python爬虫入门笔记:用scrapy爬豆瓣
本文希望达到以下目标:
- 简要介绍Scarpy
- 使用Scarpy抓取豆瓣电影
我们正式讲scrapy框架爬虫,并用豆瓣来试试手,url:http://movie.douban.com/top250
首先先要回答一个问题。问:把网站装进爬虫里,总共分几步?
答案很简单,四步:
- 新建项目 (Project):新建一个新的爬虫项目
- 明确目标(Items):明确你想要抓取的目标
- 制作爬虫(Spider):制作爬虫开始爬取网页
- 存储内容(Pipeline):设计管道存储爬取内容
好的,基本流程既然确定了,那接下来就一步一步的完成就可以了。
1.新建项目(Project)
在空目录下按住Shift键右击,选择“在此处打开命令窗口”,输入一下命令:
scrapy startproject douban
可以看到将会创建一个douban文件夹,目录结构如下:
douban/
scrapy.cfg
douban/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...我们用pycharm打开该项目,具体看一下:

下面来简单介绍一下各个文件的作用:
- scrapy.cfg:项目的配置文件
- douban/:项目的Python模块,将会从这里引用代码
- douban/items.py:项目的items文件
- douban/pipelines.py:项目的pipelines文件
- douban/settings.py:项目的设置文件
- douban/spiders/:存储爬虫的目录
2.明确目标(Item)
在Scrapy中,items是用来加载抓取内容的容器,提供了一些额外的保护减少错误。
一般来说,item可以用scrapy.item.Item类来创建,并且用scrapy.item.Field对象来定义属性。
接下来,我们开始来构建item模型(model)。
首先,我们想要的内容有:
- 电影名称(name)
- 电影描述(movieInfo)
- 电影评分(star)
- 格言(quote)
修改douban目录下的items.py文件,在原本的class后面添加我们自己的class。
因为要抓豆瓣网站的内容,所以我们可以将其命名为DoubanItem:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
from scrapy import Item, Field
class DoubanItem(Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = Field()
movieInfo = Field()
star = Field()
quote = Field()
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
from scrapy import Item, Field
class DoubanItem(Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = Field()
movieInfo = Field()
star = Field()
quote = Field()3.制作爬虫(Spider)
制作爬虫,总体分两步:先爬再取。
也就是说,首先你要获取整个网页的所有内容,然后再取出其中对你有用的部分。
3.1爬
Spider是用户自己编写的类,用来从一个域(或域组)中抓取信息。
他们定义了用于下载的URL列表、跟踪链接的方案、解析网页内容的方式,以此来提取items。
要建立一个Spider,你必须用scrapy.spider.BaseSpider创建一个子类,并确定三个强制的属性:
- name:爬虫的识别名称,必须是唯一的,在不同的爬虫中你必须定义不同的名字。
- start_urls:爬取的URL列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
- parse():解析的方法,调用的时候传入从每一个URL传回的Response对象作为唯一参数,负责解析并匹配抓取的数据(解析为item),跟踪更多的URL。
# -*- coding: utf-8 -*-
from scrapy.spiders import CrawlSpider
class Douban(CrawlSpider):
name = "douban"
start_urls = ['http://movie.douban.com/top250']
def parse(self,response):
print response.body# -*- coding: utf-8 -*-
