深入JVM内核(二)——JVM运行机制
由于之前看的容易忘记,因此特记录下来,以便学习总结与更好理解,该系列博文也是第一次记录,所有有好多不完善之处请见谅与留言指出,如果有幸大家看到该博文,希望报以参考目的看浏览,如有错误之处,谢谢大家指出与留言。
一、目录
JVM启动流程
JVM基本结构
内存模型
编译和解释运行的概念
二、JVM启动流程
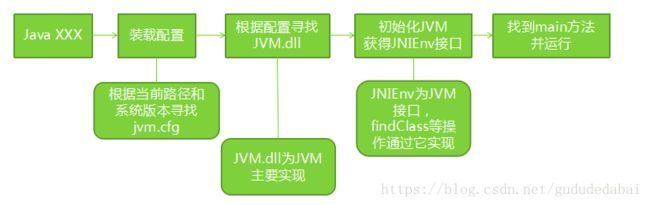
jvm启动的时候一定是由java命令,或者javaw命令;java启动命令会跟一个启动类Java XXX,启动类会有main方法,当通过java启动jvm时首先第一步是装载配置,他会在当前路径和系统版本寻找JVM配置config文件然后找到配置文件之后他会定位所需要的dll(JVM.dll就是java虚拟机主要实现了);在找到匹配当前系统版本的dll之后,就会使用这个dll去初始化jvm虚拟机;获得相关的接口,比如JNIEnv接口,这个接口提供了大量跟JVM交互的操作(比如查找一个类的时候,就用该接口),然后找到main方法就开运行了;
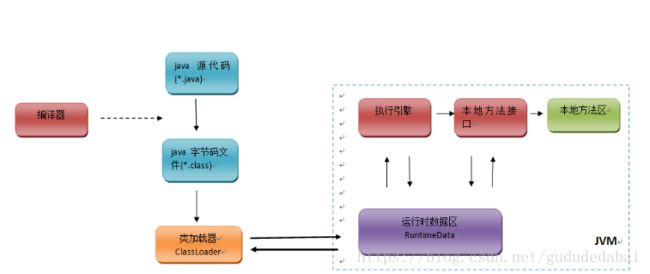
运行原理:
Java代码的编译和执行的整个过程大概是:开发人员编写Java代码(.java文件),然后将之编译成字节码(.class文件),再然后字节码被装入内存,一旦字节码进入虚拟机,它就会被解释器解释执行,或者是被即时代码发生器有选择的转换成机器码执行(jvm的执行引擎执行)。

三、JVM基本结构
首先java虚拟机有个类加载器,就是classload,把java的class文件加载到jvm内存中去。
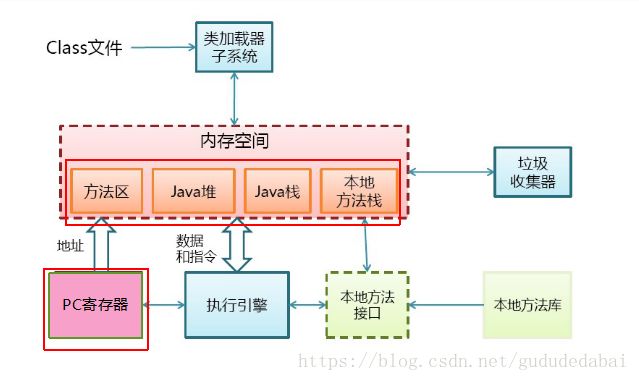
1、PC寄存器(是指每一个线程拥有一个pc寄存器,pc寄存器总是指向下一条指令的地址,那么程序在执行时就知道下一步该执行哪一步。在执行本地方法时,pc寄存器是未定义的)
(1)、每个线程拥有一个PC寄存器
(2)、在线程创建时 创建
(3)、指向下一条指令的地址
(4)、执行本地方法时,PC的值为undefined
2、方法区作用
(1)、保存装载的类信息
类型的常量池
字段,方法信息
方法字节码
但上面所说的并不是一定的。在JDK6与7字符串常量就发生了变化,由此可看,保存什么信息跟jdk版本有关。
JDK6时,String等常量信息置于方法
JDK7时,已经移动到了堆
(2)、通常和永久区(Perm)关联在一起(永久区并不是一直存在的)
注:JDK8中已经把持久代(PermGen Space) 干掉了,取而代之的元空间(Metaspace)。Metaspace占用的是本地内存,不再占用虚拟机内存。
3、Java堆
(1)、和程序开发密切相关
(2)、应用系统对象都保存在Java堆中
(3)、所有线程共享Java堆
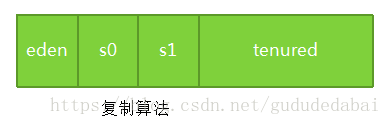
(4)、对分代GC来说,堆也是分代的
(5)、GC的主要工作区间
分代的堆如下:
4、Java栈
(1)、线程私有
(2)、栈由一系列帧组成(因此Java栈也叫做帧栈)先进后出的数据结构
(3)、帧保存一个方法的局部变量、操作数栈、常量池指针
(4)、每一次方法调用创建一个新的帧,并压栈
4.1、Java栈 – 局部变量表 并不是指函数中的变量,他包含参数和局部变量

