自动上色论文《Deep Exemplar-based Colorization》(1)
今天看了一篇纯数学的论文,感觉很晕。
数学是一定要学的,不过先看看网络结构的去想想有没有什么好的idea。
论文链接:https://arxiv.org/pdf/1807.06587.pdf
Abstract
本文作者第一个提出基于基于样例的上色的论文,给一幅黑白图片一张参考的彩色图片,就可以通过本文的方式进行自动上色。与其他基于学习的上色算法不同,用户可以通过使用不同的参考图片对结果上色。为了进一步减少人工挑选参考样本的工作量,系统自动地采用图片检索算法推荐包含语义信息和光照信息的图片。从而,自动上色可以由只选择最佳参考图片来完成。
一、Introduction
上色问题需要符合语义且看起来比较美观。这个问题实际上是病态的,其答案也是模棱两可,因为上色问题不止会有一种结果(比如人衣服的颜色)。由于没有一个定量的答案,所以人工干预在上色问题中是必要的。
引导自动上色问题的人工手段实际上有两种方法:用户通过不同颜色涂鸦控制颜色,或者使用一张样例图片。第一种方法对用户的要求极高,而第二种方法生成的结果的质量在很大程度上取决于参考图片的选择。
更可靠的方法是使用一个巨大的参考图像的数据库,通过数据库来搜索最相似的图片或者像素进行着色。近年来,通过深度学习方法生成大规模数据集的方式已经取得了很显著的效果。自动上色问题被视为回归问题,并通过深度学习方式直接解决这一问题。通过某些论文可以在不使用用户涂鸦或者参考图片的情况下自动生成图片。但是对应的问题有如下两点:
1、这些方法不支持多模态问题,往往使用更具优势的颜色上色,从而限制了用户交互。
2、这种方法必须使用海量的数据,需要列出所有可能的结果。
因此,现有的方法的最佳的目标是:同时实现人机交互的控制能力和学习能力的鲁棒性。
近年来有些论文将颜色点或笔画形式的手动提示添加到深度神经网络,以便为用户提供的涂鸦时可能需要的颜色,实际上就是一种对用户交互性的提升。这种方式促进了传统的“涂鸦控制颜色”的方法,并可以获得更自然的图片。然而,涂鸦对于获得高质量的结果仍然是必不可少的,因此仍然涉及一定量的试错试验。
本文作者使用一种混合的方法,提出了第一种基于样本的局部着色的深度学习方法。与已有的着色网络不同,本文的网络允许通过选用不同的参考图片进行对输出图片的控制。如下图所示,我们的参考图片可能与目标图片完全不相似,但我们可以通过网络生成符合语义且相对美观的图片。
本文通过卷积神经网络直接选择生成黑白图像对应生成的颜色图片。我们的方法在质量上优于现有的基于样例图片的方法。主要成就为两个关键的子网络。
首先,相似性子网络(Similarity Sub-net)是一个预处理步骤,获得端到端网络的输入图片。它通过在灰度图像对象识别任务上预训练的VGG-19网络来实现对参考图片和目标图片的语义相似性的测量。
之后,着色子网络(Colorization sub-net)提供一种更为普遍的上色策略。它采用多任务学习来训练两个不同的分支,他们共享相同的网络和权重,但是使用两种不同的损失函数:
(1)色度损失:它使得网络有选择性的传播相关patch或者像素的正确的参考颜色,从而满足色度一致性
(2)感知损失:实现高级特征之间色彩的紧密匹配,这样即使在参考图片中没有适当的匹配区域的情况下,也能确保从大规模的数据中学习如何适当的着色。

(图2,我们的目的是可以把正确的颜色传播(有点像颜色的传染?2333)到语义相同的色块或者像素上,并通过在大规模数据集上学习来预测自然的颜色)
因此,我们的方法可以大大放宽对参照图片的限制性要求,而之前的基于范例样本的学习策略对这一要求较高。
为了引导用户进行有效的参考图片的选择,系统基于图像检索算法推荐最有可能的参考图片。它利用高级的语义信息和低级的亮度信息来搜索ImageNet数据集中最相似的图像。在这种推荐系统的帮助下,我们的方法可以作为全自动的着色系统。实验表明,我们的自动着色算法在数量和质量上优于现有的自动着色方法,甚至可以为最先进的交互方法产生相对高质量的结果。我们的方法也可以被应用于视频着色。
Contributions:
(1)自动着色问题的第一种基于样例的深度学习方法,它允许可控性并且对参考图片的选择具有鲁棒性。
