AI以假乱真怎么办?TequilaGAN教你轻松辨真伪


在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
这是 PaperDaily 的第 94 篇文章本期推荐的论文笔记来自 PaperWeekly 社区用户 @TwistedW。本文来自 UC Berkeley,GAN 生成的样本在视觉方面已经达到与真实样本很相近的程度了,有的生成样本甚至可以在视觉上欺骗人类的眼睛。区分生成样本和真实样本当然不能简单的从视觉上去分析,TequilaGAN 从图像的像素值和图像规范上区分真假样本,证明了真假样本具有在视觉上几乎不会被注意到的属性差异从而可以将它们区分开。
如果你对本文工作感兴趣,点击底部阅读原文即可查看原论文。
关于作者:武广,合肥工业大学硕士生,研究方向为图像生成。
■ 论文 | TequilaGAN: How to easily identify GAN samples
■ 链接 | https://www.paperweekly.site/papers/2116
■ 作者 | Rafael Valle / Wilson Cai / Anish Doshi
GAN 和 GAN 的变种已经将图像生成质量达到了以假乱真的效果,虽然生成的一部分图像可以用肉眼去分辨,但是仍然有一部分由 GAN 生成的图像在视觉上很难和真实图像区分开。区分真假图像对于分析 GAN 的生成上具有一定的意义,同时也说明了 GAN 在生成上与真实图像的不同所在。TequilaGAN: How to easily identify GAN samples 一文将从视觉以外的方面去区分生成样本和真实赝本之间的差距。
论文引入
使用 GAN 框架生成的假样本在一定程度上骗过了人类和机器,使他们相信生成样本与实际样本无法区分。虽然这可能适用于肉眼和被发生器愚弄的判别器,但生成样本不可能在数值上与实际样本无法区分。TequilaGAN 一文正是通过真实样本和生成样本在数值上的分析可以判断出真假。
GAN 的生成数据的评判标准一直没有很好的统一,大部分的评估是在定性的方面作分析,定量上 Inception Score [1] 一直被广泛使用,但是 A Note on the Inception Score [2] 一文也指出了 Inception Score 未能为 GAN 模型的评估提供系统指导。
在已验证的人工智能的背景下,很难系统地验证模型的输出是否满足其训练的数据的规范,特别是当验证取决于感知有意义的特征的存在时。例如,考虑一个生成人类图像的模型,尽管可以比较真实样本和假样本的颜色直方图,但还没有强大的算法来验证图像是否遵循从解剖结构得出的规范。
TequilaGAN 涉及假样本的系统验证,重点是比较假样本和真实样本的数值特性。除了比较统计汇总之外,还研究了 Generator 如何逼近实际分布中的统计模式,并验证生成的样本是否违反了从实际分布中得出的规范。总结一下 TequilaGAN 的主要贡献:
证明了假样本在视觉上和真实样本具有几乎不会被注意到的属性
这些属性可用于识别数据来源(真实或生成)
证明了假样本违反了从真实数据中学习的正式规范
研究方法
实验主要集中在三点:第一点表明,假样本具有视觉检查难以察觉的特性,此特性与可微分的要求密切相关;第二个表明,从可用于识别数据的真实和假样本中提取的特征计算的统计矩之间存在数值差异;第三个表明假样本违反了从真实数据中学到的正式规范。
数据集
实验使用 MNIST,CIFAR10 以及从网上下载的 389 个 Bach Chorales 的 MIDI 数据集和 NIST 2004 电话会话语音数据集的子样本。
