Redis淘汰机制
Redis内存淘汰
指的是用户存储的一些键被可以被Redis主动地从实例中删除,从而产生读miss的情况
那么Redis为什么要有这种功能?这就是我们需要探究的设计初衷。
Redis最常见的两种应用场景为缓存和持久存储
首先要明确的一个问题是内存淘汰策略更适合于那种场景?是持久存储还是缓存?
内存的淘汰机制的初衷是为了更好地使用内存,
用一定的缓存miss来换取内存的使用效率。
作为Redis用户,我如何使用Redis提供的这个特性呢?看看下面配置
maxmemory
525行
我们可以通过配置redis.conf中的maxmemory这个值来开启内存淘汰功能,
至于这个值有什么意义,我们可以通过了解内存淘汰的过程来理解它的意义:
客户端发起了需要申请更多内存的命令(如set)。
Redis检查内存使用情况,如果已使用的内存大于maxmemory
则开始根据用户配置的不同淘汰策略来淘汰内存(key),从而换取一定的内存。如果上面都没问题,则这个命令执行成功。
maxmemory为0的时候表示我们对Redis的内存使用没有限制。
Redis提供了下面几种淘汰策略供用户选择,其中默认的策略为noeviction策略:
· noeviction:当内存使用达到阈值的时候,所有引起申请内存的命令会报错。
· allkeys-lru:在主键空间中,优先移除最近未使用的key。
· volatile-lru:在设置了过期时间的键空间中,优先移除最近未使用的key。
· allkeys-random:在主键空间中,随机移除某个key。
· volatile-random:在设置了过期时间的键空间中,随机移除某个key。
· volatile-ttl:在设置了过期时间的键空间中,具有更早过期时间的key优先移除。
这里补充一下主键空间和设置了过期时间的键空间,举个例子,
假设我们有一批键存储在Redis中,则有那么一个哈希表用于存储这批键及其值,
如果这批键中有一部分设置了过期时间,那么这批键还会被存储到另外一个哈希表中,
这个哈希表中的值对应的是键被设置的过期时间。
设置了过期时间的键空间为主键空间的子集。
我们了解了Redis大概提供了这么几种淘汰策略,那么如何选择呢?淘汰策略的选择可以通过下面的配置指定:
maxmemory-policy noeviction
但是这个值填什么呢?为解决这个问题,我们需要了解我们的应用请求对于Redis中存储的数据集的访问方式以及我们的诉求是什么。
同时Redis也支持Runtime修改淘汰策略,这使得我们不需要重启Redis实例而实时的调整内存淘汰策略。
下面看看几种策略的适用场景:
· allkeys-lru:如果我们的应用对缓存的访问符合幂律分布(也就是存在相对热点数据),或者我们不太清楚我们应用的缓存访问分布状况,我们可以选择allkeys-lru策略。
· allkeys-random:如果我们的应用对于缓存key的访问概率相等,则可以使用这个策略。
· volatile-ttl:这种策略使得我们可以向Redis提示哪些key更适合被eviction。
另外,volatile-lru策略和volatile-random策略
适合我们将一个Redis实例既应用于缓存和又应用于持久化存储的时候
然而我们也可以通过使用两个Redis实例来达到相同的效果,值得一提的是将key设置过期时间实际上会消耗更多的内存,因此我们建议使用allkeys-lru策略从而更有效率的使用内存。
Redis的存储机制有两种AOF Snapshot
无论是那种机制,Redis都是将数据存储在内存中。
Snapshot工作原理: 是将数据先存储在内存,然后当数据累计达到某些设定的伐值的时候,就会触发一次DUMP操作,将变化的数据一次性写入数据文件(RDB文件)。
AOF 工作原理: 是将数据也是先存在内存,但是在存储的时候会使用调用fsync来完成对本次写操作的日志记录,这个日志揭露文件其实是一个基于Redis网络交互协议的文本文件。AOF调用fsync也不是说全部都是无阻塞的,在某些系统上可能出现fsync阻塞进程的情况,对于这种情况可以通过配置修改,但默认情况不要修改。AOF最关键的配置就是关于调用fsync追加日志文件的平率,有两种预设频率,。两个配置各有所长后面分析。由于是采用日志追加的方式来持久话数据,所以引出了第二个日志的概念:rewrite. 后面介绍它的由来。
存储模式性能和安全比较:
1.性能:Snapshot方式的性能是要明显高于AOF方式的,原因有两点:
采用2进制方式存储数据,数据文件比较小,加载快速.
