爬虫开发日记(第一天)
爬虫开发日记--第一天
- 概念知识
- 分类
- 工作原理
- robots协议
- 编解码
- HTTP相关知识
- 浏览器发送http请求的过程
- url形式:
- HTTP请求报文格式
- HTTP常见请求头
- GET和POST的区别
- requests模块
- 安装
- 基本使用
- 常用属性
- 带header的请求
- user_agent池
- 请求传递参数
- 练习:使用面向对象的写法爬取百度贴吧1-5页的数据
概念知识
爬虫的实质:就是模拟浏览器客户端发送网络请求,接收请求对应的响应,一种按照一定的规则,自动地抓取互联网信息的程序。
只要是浏览器能做的事情,原则上爬虫都能做
分类
-
通用爬虫:通常指搜索引擎和大型Web服务提供商。但是,需要注意的是,通用搜索引擎具有很大的局限性:
(1) 通用搜索引擎所返回的网页里90%的内容无用。
(2) 图片、数据库、音频、视频多媒体的内容通用搜索引擎无能为力
(3) 不同用户搜索的目的不全相同,但是返回内容相同 -
聚焦爬虫:针对特定网站的爬虫,定向的获取某方面数据的爬虫, 聚焦爬虫又分为以下三种具体的:
(1) 累积式爬虫:从开始到结束,不断爬取
(2) 增量式爬虫:只爬取新增的更新的数据
(3) Deep web爬虫:针对Ajax请求的数据
工作原理
- 通用爬虫的工作流程

- 聚焦爬虫的工作流程
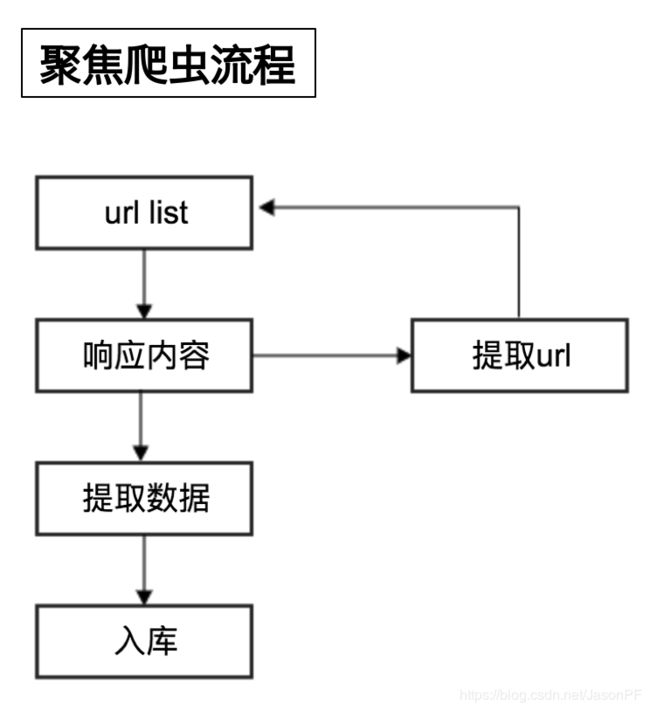
robots协议
网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,但它仅仅是道德层面上的约束
需要注意的是:爬虫不遵守robots协议
编解码
在Python3中:
-
bytes类型 通过decode() 转换为 str类型
-
str类型 通过encode() 转换为 bytes类型
编码方式解码方式必须一样,否则出现乱码
所有编解码以Unicode作为中间量可以随意转换
HTTP相关知识

http: 超文本传输协议, 默认端口80
https:HTTP + SSL(安全套接子层) ca证书,默认端口443
虽然HTTPS比HTTP更安全, 但是性能更低
浏览器发送http请求的过程

