Hadoop+ZooKeeper+HBase 集群搭建
Hadoop+ZooKeeper+HBase 集群搭建
一.前期环境准备
1.版本选择
ZooKeeper3.4.12
下载地址:
http://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz
Hadoop2.8.3
下载地址:http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.8.3/hadoop-2.8.3.tar.gz
HBase2.0
下载地址:http://mirrors.hust.edu.cn/apache/hbase/2.0.0/hbase-2.0.0-bin.tar.gz
2. 机器配置 3台centos7虚拟机
2.1 配置Host /etc/hosts
10.128.1.92 master.cnmy
10.128.1.93 slave1.cnmy
10.128.1.95 slave2.cnmy
2.2配置JDK和ntp(每个主机都需要)
[root@master bin]# java -version
java version "1.8.0_161"
Java(TM) SE Runtime Environment (build 1.8.0_161-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode)
JDK环境变量配置 vim /etc/profire
export JAVA_HOME=/home/jdk1.8.0_161
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME CLASSPATH PATH
即使生效 source /etc/profile
首先安装ntp
yum install ntp
安装完毕之后,启动服务
systemctl start ntpd.service
设置开机自启动
systemctl enable ntpd.service
二、配置各主机ssh免登陆
1、生成密钥(主机全部执行一遍)
这里略过不详细介绍,如果不明白可自行百度
三、搭建Zookeeper
1.在master.cnmy主机的home目录下
wget http://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz
tar zxvf zookeeper-3.4.12.tar.gz
2.部署
mkdir /home/zookeeper-3.4.12/data
mkdir -p /home/zookeeper-3.4.12/datalog
cd /home/zookeeper-3.4.12/conf
cp zoo_sample.cfg zoo.cfg
zoo.cfg内容如下:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/zookeeper-3.4.12/data
dataLogDir=/home/zookeeper-3.4.12/log
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=master.cnmy:2888:3888
server.2=slave1.cnmy:2888:3888
server.3=slave2.cnmy:2888:3888
在zookeeper的data目录下创建myid文件,master机内容1,其他主机2和3;(复制后记得修改)复制到slave主机
scp -r zookeeper-3.4.12 slave1.cnmy:/home/
scp -r zookeeper-3.4.12 slave2.cnmy:/home/
各主机etc/profile
export ZOOKEEPER_HOME=/home/zookeeper-3.4.12
export PATH=$PATH:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf
即使生效 source /etc/profile
3、启动Zookeeper各主机启动
zkServer.sh start
zkServer.sh start
root@master:/home# zkServer.sh startZooKeeper JMX enabled by defaultUsing
config: /home/zookeeper-3.4.12/bin/../conf/zoo.cfgStarting zookeeper
... STARTED
4、常用命令
# 启动
zkServer.sh start
# 停止
zkServer.sh stop
# 状态
zkServer.sh status
四、搭建Hadoop
1.下载
wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.8.3/hadoop-2.8.3.tar.gz
tar zxvf hadoop-2.8.3.tar.gz
2.配置
2.1在各主机上建立相关目录
mkdir /home/data
mkdir /home/data/journal
