目的
- 加载遥感图像的.mat数据进行呈图显示
- 将.mat的数据转化为python后续算法处理的csv文件
- 存储训练模型,观察分类效果,在图中显示与原图对比
方法
Refer:spectral python官网
使用超强的spectral包!
目的1 - 代码
加载遥感图像的.mat数据进行呈图显示
part1 . 加载数据
#refer:https://github.com/KGPML/Hyperspectral/blob/master/Decoder_Spatial_CNN.ipynb
# 自行装spectral包,专门为光谱图像设计
import matplotlib.pyplot as plt
import numpy as np
from scipy.io import loadmat
import spectral
# # 获取mat格式的数据,loadmat输出的是dict,所以需要进行定位
input_image = loadmat('/Users/mrlevo/Desktop/exp_data/MAT_DATA/KSC.mat')['KSC']
output_image = loadmat('/Users/mrlevo/Desktop/exp_data/MAT_DATA/KSC_gt.mat')['KSC_gt']
# # input_image.shape#:(610, 340, 103)
# # output_image.shape#:(610, 340)
# # np.unique(output_image) # array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8)
part2. 统计类元素个数
# 统计每类样本所含个数
dict_k = {}
for i in range(output_image.shape[0]):
for j in range(output_image.shape[1]):
#if output_image[i][j] in [m for m in range(1,17)]:
if output_image[i][j] in [1, 2, 3, 4, 5, 6, 7, 8, 9,10,11,12,13]:
if output_image[i][j] not in dict_k:
dict_k[output_image[i][j]]=0
dict_k[output_image[i][j]] +=1
print dict_k
print reduce(lambda x,y:x+y,dict_k.values())
# {1: 6631, 2: 18649, 3: 2099, 4: 3064, 5: 1345, 6: 5029, 7: 1330, 8: 3682, 9: 947}
# 42776
part3. 光谱图像展示
# 展示地物
ground_truth = spectral.imshow(classes = output_image.astype(int),figsize =(9,9))
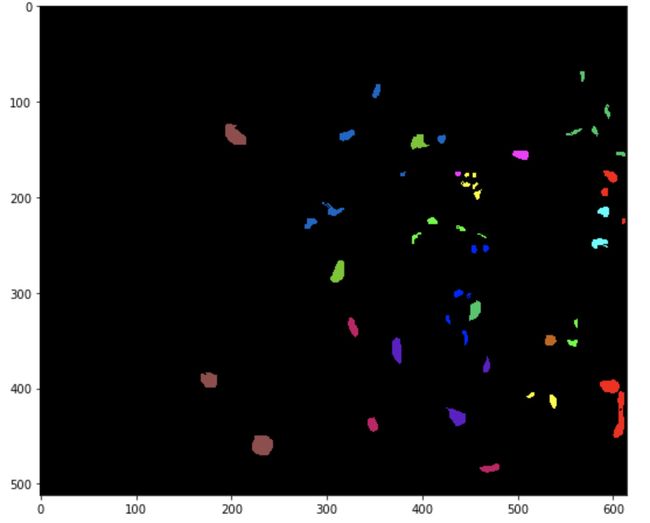
image
part4. 不同类用不同颜色
ksc_color =np.array([[255,255,255],
[184,40,99],
[74,77,145],
[35,102,193],
[238,110,105],
[117,249,76],
[114,251,253],
[126,196,59],
[234,65,247],
[141,79,77],
[183,40,99],
[0,39,245],
[90,196,111],
])
ground_truth = spectral.imshow(classes = output_image.astype(int),figsize =(9,9),colors=ksc_color)
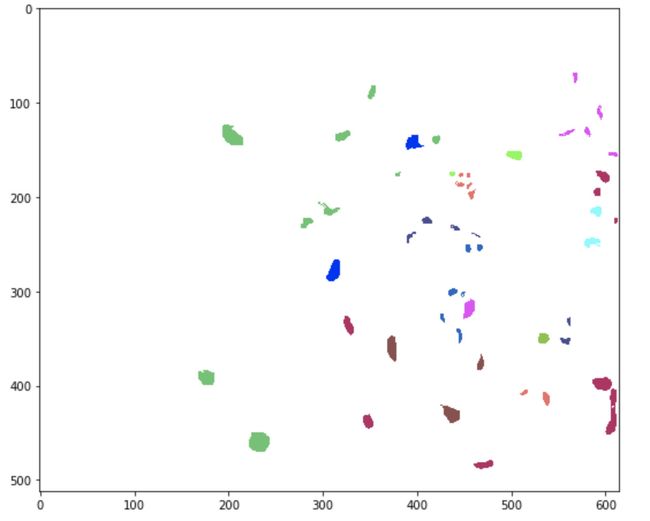
image
目的2 - 代码
将.mat的数据转化为python后续算法处理的csv文件,以ksc数据为例,接上一个目的代码
part1. 重构需要用到的类
# 除掉 0 这个非分类的类,把所有需要分类的元素提取出来
need_label = np.zeros([output_image.shape[0],output_image.shape[1]])
for i in range(output_image.shape[0]):
for j in range(output_image.shape[1]):
if output_image[i][j] != 0:
#if output_image[i][j] in [1,2,3,4,5,6,7,8,9]:
need_label[i][j] = output_image[i][j]
new_datawithlabel_list = []
for i in range(output_image.shape[0]):
for j in range(output_image.shape[1]):
if need_label[i][j] != 0:
c2l = list(input_image[i][j])
c2l.append(need_label[i][j])
new_datawithlabel_list.append(c2l)
new_datawithlabel_array = np.array(new_datawithlabel_list) # new_datawithlabel_array.shape (5211,177),包含了数据维度和标签维度,数据176维度,也就是176个波段,最后177列是标签维
Part2. 标准化数据并存储
data_D = preprocessing.StandardScaler().fit_transform(new_datawithlabel_array[:,:-1])