(2)设计了一种新颖的端到端双分支网络架构,当可靠的参考图片不可用时,它学习合理的局部着色生成有意义的参考图片,并进行合理的颜色预测。
(3)设计用于参考图片推荐的参考图像检索算法,利用它我们还可以实现全自动着色。
(4)具有转移性,即使使用自然图片进行训练,我们也可以应用于非自然图片。
(5)可以扩展到视频的自动着色问题。
二、Related Work
2019.3.7补充。
作者列举了现有的着色方法的种类及方法。
(1)基于人工涂画彩色笔画的着色方法(Scribble-based Colorization):
这类方法会在灰度图片中通过画一些具有颜色的笔画来把颜色扩展到整个图片上,这里只用到了些低级别的相似性的指标。2004年就有学者提出,在相同的照度(luminance)下应该有相同的颜色,并且通过马尔科夫随机场方法来把这些稀疏的色彩扩展到整张图片上去。后来扩展到了使用纹理相似性、内在距离,以及利用边界信息以防止颜色泄漏。
这类方式的缺陷:需要大量的手工标注方式,以及需要标注人员有很良好的专业的涂色能力。
(2)基于参考图片的着色方法(Exemplar-based Colorization)
这类方法通过向输入灰度图像提供非常相似的参考图片来减少大量的手工标注图片。最早的工作通过匹配全局颜色统计来自动着色。由于忽略了空间像素信息,因此该方法在许多情况下结果并不令人满意。为了得到更准确的局部信息,使用了不同的获得局部信息的方法,包括分割区域级别信息(segmented-region level),超像素级别信息(super-pixel level)。然而,在具有显著的强度和内容的变化的情况下,计算获得的相似性度量的低级特征(比如SIFT特征、Gabor小波特征)很容易出错。最近,两篇论文利用从预训练的VGG-19网络中提取的深度特征,从而在语义相关但视觉上看起来不同的图像之间进行可靠的匹配,然后利用它进行样式转移[Liao et al。 2017]和颜色转移[He et al。 2017年]。然而,所有这些基于示例的方法都必须依赖于找到一个好的参考图片,这仍然是用户的一大阻碍。通过对比,我们的方法对于任何给定的参考图片都是稳健的,这要归功于我们的深度网络能够从大规模图像数据中学习自然的颜色分布。
(3)基于学习方式的着色方法(Learning-based Colorization)
有几种技术完全依赖于学习方法来产生着色图像。2015年有学者将着色问题定义为线性系统并学习其参数。另外有学者连接了几个预定义的特征,并将它们输入到三层完全连接的神经网络中。最近,一些端到端的学习方法利用CNN自动提取特征并预测颜色结果。这些网络的关键差异是损失函数(例如,图像重建L2损失,分类损失,考虑多模态着色的L1 + GAN损失)。所有这些网络都是从大规模数据中学习的,不需要任何用户干预。然而,它们只为每个输入产生一个合理的结果,而着色问题的本质是多模态不确定性的不适定问题。
(4)多种方法合并的着色方法(Hybrid Colorization)
为了获得更为合适的着色方案,目前有学者将基于人工图画方式的可控性和基于学习方式的稳健性相结合,比如使用提供的色点或笔画。在本文中,我们将参考图片而非笔画或色点引入着色网络中,因为给定一张相似的着色图片样本对于未经训练的用户而言更为直观。除此以外,我们也可以使用我们的图像检索系统来自动的实现参考图片的选择。
三、基于样例的自动上色网络
我们的目的是通过一张参考图片给黑白图片上色。更具体地,我们的目标是将参考图片的颜色应用于存在语义相关内容的目标图片,并且举一反三,即使图片或区域毫无关联,也可以获得一个不错的结果。我们需要解决以下两个问题:
我们很难测量参考图片和目标图片的语义相关性,更何况参考图片是彩色的,而目标图片是黑白图片。我们使用gray-VGG-19网络,只使用Lab图片的L层来提取特征,并计算特征的差异。
很难通过基于相似度规则的度量来定义手动挑选的规则我们使用一种端到端的网络可以同时选择颜色并传播的方式。为了解决无法完全恢复颜色这个问题,我们的网络将改为预测大规模数据中未对齐对象的主色。
我们的pipeline如下所示:
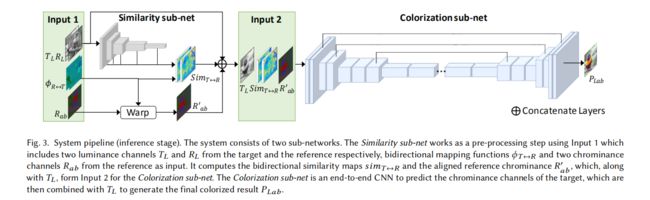