存储的时候是按照配置中的save策略来存储,每次都是聚合很多数据批量存储,写入的效率很好,而AOF则一般都是工作在实时存储或者准实时模式下。相对来说存储的频率高,效率却偏低。
2.数据安全:AOF数据安全性高于Snapshot存储,原因:
Snapshot存储是基于累计批量的思想,
也就是说在允许的情况下,累计的数据越多那么写入效率也就越高,
但数据的累计是靠时间的积累完成的,
那么如果在长时间数据不写入RDB,但Redis又遇到了崩溃,那么没有写入的数据就无法恢复了
但是AOF方式偏偏相反,根据AOF配置的存储频率的策略可以做到最少的数据丢失和较高的数据恢复能力。
说完了性能和安全,这里不得不提的就是在Redis中的Rewrite的功能,
AOF的存储是按照记录日志的方式去工作的,那么成千上万的数据插入必然导致日志文件的扩大,
Redis这个时候会根据配置合理触发Rewrite操作,
所谓Rewrite就是将日志文件中的所有数据都重新写到另外一个新的日志文件中,
但是不同的是,对于老日志文件中对于Key的多次操作,
只保留最终的值的那次操作记录到日志文件中,从而缩小日志文件的大小。
这里有两个配置需要注意:
auto-aof-rewrite-percentage 100 (当前写入日志文件的大小占到初始日志文件大小的某个百分比时触发Rewrite)
auto-aof-rewrite-min-size 64mb (本次Rewrite最小的写入数据良)
两个条件需要同时满足。
2.Redis内存优化理解
Redis内部有很多的数据类型,这些在官方文档上都可以看到,下面是其内部优化的一些细节点:
- String 和 数字,
在Redis中如果存储的是“123”
Redis是能够识别出来这是一个数字并且按照数字来存储,节省存储空间,当然除了这个优化之外
Redis内部会构建一个数字池,默认是10000
那么如果是在这个池子的数字就只需要用一个简单的索引来引用进来就可以,而不需要把重复的数字都分开存储。
这个数值可以调整源代码的宏:REDIS_SHARED_INTEGERS来扩大和缩小池子的大小。
2.复杂类型的存储优化,比如Map,List,Set等,这些集合都有一个特点可大可小
,根据实际场景来定,一般情况下如果这些集合所包含的Entry不多,并且每个Entry所包含的Value不是很长的情况下,Redis内部使用紧凑格式来存储数据,紧凑格式存储数据在查询场景的算法复杂度是O(N),而类似Map或者Set他们的查询算法复杂度都是O(1)那为什么要这么做呢 ?为了能够节省内存空间,在N很小的时候其实和O(1)没什么区别。所以这里不的不介绍紧凑格式的代表ZIPMap,他的数据结构是这样:
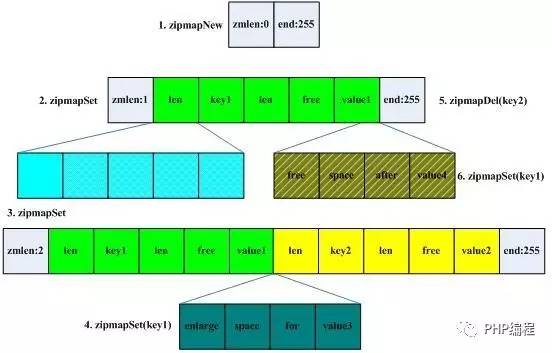
可以看出,这个结构中初始情况只有2个字节,随着操作的增加它会变长,其中最关键的是一个关于Free这个字段的理解,以Map为例,如果新插入一个Key,那么对应ZipMap就会多出来一长串数据:。从图中可以看到插入key1的时候只有绿色的一串,当key2插入的时候就会又出来一个类似的黄色结构串。free的功能是在插入的时候用来冗余空间的,当key所对应的数值发生变化的时候,如果数据变的比之前短了,那么free的长度就变大,这个时候不需要做ZipMap的resize操作,如果数据长度变长了,并且在free能够足以支持新数据的范围之内,那么free就被利用起来,并且也不需要做Resize。这个时候会有空间的浪费或者说碎片。空间换时间,没什么好说的。当然Redis的代码中还有另外一个参数ZIPMAP_VALUE_MAX_FREE,这个参数可以用来设置如果Free的大小超过了这个值,那么ZipMap会发生Resize(收缩),从而节约空间