from scrapy.spiders import CrawlSpider
class Douban(CrawlSpider):
name = "douban"
start_urls = ['http://movie.douban.com/top250']
def parse(self,response):
print response.body然后运行一下看看,在douban目录下按住shift右击,在此处打开命令窗口,输入:
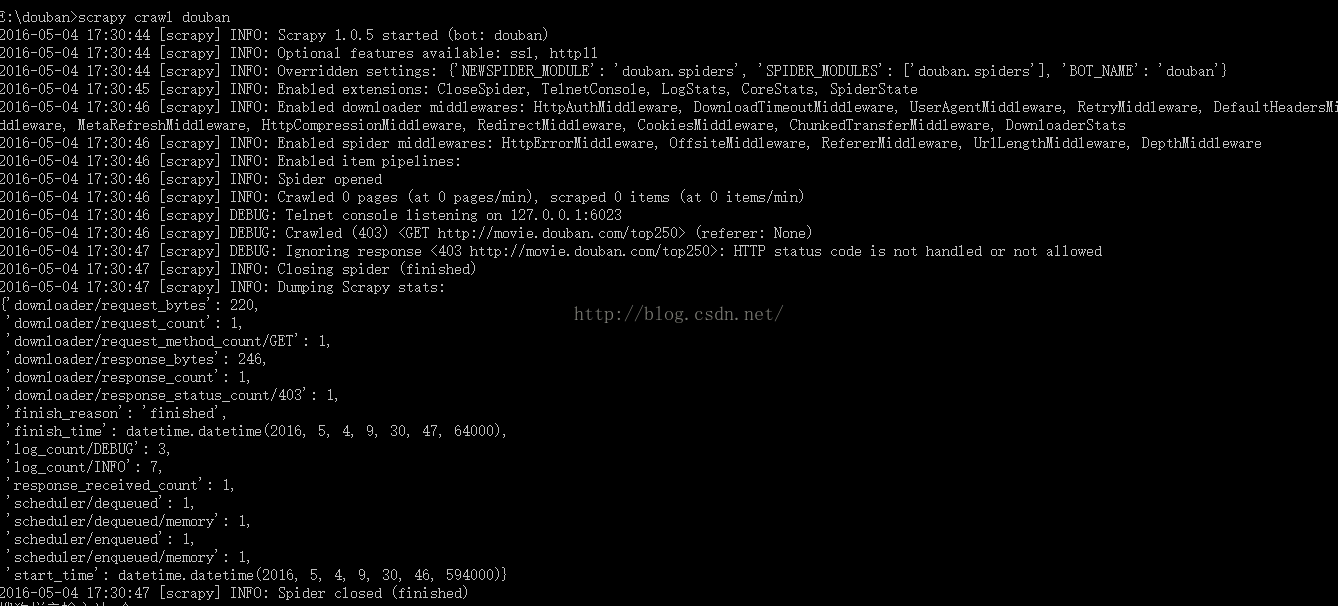
scrapy crawl douban
运行结果如图:
from scrapy import cmdline
cmdline.execute("scrapy crawl douban".split())from scrapy import cmdline
cmdline.execute("scrapy crawl douban".split())在pycharm里运行main.py,可以得到相同的结果。
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5'
运行看一下结果:
3.1取

selector = Selector(response)
Movies = selector.xpath('//div[@class="info"]')
for eachMoive in Movies:
title = eachMoive.xpath('div[@class="hd"]/a/span/text()').extract()
movieInfo = eachMoive.xpath('div[@class="bd"]/p/text()').extract()
star = eachMoive.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract()[0]
quote = eachMoive.xpath('div[@class="bd"]/p[@class="quote"]/span/text()').extract()这里面有两个小问题,大家自己做时可以发现,title包括两个,而quote有的电影没有,所以我们调整一下,完整代码如下:
# -*- coding: utf-8 -*-
from scrapy.spiders import CrawlSpider
from scrapy.selector import Selector
from douban.items import DoubanItem
class Douban(CrawlSpider):
name = "douban"
start_urls = ['http://movie.douban.com/top250']
def parse(self,response):
#print response.body
item = DoubanItem()
selector = Selector(response)
#print selector
Movies = selector.xpath('//div[@class="info"]')
#print Movies
for eachMoive in Movies:
title = eachMoive.xpath('div[@class="hd"]/a/span/text()').extract()
# 把两个名称合起来
fullTitle = ''
for each in title:
fullTitle += each
movieInfo = eachMoive.xpath('div[@class="bd"]/p/text()').extract()
star = eachMoive.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract()[0]
quote = eachMoive.xpath('div[@class="bd"]/p[@class="quote"]/span/text()').extract()
# quote可能为空,因此需要先进行判断
if quote:
quote = quote[0]
else:
quote = ''
print fullTitle
print movieInfo
print star
print quote运行看一下结果:

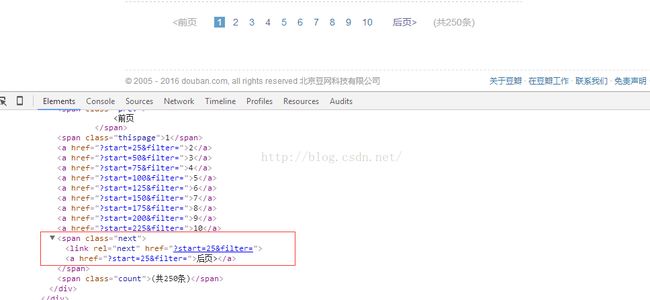
这里我们要引入Request, from scrapy.http import Request
代码如下:
nextLink = selector.xpath('//span[@class="next"]/link/@href').extract()