我们使用CIE Lab颜色空间,因为这一空间在感知上是线性的。因此,每个图片可以分为亮度空间L空间,以及色度空间a,b维度。输入为灰度图片的亮度 T L ∈ R H × W × 1 T_L \in\mathcal{R}^{H\times W\times{1}} TL∈RH×W×1,彩色参考图片 R L a b ∈ R H × W × 3 R_{Lab} \in\mathcal{R}^{H\times W\times{3}} RLab∈RH×W×3,以及二者之间的双向映射函数。可当做是像素的映射函数, ϕ T → R \phi_{T\to R} ϕT→R指的是灰度图片对彩色图片的映射, ϕ R → T \phi_{R\to T} ϕR→T指的是彩色图片对灰色图片的映射。为简单起见,我们假设输入图像输入图片的维度是相同的。我们的网络结构包括两个子网络。相似性子网络计算目标图片和参考图片的相似度,从而获得一个双向的映射函数 s i m T ↔ R sim_{T\leftrightarrow R} simT↔R;着色子网络把 s i m T ↔ R , T L 和 R a b ′ sim_{T\leftrightarrow R},T_L和R_{ab}' simT↔R,TL和Rab′作为输入,输出预测的色度空间ab的值 P a b ∈ R H × W × 2 P_{ab}\in\mathcal{R}^{H\times W\times{2}} Pab∈RH×W×2,最后通过 P L = T L P_L=T_L PL=TL直接获得 P L a b P_{Lab} PLab,即我们想要得到的彩色的图片。
相似性子网络
计算像素间相似度的时候先将 T L T_L TL与 R L a b R_{Lab} RLab对齐,本文使用Deep Image Analogy方法进行像素的密集匹配,这种方式可以可以匹配语义上相同但看起来不一样的图片。本文使用VGG-19的中间输出结果作为特征图。由于VGG-19的识别能力会随着图片由彩色变成灰度图而下降,我们在灰度图上训练VGG-19网络,使得性能得到提升。
我们分别将 T L T_L TL与 R L R_L RL输入到我们的VGG-19的网络上,获得5级特征图金字塔( i = 1 , 2 , . . . , 5 i=1,2,...,5 i=1,2,...,5)。第i层的特征图是由 r e l u { i } 1 relu\{i\}_1 relu{i}1层提取获得。随着层数的增加,这些特征的空间分辨率逐渐变大。我们将所有的特征向量图上采样到与输入图片相同分辨率,然后将 T L T_L TL和 R L R_L RL的上采样后的特征图分别以 { F T L i } i = 1 , 2 , . . . , 5 \{F_{T_L}^i\}_{i=1,2,...,5} {FTLi}i=1,2,...,5和 { F R L i } i = 1 , 2 , . . . , 5 \{F_{R_L}^i\}_{i=1,2,...,5} {FRLi}i=1,2,...,5表示。双向相似性映射 s i m T → R sim_{T\rightarrow R} simT→R和 s i m T ← R sim_{T\leftarrow R} simT←R在 F T i F_T^i FTi和 F R i F_R^i FRi之间基于每个像素p上计算:
s i m T → R i ( P ) = d ( F T i ( P ) , F R i ( ϕ T → R ( P ) ) ) sim_{T\rightarrow R}^i(P) =d(F_T^i(P),F_R^i(\phi_{T\to R}(P))) simT→Ri(P)=d(FTi(P),FRi(ϕT→R(P)))
s i m R → T i ( P ) = d ( F T i ( ϕ R → T ( ϕ T → R ( P ) ) ) , F R i ( ϕ T → R ( P ) ) ) sim_{R\rightarrow T}^i(P) =d(F_T^i(\phi_{R\to T}(\phi_{T\to R}(P))),F_R^i(\phi_{T\to R}(P))) simR→Ti(P)=d(FTi(ϕR→T(ϕT→R(P))),FRi(ϕT→R(P)))