mkdir /home/data/tmp
mkdir /home/data/hdfs
mkdir /home/data/hdfs/data
mkdir /home/data/hdfs/name
2.2在/home/hadoop-2.8.3/etc/hadoop目录下配置core-site.xml
fs.defaultFS
hdfs://ns
hadoop.tmp.dir
/home/data/tmp
io.file.buffer.size
4096
ha.zookeeper.quorum
master.cnmy:2181,slave1.cnmy:2181,slave2.cnmy:2181
2.3在/home/hadoop-2.8.3/etc/hadoop目录下配置hdfs-site.xml
dfs.nameservices
ns
dfs.ha.namenodes.ns
nn1,nn2
dfs.namenode.rpc-address.ns.nn1
master.cnmy:9000
dfs.namenode.http-address.ns.nn1
master.cnmy:50070
dfs.namenode.rpc-address.ns.nn2
slave1.cnmy:9000
dfs.namenode.http-address.ns.nn2
slave1.cnmy:50070
dfs.namenode.shared.edits.dir
qjournal://master.cnmy;slave1.cnmy;slave2.cnmy/ns
dfs.journalnode.edits.dir
/home/data/journal
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.ns
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.namenode.name.dir
file:/home/data/hdfs/name
dfs.datanode.data.dir
file:/home/data/hdfs/data
dfs.replication
1
dfs.webhdfs.enabled
true
2.4在/home/hadoop-2.8.3/etc/hadoop目录下配置mapred-site.xml(内存配置问题,是主机只有1G内存。内存大可不用配置。)
mapreduce.framework.name
yarn
mapreduce.application.classpath
/home/hadoop-2.8.3/etc/hadoop,
/home/hadoop-2.8.3/share/hadoop/common/*,
/home/hadoop-2.8.3/share/hadoop/common/lib/*,
/home/hadoop-2.8.3/share/hadoop/hdfs/*,
/home/hadoop-2.8.3/share/hadoop/hdfs/lib/*,
/home/hadoop-2.8.3/share/hadoop/mapreduce/*,
/home/hadoop-2.8.3/share/hadoop/mapreduce/lib/*,
/home/hadoop-2.8.3/share/hadoop/yarn/*,
/home/hadoop-2.8.3/share/hadoop/yarn/lib/*
mapreduce.map.memory.mb
512
mapreduce.map.java.opts
-Xmx512M
mapreduce.reduce.memory.mb
512
mapreduce.reduce.java.opts
-Xmx256M
2.5在/home/hadoop-2.8.3/etc/hadoop目录下配置yarn-site.xml
yarn.resourcemanager.hostname
master.cnmy
yarn.nodemanager.aux-services
mapreduce_shuffle
The address of the RM web application.
yarn.resourcemanager.webapp.address
master.cnmy:18008
2.6在/home/hadoop-2.8.3/etc/hadoop目录下创建配置slaves
master.cnmy
slave1.cnmy
slave2.cnmy
2.7在/home/hadoop-2.8.3/etc/hadoop目录下配置hadoop-env.sh
export JAVA_HOME=/home/jdk1.8.0_161
export HADOOP_OPTS="$HADOOP_OPTS -Duser.timezone=GMT+08"
2.8在/home/hadoop-2.8.3/etc/hadoop目录下配置yarn-env.sh
YARN_OPTS="$YARN_OPTS -Duser.timezone=GMT+08"
配置etc/profile
export HADOOP_HOME=/home/hadoop-2.8.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