特征
特征光谱质心[3] 是音频领域常用的特征,它代表光谱的重心。MNIST 和 Mel-Spectrograms 的特征光谱质心如下图所示示例。对于图像中的每一列,通过对列总和进行归一化,将像素值转换为行概率,然后获取预期的行值,从而获得光谱质心。
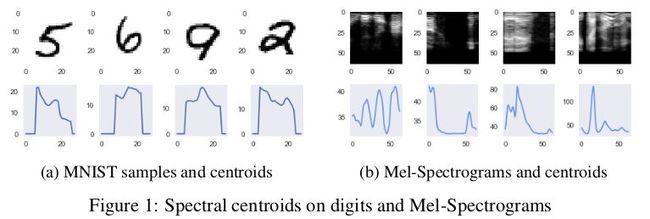
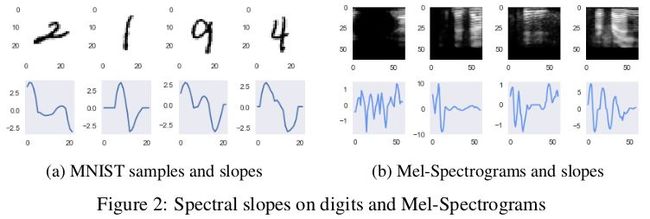
试验中同时表示了谱斜率图:
GAN框架选取
GAN 框架使用最小二乘 GAN(LSGAN)和改进的 Wasserstein GAN(IWGAN / WGAN-GP)网络搭建使用 DCGAN 架构。还比较了使用快速梯度符号法(FGSM)生成的对抗性 MNIST 样本。在生成器的输出和其他变换(例如缩放的 tanh 和身份)上评估常用的非线性,sigmoid 和 tanh。
MNIST实验
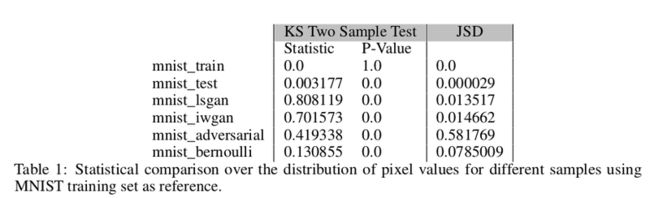
这部分着重于显示由 GAN 伪造的 MNIST 样品的数值特性以及肉眼未知的特征。首先将通过 MNIST 训练集计算的特征分布与其他数据集进行比较,包括 MNIST 测试集,使用 GAN 生成的样本和使用 FGSM 计算的对抗样本。将训练数据缩放到 [0,1],并且从伯努利分布采样随机基线,概率等于 MNIST 训练数据中像素强度的平均值 0.13。
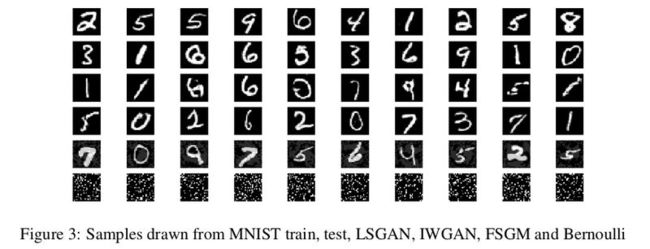
从上图生成的样本表明,IWGAN 似乎比 LSGAN 产生更好的样本。在 Kolgomorov-Smirnov(KS)双样本检验和 Jensen-Shannon Divergence(JSD)上,LSGAN 和 IWGAN 生成的样本如表一所示与标准数据集还是有一定的不同。
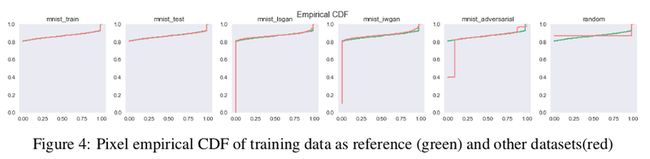
下图中的经验 CDF 可以理解这些数值现象,使用 GAN 框架生成的样本的像素值分布主要是双模态的,并且渐近地接近实数据中的分布模式值 0 和 1。
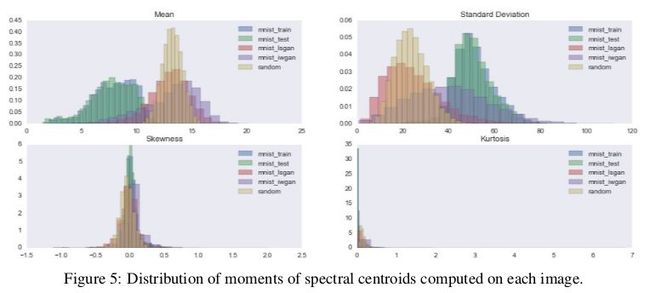
此外,光谱质心的统计矩的分布图表明假图像比真实图像更嘈杂。
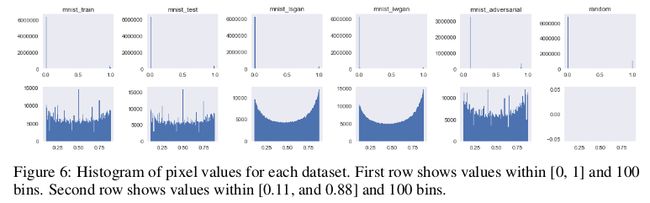
最后,下图显示 GAN 生成的样本平滑地接近分布模式,这种平滑近似与训练和测试集有很大不同。虽然在感知上没有意义,但这些属性可用于识别数据源。
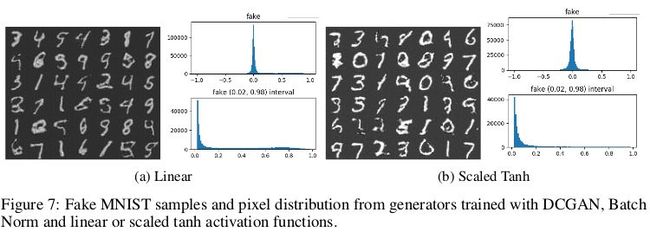
对分布模式的平滑逼近的解释上,第一个假设是网络搭建采用随机梯度下降和渐近收敛激活函数(例如 sigmoid 或 tanh),为了验证这一假设,保持判别器固定,在发生器的输出端采用不同的激活函数,包括线性和缩放的 tanh。如下图所示,使用线性或缩放 tanh 激活训练的模型能够部分地生成类似于 MNIST 训练数据和像素强度分布的图像,仍然具有平滑的曲线。
另一个假设是平滑行为是由于训练数据本身的像素强度的平滑性,为了验证这一点,首先通过在 [0,1] 之间对其进行缩放,然后将其设置为 0.5 来对实际数据进行二值化。通过这种改变,实数据的像素强度的分布变为完全双模态,模式为 0 和 1,从下图结果显示假设是合理的。
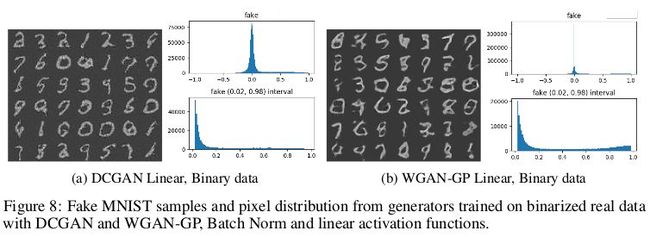