我们使用余弦相似性,因为余弦相似性在度量特征一致性的时候效果更好,则距离函数定义为 d ( x , y ) = x T y ∣ ∣ x ∣ ∣ ∣ ∣ y ∣ ∣ d(x,y) =\frac{x^Ty}{||x||||y||} d(x,y)=∣∣x∣∣∣∣y∣∣xTy。前向相似性映射 s i m T → R sim_{T\to R} simT→R反映了从 T L T_L TL到 R L R_L RL的匹配置信度, s i m R → T sim_{R\to T} simR→T测量了在反向方向上的匹配精度。
着色子网络
本文作者设计一卷积神经网络从而实现自动上色。设 C \pmb{C} CCC是我们的卷积神经网络,我们的输入是一个13层的feature map,包括灰度图片的亮度层 T L T_L TL,对齐后的参考图片 R a b ′ ( P ) = R a b ( ϕ T → R ( P ) ) R_{ab}'(P) = R_{ab}(\phi_{T\to R}(P)) Rab′(P)=Rab(ϕT→R(P)),以及双向映射函数 s i m T ↔ R sim_{T\leftrightarrow R} simT↔R,可以预测到预测的图片ab色度的值 P a b P_{ab} Pab。后面介绍损失函数,网络架构以及训练的详细操作。
损失函数:
在基于样例的自动着色问题中,直接计算 P a b P_{ab} Pab和 T a b T_{ab} Tab之间的损失函数是不正确的,因为 P a b P_{ab} Pab应该由 R a b ′ R_{ab}' Rab′来控制决定。因此,我们的目标函数需要由两个必要条件决定:首先,我们更喜欢在输出中应用可靠的参考图片的颜色,从而使其忠实于参考图片。 其次,即使没有可靠的参考图片的颜色,我们也鼓励着色结果是自然的。
因此,我们使用一种包括两个分支的多任务的网络:色度的分支和感知性的分支。这两种分支都使用相同的网络结构 C \pmb{C} CCC和权重 θ \theta θ,但是使用不同的损失函数。参数 α \alpha α用于指示两个分支之间的相对权重。
在色度分支上,神经网络通过目标图片 T L T_L TL和参考图片 R L R_L RL关联性来学习如何正确的选择性的传播参照图片的颜色。尽管如此,训练这一网络并不是容易的事情:一方面,网络不可能直接通过 R a b ′ R_{ab}' Rab′进行训练:在目标图片上,参考色度是扭曲的,因此这个对应的ground truth是未知的。
本文的方法是通过双向映射函数从ground truth的色度中重建一个假的参考的目标图片 T a b ′ T_{ab}' Tab′,比如 T a b ′ = T a b ( ϕ R → T ( ϕ T → R ( p ) ) ) T_{ab}'=T_{ab}(\phi_{R\to T}(\phi_{T\to R}(p))) Tab′=Tab(ϕR→T(ϕT→R(p)))。我们假设,因为二者都通过 ϕ T → R \phi_{T\to R} ϕT→R进行扭曲,在 T a b ′ T_{ab}' Tab′中正确的颜色的位置也会位列于 R a b ′ R_{ab}' Rab′相同的位置。
训练色度分支时,将 T L T_L TL和 T a b ′ T_{ab}' Tab′输入到网络,生成结果 P a b T P_{ab}^T PabT:
P a b T = C ( T L , s i m T ↔ R , T a b ′ ; θ ) P_{ab}^T=\pmb{C}(T_L,sim_{T\leftrightarrow R},T_{ab}';\theta) PabT=CCC(TL,simT↔R,Tab′;θ)
P a b T P_{ab}^T PabT基于 T a b ′ T_{ab}' Tab′来上色,并且应该在选择正确的样本和颜色的时候恢复ground truth T a b T_{ab} Tab。计算色度误差采用smooth L1误差:
L c h r o m ( P a b T ) = ∑ p L 1 ( P a b T ( p ) , T a b ( p ) ) \mathcal{L}_{chrom}(P_{ab}^T)=\sum_pL_1(P_{ab}^T(p),T_{ab}(p)) Lchrom(PabT)=∑pL1(PabT(p),Tab(p))
使用smooth L1误差是为了避免在这些模糊的着色问题中获得一个均值的解。
仅仅使用色度损失可以在 R a b ′ R_{ab}' Rab′有值得信赖的颜色时有用处,但是对于对照颜色不同的部分则没什么办法。为了使网络能够在即使没有一个合适的对照下也能获得视觉上可行的图片,我们添加了一个感知分支。在这个分支下,我们使用对照图片 R a b ′ R_{ab}' Rab′和目标 T L T_L TL来作为训练时的输入。我们继续预测色度信息 P a b P_{ab} Pab: P a b = C ( T L , s i m T ↔ R , R a b ′ ; θ ) P_{ab}=\pmb{C}(T_L,sim_{T\leftrightarrow R,R_{ab}';\theta}) Pab=CCC(TL,simT↔R,Rab′;θ)。我们计算感观的误差 L p e r c ( P a b ) = ∑ p ∣ ∣ F P ( p ) − F T ( p ) ∣ ∣ 2 \mathcal{L}_{perc}(P_{ab})=\sum_p||F_P(p)-F_T(p)||^2 Lperc(Pab)=∑p∣∣FP(p)−FT(p)∣∣2: F P ( p ) F_P(p) FP(p)是 P L a b P_{Lab} PLab通过VGG relu5_1层获得的特征图, F T F_T FT是 T L a b T_{Lab} TLab通过VGG relu5_1层获得的特征图。感观误差消除不正常上色带来的语义分歧,可增强使用两种不同合适的颜色的鲁棒性。
我们通过以下方式优化参数: θ ∗ = a r g m i n θ L c h r o m ( P a b T ) + α L p e r c ( P a b ) ) \theta^* = argmin_{\theta} \mathcal{L}_{chrom}(P_{ab}^T)+\alpha\mathcal{L}_{perc}(P_{ab})) θ∗=argminθLchrom(PabT)+αLperc(Pab))
α \alpha α设为0.005。
网络架构:
使用具有跳跃连接的U-Net:前四个卷积块空间大小减半,卷积核数翻倍用来提取特征;在第5、6个卷积块使用dilated卷积层用来增强语义信息,最后四个卷积块空间大小翻倍,卷积核数减半。在1到10、 2到9、3到8这三块之间加入skip connection。最后通过一个1x1的卷积核去预测输出结果 P a b P_{ab} Pab。最后一层使用tanh层,将 P a b P_{ab} Pab限制到一个有意义的范围。
数据集
本文依据ImageNet数据集生成数据及,通过抽样来自7个热门类别的大约700000个图像对:动物(15%),植物(15%),人(20%),风景(25%),食物(5%),交通(15%)以及文物(5%),涉及共计1000个类别中的700个类。
为了让网络对任何参考图片都具有稳健性,本文通过对具有不同可能相似程度的图像对进行采样。更具体地,其中45%的图像对属于前五相似性(具体看第4章),另外45%是在同一类中随机抽样的。在训练阶段,我们随机切换每队中的两张图片以增强数据。换句话说,目标图片和参考图片在训练期间可互换。所有图片都以256像素为最短边缘进行缩放。
训练的详细操作:
batch=256,使用Adam优化方法。每次迭代时,有50%的数据(128张图片)进入色度分支(Chrominance branch),使用 T a b ′ T_{ab}' Tab′作为参考图片;有50%的数据(128张图片)进入感知力分支(perceptual branch)。更新感知力分支时,只有感知力损失用于梯度反向传播;初始的学习率设置为 1 0 − 4 10^{-4} 10−4,每隔3个周期衰减0.1。默认情况下,我们用10个周期训练整个网络。大概在8路泰坦X的GPU上需要训练2天。
不想读了,这个文章后面还有几块的……我都说了只看到网络结构嘛(认真)