4.2、Java栈 – 函数调用组成帧栈
当方法被调用时,就会有一个帧往这个栈中去压,每执行一个方法,就往下,直到这个帧栈逆出。如果方法结束,那么这个帧栈就消除。

4.3、Java栈 – 操作数栈
— Java没有寄存器,所有参数传递使用操作数栈

第五步中放入局部变量指的是C变量。
4.4、Java栈 – 栈上分配
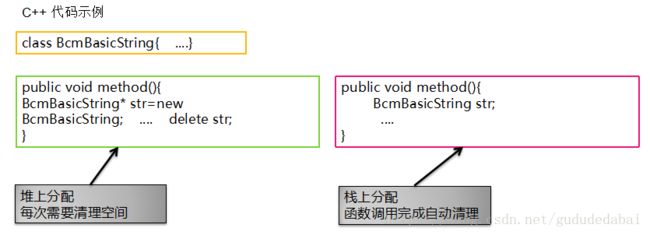
首先分配一个方法,就是通过new创建一个对象,执行完之后就清除,但是new操作对象是放在堆上的,但堆上分配需要手动清除,一旦量变大就会,就会发生某个分配的对象空间没有删,会发生内存泄漏,但这个问题是非常解决的,因为他是全局的,可能发生在任何地方。但c++中还可以使用第二种直接生名一个对象,如右图。这时候得到的对象不是一个指针,而是一个对象引用。后面操作完,就不需要去手动清除。这种情况得到的对象时在栈上的,因为这是局部变量,局部变量是分配在栈上的,所以这就是C++上的栈上分配;所在在栈上分配好处就不可能发生内存泄漏。
对于成员变量和局部变量:成员变量就是方法外部,类的内部定义的变量;局部变量就是方法或语句块内部定义的变量。局部变量必须初始化。
局部变量的数据存在于栈内存中。栈内存中的局部变量随着方法的消失而消失。
成员变量存储在堆中的对象里面,由垃圾回收器负责回收
因此可以把这个思想借鉴到java中。
java代码示例:

如右上第一个如方式执行,发现结果时5,从分配开始到结束就消耗了5毫秒;在按照下面配置执行,发现出现大量gc信息输出,这就说明在第二次执行时中,这些byte数组就是在堆上分配的,而且分配当中由于内存不足,所以他就做gc回收,打印gc信息;第一次他并没有进行gc,也就说明他并没有在堆上进行分配,因为在堆上分配是分配不了这么多内容的。所以可以得到,第一种在栈上分配,这就是java栈上分配;当分配的所需要数据不是很大,虚拟机才会做一些优化,这样导致虚拟机性能就会加快,提高性能,因为在栈上分配,gc压力就会很小。
Java栈 – 栈上分配总结:
栈分配好处:一般只能分配小对象,因为栈的空间并没有堆那么大,每个线程拥有一个栈,线程一多栈的空间就会很多,还有其他好处如下:
(1)、小对象(一般几十个bytes),在没有逃逸的情况下,可以直接分配在栈上
(2)、直接分配在栈上,可以自动回收,减轻GC压力
(3)、大对象或者逃逸对象无法栈上分配
5、栈、堆、方法区交互


main是主线程,那么他就有一个栈,当main调用时就会创建test1,test1是局部变量,作为对象的引用,即Sample类信息存放情况:堆中只是存放对象,栈存放的事对象的引用。类的信息描述以及类方法的实际字节码是存在方法区的,堆中只是存放这个类的实例;因此:关系是,由栈指向堆,而堆的一些信息需要到方法区去存取。