根据上述实验可知,随机梯度下降和方向传播的应用使得生成的图像分布上是平滑的,这是区分真假样本的一个重要依据。
CIFAR-10实验
CIFAR-10 的实验主要是在 MNIST数据集的基础上将像素扩展到 3 通道的彩色图像上,实验结果如下:
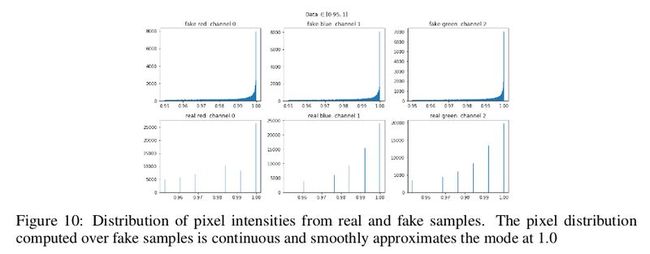
可以看出生成样本仍然是平滑分布。
Bach Chorales和Speech实验
这两种数据集都是在语音数据下比较的,Bach Chorales(巴赫合唱)音乐是复调的音乐作品,通常为 4 或 5 种声音编写,遵循一系列规范或规则。例如,全局规范可以声明只有一组持续时间有效;本地规范可以声明只有状态(音符)之间的某些转换才有效,具体取决于当前的和声。
实验中,将 Bach Chorales 数据集转换为钢琴卷,钢琴卷是一种表示,其中行表示音符编号,列表示时间步长,单元格值表示音符强度。实验的目的是为了证明生成的样本是否违反了 Bach 合唱的规范。下图为真实和生成的样本数据,表 2 为打破规则的次数:


虽然图 11 显示的生成样本看起来与实际数据类似,但 IWGAN 样本有超过 5000 次违规,比测试集多 10 倍!违反规范是一个有力的证据,表明假样本不是来自与真实数据相同的分布。
在语音(speech)域中,实验研究了 Mel-Spectrogram 特性。将 NIST 2004 数据集划分为训练和测试集,将语音转换为 Mel-Spectrogram 图,得到的生成样本如下:

经验 CDF 的对比结果如下:

总结
TequilaGAN 研究了用对抗方法生成的样本的数值特性,特别是生成对抗网络。实验发现假样本在视觉具有与真实样本几乎无法注意到的特性,即由于随机梯度下降和可微分性的要求,假样本平滑地接近分布的主导模式。
实验还对真实数据与其他数据之间差异的统计度量,结果表明,即使在简单的情况下,例如像素强度的分布,训练数据和伪数据之间的差异对于测试数据而言是大的,并且假数据严重违反了实际数据的规范。
参考文献
[1]. Tim Salimans, Ian J. Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. CoRR, abs/1606.03498, 2016.
[2]. Shane Barratt and Rishi Sharma. A note on the inception score. arXiv preprint arXiv: 1801.01973, 2018.
[3]. Geoffroy Peeters. A large set of audio features for sound description (similarity and classifica- tion) in the cuidado project. Technical report, IRCAM, 2004.
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!
![]()
点击标题查看更多论文解读:
ACL2018高分论文:混合高斯隐向量文法
基于词向量的简单模型 | ACL 2018论文解读
COLING 2018最佳论文:序列标注经典模型复现
一文解析OpenAI最新流生成模型「Glow」
CVPR 2018 最佳论文解读:探秘任务迁移学习
哈佛NLP组论文解读:基于隐变量的注意力模型
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
▽ 点击 | 阅读原文 | 下载论文