Python学习笔记 房价分析(回归问题)
与前两个问题不同,这个问题是预测连续的数据,属于回归问题。每个数据包含13个特征值,包括犯罪率、当地房产税率等等。
#导入数据集
from keras.datasets import boston_housing
(train_data,train_targets),(test_data,test_targets)=boston_housing.load_data()
#数据标准化:减去特征平均值,再除以标准差
mean = train_data.mean(axis=0)
train_data -= mean
std = train_data.std(axis=0)
train_data /= std
test_data -= mean
test_data /= std
#构建模型
from keras import models
from keras import layers
def build_model():
model = models.Sequential()
model.add(layers.Dense(64, activation='relu',
input_shape=(train_data.shape[1],)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
return model
这里需要解释一下,首先因为样本数量很少,我们将使用一个非常小的网络,过拟合会越严重,而较小的网络可以降低过拟合。
其次,网络的最后一层只有一个单元,是一个线性层。这是标量回归(预测单一连续值)的典型设置。添加激活函数将会限制输出范围。(例如,如果向最后一层添加 sigmoid 激活函数,网络只能学会预测 0~1 范围内的值。这里最后一层是纯线性的,所以网络可以学会预测任意范围内的值。)
mse 损失函数:即均方误差(MSE,mean squared error),预测值与目标值之差的平方。这是回归问题常用的损失函数。
平均绝对误差(MAE,mean absolute error):它是预测值与目标值之差的绝对值。比如,如果这个问题的 MAE 等于 0.5,就表示你预测的房价与实际价格平均相差 500 美元。
在本例中,验证集很小,如何划分验证集会给结果造成很大波动。这种情况最好使用k折交叉验证。将数据划为K(一般为4到5)个分区,每个模型在K-1个分区上训练,并在剩下的那个分区上评估,最后取平均值。
#K折验证
import numpy as np
k = 4
num_val_samples = len(train_data) // k
num_epochs = 100
all_scores = []
#准备验证K个分区
for i in range(k):
#这部分是第k个分区
print('processing fold #', i)
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
#这部分是其余的分区
partial_train_data = np.concatenate(
[train_data[:i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[(i + 1) * num_val_samples:]],
axis=0)
#构建模型
model = build_model()
#训练模型
model.fit(partial_train_data, partial_train_targets,
epochs=num_epochs, batch_size=1, verbose=0)
#在验证数据上评估模型
val_mse, val_mae = model.evaluate(val_data, val_targets, verbose=0)
all_scores.append(val_mae)
#得到四次的验证分数
print(all_scores)
#得到平均值
print(np.mean(all_scores))

#训练500轮,保存每折的验证结果
num_epochs = 500
all_mae_histories = []
for i in range(k):
print('processing fold #', i)
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
partial_train_data = np.concatenate(
[train_data[:i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[(i + 1) * num_val_samples:]],
axis=0)
model = build_model()
history = model.fit(partial_train_data, partial_train_targets,
validation_data=(val_data, val_targets),
epochs=num_epochs, batch_size=1, verbose=0)
mae_history = history.history['val_mean_absolute_error']
all_mae_histories.append(mae_history)
#计算所有轮次中的 K 折验证分数平均值
average_mae_history = [
np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)]
#画图看一下验证分数
import matplotlib.pyplot as plt
plt.plot(range(1, len(average_mae_history) + 1), average_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()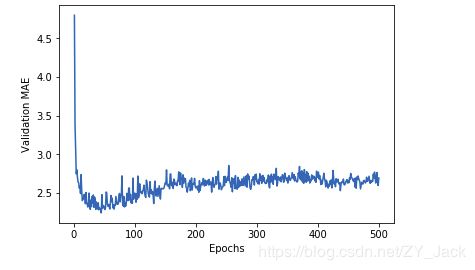
调整:将前十个数据删除以缩短纵轴长度,同时将每个数据点替换为前面数据点的指数移动平均值,以得到光滑的曲线。
# 绘制验证分数(删除前 10 个数据点)
def smooth_curve(points, factor=0.9):
smoothed_points = []
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous * factor + point * (1 - factor))
else:
smoothed_points.append(point)
return smoothed_points
smooth_mae_history = smooth_curve(average_mae_history[10:])
plt.plot(range(1, len(smooth_mae_history) + 1), smooth_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()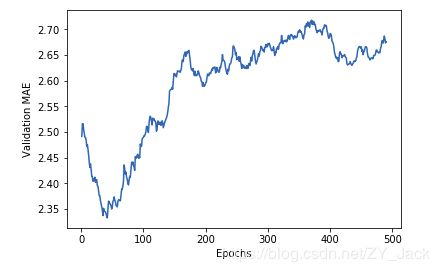
书里面MAE在80轮处停止继续下降,而在我自己的实验中,在50轮处就已经停止下降,接下来便开始过拟合了。所以重新改变模型。
#50轮次的新的模型
model = build_model()
model.fit(train_data, train_targets,
epochs=50, batch_size=16, verbose=0)
test_mse_score, test_mae_score = model.evaluate(test_data, test_targets)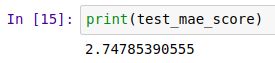
也就是说预测的房价和实际相差平均2700美元
代码:https://github.com/GiveMeLuna/deeplearning.git