即使生效 source /etc/profile
3、配置slave
复制到slave1.cnmy slave2.cnmy
cd /home
scp -r hadoop-2.8.3 slave1.cnmy:/home/
scp -r hadoop-2.8.3 slave2.cnmy:/home/
4、首次启动
# 1、首先启动各个节点的Zookeeper,在各个节点上执行以下命令:(每个主机)
zkServer.sh start
# 2、在某一个namenode节点执行如下命令,创建命名空间(master.cnmy主机)
hdfs zkfc -formatZK
# 3、在每个journalnode节点用如下命令启动journalnode(每个主机)
hadoop-daemon.sh start journalnode
# 4、在主namenode节点格式化namenode和journalnode目录(master.cnmy主机)
hdfs namenode -format
# 5、在主namenode节点启动namenode进程(master.cnmy主机)
hadoop-daemon.sh start namenode
# 7、在所有datanode节点都执行以下命令启动datanode(master.cnmy主机)
hadoop-daemon.sh start datanode
# 8、在 RM1 启动 YARN
start-yarn.sh
# 6、在两个namenode节点都执行以下命令(master.cnmy主机)
hadoop-daemon.sh start zkfc
# 7. 开启历史日志服务 (master.cnmy主机)
mr-jobhistory-daemon.sh start historyserver
5、验证
http://10.128.1.92:18008/cluster/nodes

五、搭建Hbase
1.下载
wget http://mirrors.hust.edu.cn/apache/hbase/2.0.0/hbase-2.0.0-bin.tar.gz
tar -zvxf hbase-2.0.0-bin.tar.gz
2.配置
2.1在/home/hbase-2.0.0/conf目录下配置hbase-env.sh
export JAVA_HOME=/home/jdk1.8.0_161
export HBASE_CLASSPATH=/home/hadoop-2.8.3/etc/hadoop
export HBASE_MANAGES_ZK=false
export TZ="Asia/Shanghai"
关闭hbase自带的zookeeper,这个只能测试,不能生产环境。
classpath一定要改成hadoop的目录,不然不认识集群名称。
网上大部分教程都不是真正的分布式。
2.2在/home/hbase-2.0.0/conf目录下配置hbase-site.xml
hbase.rootdir
hdfs://ns/hbase
hbase.cluster.distributed
true
hbase.master.info.port
16010
hbase.regionserver.info.port
16030
hbase.zookeeper.quorum
master.cnmy:2181,slave1.cnmy:2181,slave2.cnmy:2181
hbase.coprocessor.abortonerror
false
ns是前面配置的namenode集群名称
2.3在/home/hbase-2.0.0/conf目录下创建配置regionservers
slave1.cnmy
slave2.cnmy
2.4 配置 etc/profile
export HBASE_HOME=/home/hbase-2.0.0
export PATH=$HBASE_HOME/bin:$PATH
即使生效 source /etc/profile
3.启动
复制到slave1.cnmy slave2.cnmy
cd /home/
scp -r /home/hbase-2.0.0 slave1.cnmy:/home/
scp -r /home/hbase-2.0.0 slave2.cnmy:/home/
注意在master.cnmy主机中/home/hbase-2.0.0/lib下去掉 slf4j-api-1.7.25.jar, slf4j-log4j12-1.7.25.jar不然会jar冲突导致 hbase启动闪退,
# 启动主 HMaster (master.cnmy主机)
start-hbase.sh
4、常用命令
# 启动(master机器)
start-hbase.sh
# 关闭
stop-hbase.sh
# 启动节点
hbase-daemon.sh start regionserver
5、验证
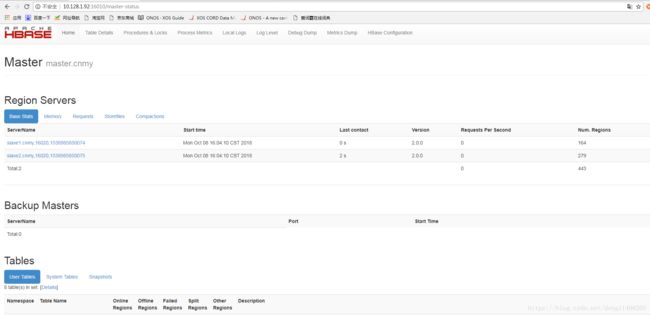
http://10.128.1.92:16010/master-status
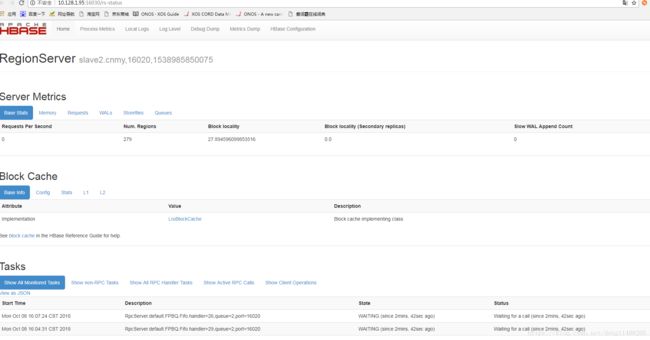
http://10.128.1.93:16030/rs-status

http://10.128.1.95:16030/rs-status