例子:
public class Demo01 {
public static void main(String[] args) {
A a = new A();
System.out.println(a.width);
}
}
class A{
public static int width=100; //静态变量,静态域 field
static{
System.out.println("静态初始化类A");
width = 300 ;
}
public A() {
System.out.println("创建A类的对象");
}
}
说明:
内存中存在栈、堆(放创建好的对象)、方法区(实际也是一种特殊堆)
1、JVM加载Demo01时候,首先在方法区中形成Demo01类对应静态数据(类变量、类方法、代码…),同时在堆里面也会形成java.lang.Class对象(反射对象),代表Demo01类,通过对象可以访问到类二进制结构。然后加载变量A类信息,同时也会在堆里面形成a对象,代表A类。
2、main方法执行时会在栈里面形成main方法栈帧,一个方法对应一个栈帧。如果main方法调用了别的方法,会在栈里面挨个往里压,main方法里面有个局部变量A类型的a,一开始a值为null,通过new调用类A的构造器,栈里面生成A()方法同时堆里面生成A对象,然后把A对象地址付给栈中的a,此时a拥有A对象地址。
3、当调用A.width时,调用方法区数据。
当类被引用的加载,类只会加载一次
- 类的主动引用(一定会发生类的初始化)
- new一个类的对象
- 调用类的静态成员(除了final常量)和静态方法
- 使用java.lang.reflect包的方法对类进行反射调用
- 当虚拟机启动,java Demo01,则一定会初始化Demo01类,说白了就是先启动main方法所在的类
- 当初始化一个类,如果其父类没有被初始化,则先初始化它父类
- 类的被动引用(不会发生类的初始化)
- 当访问一个静态域时,只有真正声名这个域的类才会被初始化
- 通过子类引用父类的静态变量,不会导致子类初始化
- 通过数组定义类的引用,不会触发此类初始化
- 引用常量不会触发此类的初始化(常量在编译阶段就存入调用类的常量池中了)
- 当访问一个静态域时,只有真正声名这个域的类才会被初始化
6、内存模型
可以理解如下:
(1)、每一个线程有一个工作内存和主存独立(主存共享的内存区间,可以理解为堆空间;由性能考虑,每个线程都拥有一个工作内存;工作内存和主存需要同步关系的,很多变量在主存有原始变量,在工作内存中他拥有一些原始变量的一些拷贝,因此工作内存与主存之间可以做一些同步)
(2)、工作内存存放主存中变量的值的拷贝
如下:

- 当数据从主内存复制到工作存储时,必须出现两个动作:第一,由主内存执行的读(read)操作;第二,由工作内存执行的相应的load操作;当数据从工作内存拷贝到主内存时,也出现两个操作:第一个,由工作内存执行的存储(store)操作;第二,由主内存执行的相应的写(write)操作
- 每一个操作都是原子的(是指在read中间不会被终断的),即执行期间不会被中断,在read和load之间存在终断的
- 对于普通变量,一个线程中更新的值,不能马上反应在其他变量中,在这个模型看出,如果两个线程,每个线程都直接读取和存取都在线程的工作内存中,然后线程工作内存在到主存都会存在一定时差的;而这个时差就说明当一个变量改变某值后,不能让另一个线程马上知道的。
如果需要在其他线程中立即可见,需要使用 volatile 关键字,做标识。如下:在JMM中就存在延时和误差。

