清空,从而在线程要用到这些共享变量时需要先从主内存中重新读取最新的值。
通过这两条规定达到了可见性,并起到到了线程安全。
说起可见性在Java中最直接就能想到关键字volatile
可见性-volatile
首先大家脑海里要重新回顾一下:每个线程都有独占的内存区域,如操作栈、本地变量表等。线程本地内存保存了引用变量在堆内存中的副本,线程对变量的所有操作都在本地内存区域中进行,执行结束后再同步到堆内存中去。这里必然有一个时间差,在这个时间差内,该线程对副本的操作,对于其他线程都是不可见的。这些在前面的文章是有详细讲述过
通过加入内存屏障和禁止重排序优化来实现,具体看下面两条,好好体会:
- 对volatile修饰着的共享变量被进行写操作时,会在写操作指令后加入一条store屏障指令(就是必须会执行的指令),这样该共享变量在某个线程的工作内存中被修改后会将最新的值刷新到主内存当中。
- 对volatile修饰着的共享变量在被读操作时,会在读操作指令前加入一条load屏障指令,这样该共享变量在被某个线程访问的时候,会先从主内存中拿这个共享变量的最新值拷贝到自己的工作内存当中。(上面的store和load在上一篇博客有详细介绍)
总结来说,被volatile修饰的变量,被线程更新之后会立即更新到主内存当中,被线程读的时候,不管该线程工作内存是否有这个共享变量的副本,都将会失效并且重新从主内存当中拷贝最新的值,这样的实现机制也就保证了被volatile修饰的变量达到可见性。
在这里大家思考一个问题,用volatitle修饰的变量,能保证在多线程并发操作的情况下是线程安全的吗?我们先通过实际的例子来看结果现象,再来分析原因:
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class VolatileTest {
public volatile static int count = 0; // 用volatile修饰的静态变量,初始值为0
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
CountDownLatch countDownLatch = new CountDownLatch(2000);
for (int i = 0; i < 2000; i++){
executorService.execute(() -> {
count++;
countDownLatch.countDown();
});
}
countDownLatch.await();
System.out.println("count:" + count);
executorService.shutdown(); // 关闭线程池
}
}执行多次发现最终count的值不稳定,所以结果是非线程安全的,为啥呢?首先大家要明白一个点就是count++这一句代码其实是有三步指令的执行:
- 获取当前count的值
- 进行count+1操作
- 将最新的值同步到主内存
通过上面对用volatile修饰的变量的讲解,我们来分析这三步时,可以肯定的是第一步获取的count的值是当前主内存中最新的值,在第二步执行完之后第三步肯定是会被执行的,也就是说用volatile修饰的变量在多线程高并发情况下能确保每个线程对该变量的访问时都是拿到最新的值,也能确保每个线程操作完之后都能立即同步更新到主内存当中,但是导致非线程安全的原因是因为例子中被volatile修饰的count并不能保证其原子性,我们来分析一下:某一个时刻线程A进行了1、2两步,但是还没来得及执行3此时CPU被切换到了线程B,线程B不管自己的工作内存当中有没有count的副本但是因为被volatile所修饰此时还是会去主内存中拿最新的,而这个时候拿到的并不是线程A操作后的值,也就是他们两个各自的一次+1操作会被覆盖掉一次,导致非线程安全。
所以用volatile修饰的变量,只能保证其可见性,但是并不能保证其原子性,这也是经常在面试的时候被问到的一个小问题,从volatile的作用来看,它一般用来修饰主要被读的共享变量,哪些数据主要用来读的呢?比如状态标记的变量就可以在高并发的情况下用volatile修饰,因为这类数据主要是用来供多线程读的,对其写操作都是个别的线程在特殊的阶段进行的,很难出现线程安全问题。
有序性
这个有序其实是对指令来说的,大家知道CPU执行程序的时候底层其实都是通过执行一条条程序所对应的计算机指令,就比如在上面介绍可见性时中的例子,计算机执行count++这句代码的时候CPU其实是执行上面所说的3条指令,而在Java内存模型中,是允许编译器和处理器对指令进行重排序,那什么是指令重排序呢?其实就是一条条指令在被执行之前,其执行的顺序可能会被重新排列(这个是对于我们程序代码的书写顺序来说的,我们知道书写的代码都是从前往后执行的嘛),指令重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性,导致线程安全问题,而我们介绍过的volatile、synchronized和后面即将介绍的Lock都能确保程序的有序性而保证在多线程的情况下线程安全,其中synchronized和后面介绍的lock锁都是针对在多线程高并发的情况下对共享数据的操作时确保同一时刻只能有一个线程对其进行操作,从另外一面来看在这一时刻对这个共享数据来说其实也就是单线程的执行过程,即使在被加锁的这段期间发生了指令重排序,也是不会因为指令重排序而造成线程安全问题的,因为该期间只有单个线程在执行。用volatile修饰的变量能确保对一个变量的写操作指令先行发生与后面对这个变量的读操作,这也保证了写和读这两条指令的有序性,另外用volatile还可以防止JVM进行指令重排序优化,这个我将会在后面文章中讲单例模式时用例子详细讲解。
关于有序性还有一个happens-before原则,大家可以去网上查一下相关的资料,在这里就不详细讲啦!
总结
本篇文章介绍了线程安全性的原子性、可见性和有序性,并在期间介绍了原子性相关的Java的atomic包下面的原子性相关的工具类以及对应底层实现的CAS思想、synchronized,然后是可见性并着重介绍了Java关键字volatile,最后简单介绍了有序性一些基本的概念,本片文章主要是为后续学习多线程高并发相关内容打下最基础的知识,其实后面相关的内容都是从这些基础知识出发的,所以大家好好理解和体会本篇文章,大家加油!