浏览器会主动请求js,css等内容,js会修改页面的内容,js也可以重新发送请求,最后浏览器渲染出来的内容在elements中,其中包含css,图片,js,url地址对应的响应等。
但是在爬虫中,爬虫只会请求url地址,对应的拿到url地址对应的响应
浏览器渲染出来的页面和爬虫请求的页面并不一样
所以在爬虫中,需要以url地址对应的响应为准来进行数据的提取
url形式:
scheme://host[:port#]/path/…/[?query-string][#anchor]
scheme:协议(例如:http, https, ftp) host:服务器的IP地址或者域名
port:服务器的端口(如果是走协议默认端口,80 or 443) path:访问资源的路径
query-string:参数,发送给http服务器的数据 anchor:锚(跳转到网页的指定锚点位置)
http://localhost:4000/file/part01/1.2.html
http://item.jd.com/11936238.html#product-detailurl地址中是否包含锚点对响应没有影响
HTTP请求报文格式
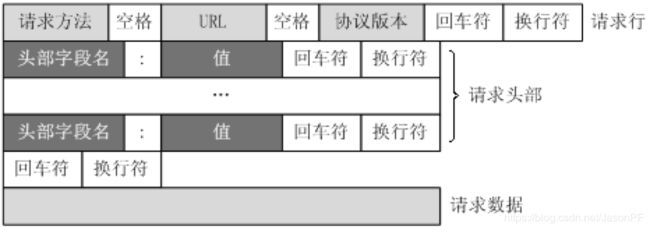
HTTP常见请求头
- Host (主机和端口号)
- Connection (链接类型)
- Upgrade-Insecure-Requests (升级为HTTPS请求)
- User-Agent (浏览器名称)
- Accept (传输文件类型)
- Referer (页面跳转处)
- Accept-Encoding(文件编解码格式)
- Cookie (Cookie)
- x-requested-with :XMLHttpRequest (是Ajax 异步请求)
GET和POST的区别

requests模块
requests的底层实现就是urllib
requests在python2 和python3中通用,方法完全一样
requests简单易用
Requests能够自动帮助我们解压(gzip压缩的等)网页内容
安装
创建虚拟环境
mkvirtualenv pyspider3 -p python3
安装
pip install requests
基本使用
- 目标url
- 发送请求
- 根据响应对象, 获取数据
- 保存
import requests
# 1.目标url
url = 'https://www.baidu.com'
# 2.发送请求
response = requests.get(url)
print(response) # 响应对象 200
# 3.根据响应对象 获取数据
# data = response.text # str类型, 编码不准确, 通常不用
data = response.content.decode('utf-8') # 字节类型
# 3.保存
with open('01-baidu.html', 'w') as f:
f.write(data)
常用属性
response.text
respones.content
response.status_code
response.request.headers
response.headers
response.request._cookies
response.cookies
response.text 和response.content的区别
-
response.text
类型:str
解码类型: 根据HTTP 头部对响应的编码作出有根据的推测,推测的文本编码
如何修改编码方式:response.encoding=”gbk” -
response.content
类型:bytes
解码类型: 没有指定
如何修改编码方式:response.content.deocde(“utf8”)
获取网页源码的通用方式:
response.content.decode()
response.content.decode(“GBK”)
response.text
以上三种方法从前往后尝试,能够100%的解决所有网页解码的问题
所以:更推荐使用response.content.deocde()的方式获取响应的html页面
带header的请求
模拟浏览器,欺骗服务器,获取和浏览器一致的内容
headers的形式是一个字典:
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
使用方法:
requests.get(url,headers=headers)
user_agent池
# user_agent池
USER_AGENT_LIST = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3"
]
headers = {
'User-Agent': random.choice(USER_AGENT_LIST)
}
random.choice() 随机从列表中取出一个值
请求传递参数
两种方式:
- 直接拼接url
- 使用params参数
import requests
if __name__ == '__main__':
# 第一种方式, 直接拼接url
# 目标url
# url = 'https://www.baidu.com/s?wd="美女"'
url = 'https://www.baidu.com/s'
# 第二种方式, 使用params参数
params = {
'wd': '美女'
}
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"
}
# 发起请求
response = requests.get(url, headers=headers, params=params)
# 获取数据
data = response.content.decode('utf-8')
# 保存数据
with open('04baidu.html', 'w') as f:
f.write(data)
练习:使用面向对象的写法爬取百度贴吧1-5页的数据
import requests
class BaiDuTieBaSpider(object):
def __init__(self):
self.name = input('请输入贴吧的名字: ')
self.start_page = int(input('请输入起始页: '))
self.stop_page = int(input('请输入截止页: '))
self.url = 'https://tieba.baidu.com/f'
self.headers = {"User-Agent": "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)"}
def send_request(self, params):
response = requests.get(self.url, headers=self.headers, params=params)
data = response.content
return data
def save_data(self, data, page):
file_path = 'TieBa/' + str(page) + '.html'
print('正在抓取第{}页~'.format(page))
with open(file_path, 'wb') as f:
f.write(data)
def start(self):
for page in range(self.start_page, self.stop_page + 1):
# 发送请求
params = {
'kw': self.name,
'pn': (page - 1) * 50
}
data = self.send_request(params)
# 保存数据
self.save_data(data, page)
if __name__ == '__main__':
tool = BaiDuTieBaSpider()
tool.start()