概述
注意力模型已经推出,在CV和NLP领域刮起一股旋风,尤其是兼顾整体与细节,短期与长期,在各种比赛上攻城掠地,本文将介绍一个用于处理时间序列的相关模型。探索注意力模型在股票市场的应用,进而对股票价格进行预测。
说明
- 前端采用pytorch
- 数据采用tushare
- Encoder-Decoder模型
依赖
- pytorch
- Tushare
- numpy
.Encoder-Decoder模型
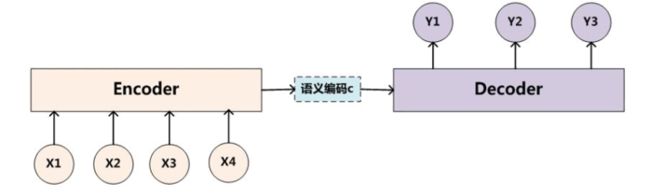
所谓encoder-decoder模型,又叫做编码-解码模型。这是一种应用于seq2seq问题的模型。其需求来自于自然语言处理,因为处理语言和语音的时候输入长度不定,输出长度也不一定,曾经给训练带来困难。而Encoder-Decoder的出现解决了这个问题,成为不定长输出输出的标准做法。那么seq2seq又是什么呢?简单的说,就是根据一个输入序列x,来生成另一个输出序列y。seq2seq有很多的应用,例如翻译,文档摘取,问答系统等等。在翻译中,输入序列是待翻译的文本,输出序列是翻译后的文本;在问答系统中,输入序列是提出的问题,而输出序列是答案。
为了解决seq2seq问题,有人提出了encoder-decoder模型,也就是编码-解码模型。所谓编码,就是将输入序列转化成一个固定长度的向量;解码,就是将之前生成的固定向量再转化成输出序列。
Seq
编码器
import torch
from torch import nn
from torch.autograd import Variable
import torch.nn.functional as F
ENCODER_HIDDEN_SIZE = 64
DECODER_HIDDEN_SIZE = 64
DRIVING = 'stocks/600600csv'
TARGET = 'stocks/600612.csv'
class AttnEncoder(nn.Module):
def __init__(self, input_size, hidden_size, time_step):
super(AttnEncoder, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.T = time_step
self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size, num_layers=1)
self.attn1 = nn.Linear(in_features=2 * hidden_size, out_features=self.T)
self.attn2 = nn.Linear(in_features=self.T, out_features=self.T)
self.tanh = nn.Tanh()
self.attn3 = nn.Linear(in_features=self.T, out_features=1)
#self.attn = nn.Sequential(attn1, attn2, nn.Tanh(), attn3)
def forward(self, driving_x):
batch_size = driving_x.size(0)
# 尺寸 batch_size * time_step * hidden_size
code = self.init_variable(batch_size, self.T, self.hidden_size)
# 初始化隐藏状态
h = self.init_variable(1, batch_size, self.hidden_size)
# 初始化LSTM cell状态
s = self.init_variable(1, batch_size, self.hidden_size)
for t in range(self.T):
# batch_size * input_size * (2 * hidden_size + time_step)
x = torch.cat((self.embedding_hidden(h), self.embedding_hidden(s)), 2)
z1 = self.attn1(x)
z2 = self.attn2(driving_x.permute(0, 2, 1))
x = z1 + z2
# batch_size * input_size * 1
z3 = self.attn3(self.tanh(x))
if batch_size > 1:
attn_w = F.softmax(z3.view(batch_size, self.input_size), dim=1)
else:
attn_w = self.init_variable(batch_size, self.input_size) + 1
# batch_size * input_size
weighted_x = torch.mul(attn_w, driving_x[:, t, :])
_, states = self.lstm(weighted_x.unsqueeze(0), (h, s))
h = states[0]
s = states[1]
# encoding result
# batch_size * time_step * encoder_hidden_size
code[:, t, :] = h
return code
def init_variable(self, *args):
zero_tensor = torch.zeros(args)
if torch.cuda.is_available():
zero_tensor = zero_tensor.cuda()
return Variable(zero_tensor)
def embedding_hidden(self, x):
return x.repeat(self.input_size, 1, 1).permute(1, 0, 2)
解码器
class AttnDecoder(nn.Module):
def __init__(self, code_hidden_size, hidden_size, time_step):
super(AttnDecoder, self).__init__()
self.code_hidden_size = code_hidden_size
self.hidden_size = hidden_size
self.T = time_step
self.attn1 = nn.Linear(in_features=2 * hidden_size, out_features=code_hidden_size)
self.attn2 = nn.Linear(in_features=code_hidden_size, out_features=code_hidden_size)
self.tanh = nn.Tanh()
self.attn3 = nn.Linear(in_features=code_hidden_size, out_features=1)
self.lstm = nn.LSTM(input_size=1, hidden_size=self.hidden_size)
self.tilde = nn.Linear(in_features=self.code_hidden_size + 1, out_features=1)
self.fc1 = nn.Linear(in_features=code_hidden_size + hidden_size, out_features=hidden_size)
self.fc2 = nn.Linear(in_features=hidden_size, out_features=1)
def forward(self, h, y_seq):
batch_size = h.size(0)
d = self.init_variable(1, batch_size, self.hidden_size)
s = self.init_variable(1, batch_size, self.hidden_size)
ct = self.init_variable(batch_size, self.hidden_size)
for t in range(self.T):
# batch_size * time_step * (encoder_hidden_size + decoder_hidden_size)
x = torch.cat((self.embedding_hidden(d), self.embedding_hidden(s)), 2)
z1 = self.attn1(x)
z2 = self.attn2(h)
x = z1 + z2
# batch_size * time_step * 1
z3 = self.attn3(self.tanh(x))
if batch_size > 1:
beta_t = F.softmax(z3.view(batch_size, -1), dim=1)
else:
beta_t = self.init_variable(batch_size, self.code_hidden_size) + 1
# batch_size * encoder_hidden_size
ct = torch.bmm(beta_t.unsqueeze(1), h).squeeze(1)
if t < self.T - 1:
yc = torch.cat((y_seq[:, t].unsqueeze(1), ct), dim=1)
y_tilde = self.tilde(yc)
_, states = self.lstm(y_tilde.unsqueeze(0), (d, s))
d = states[0]
s = states[1]
# batch_size * 1
y_res = self.fc2(self.fc1(torch.cat((d.squeeze(0), ct), dim=1)))
return y_res
def init_variable(self, *args):
zero_tensor = torch.zeros(args)
if torch.cuda.is_available():
zero_tensor = zero_tensor.cuda()
return Variable(zero_tensor)
def embedding_hidden(self, x):
return x.repeat(self.T, 1, 1).permute(1, 0, 2)
数据集
先使用csv文件,等比赛结束后,更改数据
import numpy as np
import pandas as pd
import math
class Dataset:
def __init__(self, driving_csv, target_csv, T, split_ratio=0.8, normalized=False):
stock_frame1 = pd.read_csv(driving_csv)
stock_frame2 = pd.read_csv(target_csv)
if stock_frame1.shape[0] > stock_frame2.shape[0]:
stock_frame1 = self.crop_stock(stock_frame1, stock_frame2['Date'][0]).reset_index()
else:
stock_frame2 = self.crop_stock(stock_frame2, stock_frame1['Date'][0]).reset_index()
stock_frame1 = stock_frame1['Close'].fillna(method='pad')
stock_frame2 = stock_frame2['Close'].fillna(method='pad')
self.train_size = int(split_ratio * (stock_frame2.shape[0] - T - 1))
self.test_size = stock_frame2.shape[0] - T - 1 - self.train_size
if normalized:
stock_frame2 = stock_frame2 - stock_frame2.mean()
self.X, self.y, self.y_seq = self.time_series_gen(stock_frame1, stock_frame2, T)
#self.X = self.percent_normalization(self.X)
#self.y = self.percent_normalization(self.y)
#self.y_seq = self.percent_normalization(self.y_seq)
def get_size(self):
return self.train_size, self.test_size
def get_num_features(self):
return self.X.shape[1]
def get_train_set(self):
return self.X[:self.train_size], self.y[:self.train_size], self.y_seq[:self.train_size]
def get_test_set(self):
return self.X[self.train_size:], self.y[self.train_size:], self.y_seq[self.train_size:]
def time_series_gen(self, X, y, T):
ts_x, ts_y, ts_y_seq = [], [], []
for i in range(len(X) - T - 1):
last = i + T
ts_x.append(X[i: last])
ts_y.append(y[last])
ts_y_seq.append(y[i: last])
return np.array(ts_x), np.array(ts_y), np.array(ts_y_seq)
def crop_stock(self, df, date):
start = df.loc[df['Date'] == date].index[0]
return df[start: ]
def log_normalization(self, X):
X_norm = np.zeros(X.shape[0])
X_norm[0] = 0
for i in range(1, X.shape[0]):
X_norm[i] = math.log(X[i] / X[i-1])
return X_norm
def percent_normalization(self, X):
if len(X.shape) == 2:
X_norm = np.zeros((X.shape[0], X.shape[1]))
for i in range(1, X.shape[0]):
X_norm[i, 0] = 0
X_norm[i] = np.true_divide(X[i] - X[i-1], X[i-1])
else:
X_norm = np.zeros(X.shape[0])
X_norm[0] = 0
for i in range(1, X.shape[0]):
X_norm[i] = (X[i] - X[i-1]) / X[i]
return X_norm
import argparse
import torch
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
import numpy as np
from torch import nn
from torch.autograd import Variable
from model import AttnEncoder, AttnDecoder
from dataset import Dataset
from torch import optim
class Trainer:
def __init__(self, driving, target, time_step, split, lr):
self.dataset = Dataset(driving, target, time_step, split)
self.encoder = AttnEncoder(input_size=self.dataset.get_num_features(), hidden_size=ENCODER_HIDDEN_SIZE, time_step=time_step)
self.decoder = AttnDecoder(code_hidden_size=ENCODER_HIDDEN_SIZE, hidden_size=DECODER_HIDDEN_SIZE, time_step=time_step)
if torch.cuda.is_available():
self.encoder = self.encoder.cuda()
self.decoder = self.decoder.cuda()
self.encoder_optim = optim.Adam(self.encoder.parameters(), lr)
self.decoder_optim = optim.Adam(self.decoder.parameters(), lr)
self.loss_func = nn.MSELoss()
self.train_size, self.test_size = self.dataset.get_size()
def train_minibatch(self, num_epochs, batch_size, interval):
x_train, y_train, y_seq_train = self.dataset.get_train_set()
for epoch in range(num_epochs):
i = 0
loss_sum = 0
while (i < self.train_size):
self.encoder_optim.zero_grad()
self.decoder_optim.zero_grad()
batch_end = i + batch_size
if (batch_end >= self.train_size):
batch_end = self.train_size
var_x = self.to_variable(x_train[i: batch_end])
var_y = self.to_variable(y_train[i: batch_end])
var_y_seq = self.to_variable(y_seq_train[i: batch_end])
if var_x.dim() == 2:
var_x = var_x.unsqueeze(2)
code = self.encoder(var_x)
y_res = self.decoder(code, var_y_seq)
loss = self.loss_func(y_res, var_y)
loss.backward()
self.encoder_optim.step()
self.decoder_optim.step()
# print('[%d], loss is %f' % (epoch, 10000 * loss.data[0]))
loss_sum += loss.data[0]
i = batch_end
print('epoch [%d] finished, the average loss is %f' % (epoch, loss_sum))
if (epoch + 1) % (interval) == 0 or epoch + 1 == num_epochs:
torch.save(self.encoder.state_dict(), 'models/encoder' + str(epoch + 1) + '-norm' + '.model')
torch.save(self.decoder.state_dict(), 'models/decoder' + str(epoch + 1) + '-norm' + '.model')
def test(self, num_epochs, batch_size):
x_train, y_train, y_seq_train = self.dataset.get_train_set()
x_test, y_test, y_seq_test = self.dataset.get_test_set()
y_pred_train = self.predict(x_train, y_train, y_seq_train, batch_size)
y_pred_test = self.predict(x_test, y_test, y_seq_test, batch_size)
plt.figure(figsize=(8,6), dpi=100)
plt.plot(range(2000, self.train_size), y_train[2000:], label='train truth', color='black')
plt.plot(range(self.train_size, self.train_size + self.test_size), y_test, label='ground truth', color='black')
plt.plot(range(2000, self.train_size), y_pred_train[2000:], label='predicted train', color='red')
plt.plot(range(self.train_size, self.train_size + self.test_size), y_pred_test, label='predicted test', color='blue')
plt.xlabel('Days')
plt.ylabel('Stock price of 600600.(¥)')
plt.savefig('results/res-' + str(num_epochs) +'-' + str(batch_size) + '.png')
def predict(self, x, y, y_seq, batch_size):
y_pred = np.zeros(x.shape[0])
i = 0
while (i < x.shape[0]):
batch_end = i + batch_size
if batch_end > x.shape[0]:
batch_end = x.shape[0]
var_x_input = self.to_variable(x[i: batch_end])
var_y_input = self.to_variable(y_seq[i: batch_end])
if var_x_input.dim() == 2:
var_x_input = var_x_input.unsqueeze(2)
code = self.encoder(var_x_input)
y_res = self.decoder(code, var_y_input)
for j in range(i, batch_end):
y_pred[j] = y_res[j - i, -1]
i = batch_end
return y_pred
def load_model(self, encoder_path, decoder_path):
self.encoder.load_state_dict(torch.load(encoder_path, map_location=lambda storage, loc: storage))
self.decoder.load_state_dict(torch.load(decoder_path, map_location=lambda storage, loc: storage))
def to_variable(self, x):
if torch.cuda.is_available():
return Variable(torch.from_numpy(x).float()).cuda()
else:
return Variable(torch.from_numpy(x).float())
def getArgParser():
parser = argparse.ArgumentParser(description='Train the dual-stage attention-based model on stock')
parser.add_argument(
'-e', '--epoch', type=int, default=1,
help='the number of epochs')
parser.add_argument(
'-b', '--batch', type=int, default=1,
help='the mini-batch size')
parser.add_argument(
'-s', '--split', type=float, default=0.8,
help='the split ratio of validation set')
parser.add_argument(
'-i', '--interval', type=int, default=1,
help='save models every interval epoch')
parser.add_argument(
'-l', '--lrate', type=float, default=0.01,
help='learning rate')
parser.add_argument(
'-t', '--test', action='store_true',
help='train or test')
parser.add_argument(
'-m', '--model', type=str, default='',
help='the model name(after encoder/decoder)'
)
return parser
if __name__ == '__main__':
args = getArgParser().parse_args()
num_epochs = args.epoch
batch_size = args.batch
split = args.split
interval = args.interval
lr = args.lrate
test = args.test
mname = args.model
trainer = Trainer(DRIVING, TARGET, 10, split, lr)
if not test:
trainer.train_minibatch(num_epochs, batch_size, interval)
else:
encoder_name = 'models/encoder' + mname + '.model'
decoder_name = 'models/decoder' + mname + '.model'
trainer.load_model(encoder_name, decoder_name)
trainer.test(mname, batch_size)
最近有比赛,比赛后将此模型优化,加入点乘注意力等。