网络爬虫详细设计方案
目录
网络爬虫设计方案
1、网络爬虫简介
2、Java爬虫的开发和使用流程
2.1 下载
2.2 分析
3、单点登陆与Jsoup解析
3.1 单点登陆简介
3.1.1 登陆
3.1.2 注销
3.2 Jsoup网页解析
4、网络爬虫详细设计
4.1 业务流程图
4.2 业务流程
4.2.1 模拟登陆服务
4.2.2 数据服务
4.2.3 解析服务
4.3 tomcat监控
5、视图层详细设计
5.1 开发工具与框架
5.2 开发流程
6、总结
网络爬虫设计方案
1、网络爬虫简介
网页爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本;其使用场景极其广泛,各大搜索引擎(如百度,谷歌,Bing)中都有他们的身影。网络爬虫按照系统结构和实现技术,大致分为以下几种类型:通用网络爬虫,聚焦网络爬虫,增量式网络爬虫,深层网络爬虫。
2、Java爬虫的开发和使用流程
2.1 下载
(1)选择并使用网络工具包(例如HttpClient)下载指定url的网页源代码
(2)使用get/post的方式提交请求
(3)设置请求的headers参数
(4)置请求的cookies参数
(5)设置请求的query/formData参数
(6)使用代理IP
(7)分析目的请求的各种必要参数的来源
(8)对于分析和解决成本过大的请求,可以使用模拟浏览器进行下载(推荐无界面浏览器phantomjs+selenium)
2.2 分析
(1)对于Html形式的文本,使用Jsoup等工具包解析;
(2)对于json格式的文本,使用Gson等工具包解析;
(3)对于没有固定格式,无法用特定工具解析的文本,使用正则表达式工具获取目标数据。
3、单点登陆与Jsoup解析
河南的应用场景与吉林的应用场景基本相似,都是访问第三方门户系统,根据相应需求抓取相关网页数据。依据吉林的开发情况,河南开发也需要有单点登陆与使用Jsoup进行页面解析重要的两个部分。目前单点登陆有两套方案,吉林前期使用的单点登陆方案使用过程需要进行相关参数的修改,后期使用的单点登陆方案操作起来比较方便,但业务逻辑相对复杂一点,这个在河南部署的时候综合考虑。
3.1 单点登陆简介
单点登录全称Single Sign On(以下简称SSO),是指在多系统应用群中登录一个系统,便可在其他所有系统中得到授权而无需再次登录,包括单点登录与单点注销两部分。
3.1.1 登陆
相比于单系统登录,sso需要一个独立的认证中心,只有认证中心能接受用户的用户名密码等安全信息,其他系统不提供登录入口,只接受认证中心的间接授权。间接授权通过令牌实现,sso认证中心验证用户的用户名密码没问题,创建授权令牌,在接下来的跳转过程中,授权令牌作为参数发送给各个子系统,子系统拿到令牌,即得到了授权,可以借此创建局部会话,局部会话登录方式与单系统的登录方式相同。如图示:

- 用户访问系统1的受保护资源,系统1发现用户未登录,跳转至sso认证中心,并将自己的地址作为参数
- sso认证中心发现用户未登录,将用户引导至登录页面
- 用户输入用户名密码提交登录申请
- sso认证中心校验用户信息,创建用户与sso认证中心之间的会话,称为全局会话,同时创建授权令牌
- sso认证中心带着令牌跳转会最初的请求地址(系统1)
- 系统1拿到令牌,去sso认证中心校验令牌是否有效
- sso认证中心校验令牌,返回有效,注册系统1
- 系统1使用该令牌创建与用户的会话,称为局部会话,返回受保护资源
- 用户访问系统2的受保护资源
- 系统2发现用户未登录,跳转至sso认证中心,并将自己的地址作为参数
- sso认证中心发现用户已登录,跳转回系统2的地址,并附上令牌
- 系统2拿到令牌,去sso认证中心校验令牌是否有效
- sso认证中心校验令牌,返回有效,注册系统2
- 系统2使用该令牌创建与用户的局部会话,返回受保护资源
用户登录成功后,会与sso认证中心及各个子系统建立会话,用户与sso认证中心建立的会话称为全局会话,用户与各个子系统建立的会话称为局部会话,局部会话建立之后,用户访问子系统受保护资源将不再通过sso认证中心,全局会话与局部会话有如下约束关系:
- 局部会话存在,全局会话一定存在
- 全局会话存在,局部会话不一定存在
- 全局会话销毁,局部会话必须销毁
3.1.2 注销
单点登录自然也要单点注销,在一个子系统中注销,所有子系统的会话都将被销毁,用下面的图来说明:

sso认证中心一直监听全局会话的状态,一旦全局会话销毁,监听器将通知所有注册系统执行注销操作。
简要说明上图:
- 用户向系统1发起注销请求
- 系统1根据用户与系统1建立的会话id拿到令牌,向sso认证中心发起注销请求
- sso认证中心校验令牌有效,销毁全局会话,同时取出所有用此令牌注册的系统地址
- sso认证中心向所有注册系统发起注销请求
- 各注册系统接收sso认证中心的注销请求,销毁局部会话
- sso认证中心引导用户至登录页面
注:单点登陆目前有两套系统,其源码都将以附件的形式呈送。
3.2 Jsoup网页解析
Jsoup使用起来比较简单,有过Jquery使用经历的会很快上手。使用Jsoup进行页面解析,其实就是使用选择器针对大数据量的网页进行筛选,获得所需要的数据。
常用选择器语法如下:
Elements links = doc.select("a[href]"); //带有href属性的a元素
Elements pngs = doc.select("img[src$=.png]");//扩展名为.png的图片
Element masthead = doc.select("div.masthead").first();//class等于masthead的div标签
Elements resultLinks = doc.select("h3.r > a"); //在h3元素之后的a元素
Selector选择器概述:
tagname: 通过标签查找元素,比如:a
ns|tag: 通过标签在命名空间查找元素,比如:可以用 fb|name 语法来查找
#id: 通过ID查找元素,比如:#logo
.class: 通过class名称查找元素,比如:.masthead
[attribute]: 利用属性查找元素,比如:[href]
[^attr]: 利用属性名前缀来查找元素,比如:可以用[^data-] 来查找带有HTML5 Dataset属性的元素
[attr=value]: 利用属性值来查找元素,比如:[width=500]
[attr^=value], [attr$=value], [attr*=value]: 利用匹配属性值开头、结尾或包含属性值来查找元素,比如:[href*=/path/]
[attr~=regex]: 利用属性值匹配正则表达式来查找元素,比如: img[src~=(?i)\.(png|jpe?g)]
*: 这个符号将匹配所有元素
4、网络爬虫详细设计
4.1 业务流程图

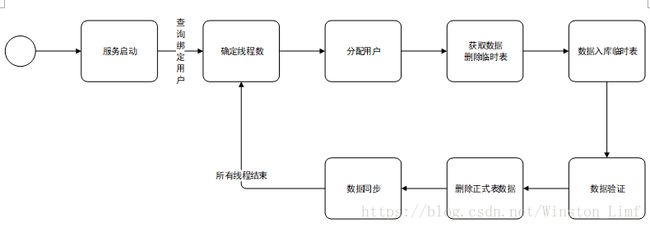

4.2 业务流程
爬虫服务可拆分为3个服务:
4.2.1 模拟登陆服务
提供对外接口,用户传入用户名、密码、URL、待访问系统、返回类型,系统根据返回类型返回HTML代码或者Cookie信息
4.2.2 数据服务
新闻、公告信息爬取步骤:
- tomcat启动
- 爬取新闻信息和公告信息
- 获取绑定用户数,根据绑定用户数计算使用的线程数
- 为线程分配用户
- 开始爬取,并删除临时表信息
- 数据入临时表
- 数据验证,用于处理爬取失败的用户,正式表的数据不删除
- 删除正式表数据
- 临时表数据同步至正式
- 判断所有线程结束后,返回3
- 需要记录日志,直接写入文件,记录内容:启动时间、线程数、用户数、成功用户数、成功数据量、失败用户数
4.2.3 解析服务
步骤:
- 用户session信息判断,用户session存在的直接使用session访问,不存在的登录
- 登录至云门户
- 登录至业务系统
- 爬取页面信息
- 解析页面
- 形成json数据
- 实时获得工单列表条目数和工单详细信息大致流程与解析服务一致,其实就是多爬取了一次工单列表页面,不进行入库处理,实时返回工单列表数量。上述解析服务流程基本可以满足常见的页面数据爬取工作,对于涉及交互方面的则需根据具体情况来分析。
4.3 tomcat监控
需要使用shell脚本对其进行管理,主要有以下两点:
- 每天定时重启,初步定为凌晨0点
- 10分钟扫描一次tomcat进程,发现挂掉了立即重启
5、视图层详细设计
5.1 开发工具与框架
Hbuilder开发平台, mui框架,jQuery框架
5.2 开发流程
- 页面设计
- 静态页面 -- 根据画好的页面效果图,写出静态页面,以及部分按钮的实现。注意 css的编写 及 后期 页面 之间参数的传递。
- 数据解析 -- 从后台人员处获取接口,然后js中通过jQuery.ajax({})调用接口,通过固定参数测试是否能获取到数据,注意遮罩及回调函数。
- 数据渲染 -- 根据获取的数据类型,往页面填充数据。通过js便利填充 或者用 mui内部插件引入angular.min.js,通过 $scope赋值。
6、总结
使用爬虫在获取数据过程中确实提供了方便,在第三方不提供接口的情况下,使用网络爬虫是一种很好的数据获取机制。网络网虫的好处大致有以下几点:
- 准确定位,数据获取方便
- 数据筛选,精炼海量信息
- 数据库角色扮演者
但是网络爬虫也存在不少缺点,我们在开发过程中发现使用网络爬虫其实还是存在很多短板的,不足之处如下:
- 不规则网页处理,页面结构混乱导致爬虫代码冗余
- 反爬策略,网站反爬策略导致爬取数据失败
- 动态加载网站,抓取动态加载的数据,需要分析大量的源文件
- 大规模,海量数据计算能力与内存容量无法形成正比
吉林项目最初使用爬虫的方式获取数据,在测试过程中发现数据加载较慢,对于实时抓取的数据显示的尤为突出。目前该项目已调整开发,计划使用接口的形式从第三方来进行数据的获得。