# 第10页是最后一页,没有下一页的链接
if nextLink:
nextLink = nextLink[0]
print nextLink
url = 'http://movie.douban.com/top250'
yield Request(self.url + nextLink, callback=self.parse)# -*- coding: utf-8 -*-
from scrapy.spiders import CrawlSpider
from scrapy.selector import Selector
from douban.items import DoubanItem
from scrapy.http import Request
class Douban(CrawlSpider):
name = "douban"
start_urls = ['http://movie.douban.com/top250']
url = 'http://movie.douban.com/top250'
def parse(self,response):
#print response.body
item = DoubanItem()
selector = Selector(response)
#print selector
Movies = selector.xpath('//div[@class="info"]')
#print Movies
for eachMoive in Movies:
title = eachMoive.xpath('div[@class="hd"]/a/span/text()').extract()
# 把两个名称合起来
fullTitle = ''
for each in title:
fullTitle += each
movieInfo = eachMoive.xpath('div[@class="bd"]/p/text()').extract()
star = eachMoive.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract()[0]
quote = eachMoive.xpath('div[@class="bd"]/p[@class="quote"]/span/text()').extract()
# quote可能为空,因此需要先进行判断
if quote:
quote = quote[0]
else:
quote = ''
#print fullTitle
#print movieInfo
#print star
#print quote
item['title'] = fullTitle
item['movieInfo'] = ';'.join(movieInfo)
item['star'] = star
item['quote'] = quote
yield item
nextLink = selector.xpath('//span[@class="next"]/link/@href').extract()
# 第10页是最后一页,没有下一页的链接
if nextLink:
nextLink = nextLink[0]
print nextLink
yield Request(self.url + nextLink, callback=self.parse)4.存储内容(Pipeline)
保存信息的最简单的方法是通过Feed exports,主要有四种:JSON,JSON lines,CSV,XML。
我们将结果用最常用的JSON导出,命令如下:
scrapy crawl douban -o items.json -t json
-o 后面是导出文件名,-t 后面是导出类型。
然后来看一下导出的结果,用文本编辑器打开json文件即可
看的不是很舒服,要是能直接看到内容就好了,我们试试保存成CSV,然后用EXCEL打开即可。
scrapy crawl douban -o items.csv -t csv
FEED_URI = u'file:///E:/douban/douban.csv'
FEED_FORMAT = 'CSV'
如果你想用抓取的items做更复杂的事情,你可以写一个 Item Pipeline(条目管道)。
后面我们也会有涉及的,敬请期待!
小伙伴们,自己动手试试吧!
相关学习文章:
1、简书《Python爬虫(六)--Scrapy框架学习》http://www.jianshu.com/p/078ad2067419
2、汪海实验室http://blog.csdn.net/pleasecallmewhy/article/details/19642329
3、极客学院《scrapy初探》http://www.jikexueyuan.com/course/1287.html