#data_D = preprocessing.MinMaxScaler().fit_transform(new_datawithlabel_array[:,:-1])
data_L = new_datawithlabel_array[:,-1]
# 将结果存档后续处理
import pandas as pd
new = np.column_stack((data_D,data_L))
new_ = pd.DataFrame(new)
new_.to_csv('/Users/mrlevo/Desktop/exp_data/KSC.csv',header=False,index=False)
目的3 - 代码
存储训练模型,观察分类效果,在图中显示与原图对比
part1. 训练模型并存储模型
# 验证高光谱数据的分类结果,并在图中进行分类结果的标记
# Author:哈士奇说喵
import joblib
from sklearn.model_selection import KFold
from sklearn.model_selection import train_test_split
import numpy as np
from sklearn.svm import SVC
from sklearn import metrics
from sklearn import preprocessing
import pandas as pd
# 导入数据集切割训练与测试数据
data = pd.read_csv('/Users/mrlevo/Desktop/exp_data/KSC.csv',header=None)
data = data.as_matrix()
data_D = data[:,:-1]
data_L = data[:,-1]
data_train, data_test, label_train, label_test = train_test_split(data_D,data_L,test_size=0.5)
# 模型训练与拟合
clf = SVC(kernel='rbf',gamma=0.125,C=16)
clf.fit(data_train,label_train)
pred = clf.predict(data_test)
accuracy = metrics.accuracy_score(label_test, pred)*100
print accuracy
# 存储结果学习模型,方便之后的调用
joblib.dump(clf, "KSC_MODEL.m")
part2. 模型预测在图中标记类
# mat文件的导入
import matplotlib.pyplot as plt
import numpy as np
from scipy.io import loadmat
import spectral
# KSC
input_image = loadmat('/Users/mrlevo/Desktop/exp_data/MAT_DATA/KSC.mat')['KSC']
output_image = loadmat('/Users/mrlevo/Desktop/exp_data/MAT_DATA/KSC_gt.mat')['KSC_gt']
testdata = np.genfromtxt('/Users/mrlevo/Desktop/exp_data/KSC.csv',delimiter=',')
data_test = testdata[:,:-1]
label_test = testdata[:,-1]
# /Users/mrlevo/Desktop/CBD_HC_MCLU_MODEL.m
clf = joblib.load("KSC_MODEL.m")
predict_label = clf.predict(data_test)
accuracy = metrics.accuracy_score(label_test, predict_label)*100
print accuracy # 97.1022836308
# 将预测的结果匹配到图像中
new_show = np.zeros((output_image.shape[0],output_image.shape[1]))
k = 0
for i in range(output_image.shape[0]):
for j in range(output_image.shape[1]):
if output_image[i][j] != 0 :
new_show[i][j] = predict_label[k]
k +=1
# print new_show.shape
# 展示地物
ground_truth = spectral.imshow(classes = output_image.astype(int),figsize =(9,9))
ground_predict = spectral.imshow(classes = new_show.astype(int), figsize =(9,9))

image
左图为原始数据图,右图为分类后的图,可以看到精度非常高了,有些分错的像素点可以看到右图左边缘有些地物不是很纯净,杂入了其他的类颜色,就是对该像素的数据分错了类
Pay Attention
- 测试代码在jupyter上进行测试
- 涉及课题知识,做高光谱图像的小伙伴会比较有用,Indian Pines和PaviaU 的数据一个道理
Indian Pines

image
PaviaU

image
致谢
- spectral
- Paper: An Active Learning Framework for Hyperspectral Image Classification Using Hierarchical Segmentation