7、volatile
public class VolatileStopThread extends Thread{
private volatile boolean stop = false;
public void stopMe(){
stop=true;
}
public void run(){
int i=0;
while(!stop){
i++;
}
System.out.println("Stop thread");
}
public static void main(String args[]) throws InterruptedException{
VolatileStopThread t=new VolatileStopThread();
t.start();
Thread.sleep(1000);
t.stopMe();
Thread.sleep(1000);
}
}(1).如果没有volatile 使用-server 运行,发现这个循环线程永远不会停止的,因为这个VolatileStopThread线程永远只在自己的本地存取间本地存取区执行;没有办法做到更新。
(2).volatile 不能代替锁 一般认为volatile 比锁性能好(不绝对),因为比重量级锁好,但在Java中对锁做了大量的优化的
volatile是不能代替锁的,因为他也是线程不安全的,如果有多个线程对这个变量操作他是线程不安全的, 选择使用volatile的条件是:语义是否满足应用。
7.1、可见性
一个线程修改了变量,其他线程可以立即知道
7.2、保证可见性的方法
1、volatile
2、synchronized (unlock之前,写变量值回主存)做线程间的同步,
3、final(一旦初始化完成,其他线程就可见),被定义一些常量,常量在初始化后其他线程就是可见的。
7.3、有序性
在本线程内,操作都是有序的
在线程外观察,操作都是无序的。(无需可能性包块:指令重排 或 主内存同步延时)
7.4、指令重排
1、 线程内串行语义
>写后读 a = 1;b = a; 写一个变量之后,再读这个位置。
> 写后写 a = 1;a = 2; 写一个变量之后,再写这个变量。
> 读后写 a = b;b = 1; 读一个变量之后,再写这个变量。
> 以上语句不可重排
所以重排是看他是否有意义。同时线程内串行语义;也就是无关连得。
>但编译器不考虑多线程间的语义,如下面例子:
>可重排: a=1;b=2;
指令重排与可见性具体原理请看:java高并发实战(三)——Java内存模型和线程安全
7.5、指令重排 – 破坏线程间的有序性
class OrderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1;
flag = true;
}
public void reader() {
if (flag) {
int i = a +1;
……
}
}
}
线程A首先执行writer()方法
线程B线程接着执行reader()方法
线程B在int i=a+1 是不一定能看到a已经被赋值为1
因为在writer中,两句话顺序可能打乱

因为在两个线程他是无需的,编译器是无法保证的,因为线程A完全可能执行,他们是没有关联的,然后在只在在执行线程B,编译器认为先执行线程A和线程B顺序是一样的。这就是线程之间指令重排就破坏的线程之间有序性。但有时需要线程间的有序性,因此下面介绍指令重排保证有序性方法。
7.6、指令重排 – 保证有序性的方法
class OrderExample {
int a = 0;
boolean flag = false;
public synchronized void writer() {
a = 1;
flag = true;
}
public synchronized void reader() {
if (flag) {
int i = a +1;
……
}
}
}
synchronized void writer() {
a = 1;
flag = true;
}
public synchronized void reader() {
if (flag) {
int i = a +1;
……
}
}
}
同步后,即使做了writer重排,因为互斥的缘故,reader 线程看writer线程也是顺序执行的。

线程AB不再是同一级别的,不再是平行的了,属于串行阶段。
7.7、指令重排的基本原则
1.程序顺序原则:一个线程内保证语义的串行性 比如:a=4; b=a+2;
2.volatile规则:volatile变量的写,先发生于读
3.锁规则:解锁(unlock)必然发生在随后的加锁(lock)前
4.传递性:A先于B,B先于C 那么A必然先于C
5.线程的start方法先于它的每一个动作
6.线程的所有操作先于线程的终结(Thread.join())
7.线程的中断(interrupt())先于被中断线程的代码
8.对象的构造函数执行结束先于finalize()方法
8、下面介绍下java字节码的运行方式:
(1)、解释运行(读一句执行一句)
a、解释执行以解释方式运行字节码
b、 解释执行的意思是:读一句执行一句
(2)、 编译运行(JIT=即时编译)(是在运行时将字节码在运行当中编译成机器码)
a、 将字节码编译成机器码
b、 直接执行机器码
c、 编译是在:运行时编译
d、 编译后性能有数量级的提升
编译后的性能是非常高的;保守估计解释执行性能差于编译执行的10倍。
参考资料:https://www.cnblogs.com/dooor/p/5289994.html
https://www.jianshu.com/p/b91258bc08ac
https://blog.csdn.net/qq_25235807/article/details/61920877
http://raising.iteye.com/blog/2377709
其他学习附带延伸: