【高性能Mysql】读书笔记及实践总结
前言:
最近看了一系列mysql文章。对Mysql的基础知识理解有了一些与实践相符合的认知。mark一下。
正文:
MySql基础知识分为四大点:一、并发控制(读/写锁);二、事务;三、多版本并发控制(MVCC);四、存储引擎。
一、并发控制:
总的来说,只存在以下两种锁:
1)、共享锁/读锁
2)、排他锁/写锁
平时我们经常听说各种各样的锁:例如InnoDB共有七种类型的锁如下。都能归入到共享/排他锁两种类型当中。
- 共享/排它锁(Shared and Exclusive Locks)
- 意向锁(Intention Locks)
- 间隙锁(Gap Locks)
- 记录锁(Record Locks)
- 临键锁(Next-key Locks)
- 插入意向锁(Insert Intention Locks)
- 自增锁(Auto-inc Locks)
二、几个并发的例子(此处引擎为InnoDB且隔离级别均为默认隔离级别RR)。
例一、插入并发:
初始化:表结构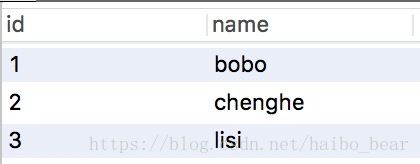
SET NAMES utf8;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for `test`
-- ----------------------------
DROP TABLE IF EXISTS `test`;
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=latin1;
-- ----------------------------
-- Records of `test`
-- ----------------------------
BEGIN;
INSERT INTO `test` VALUES ('1', 'bobo'), ('2', 'chenghe'), ('3', 'lisi');
COMMIT;
SET FOREIGN_KEY_CHECKS = 1;
事务A:insert into test(name) values('xxx');
set session autocommit=0;
start transaction;
insert into test(name) values('xxx');事务B:insert into test(name) values('ooo');
set session autocommit=0;
start transaction;
insert into test(name) values('ooo');测试顺序:事务A——》事务B:隔离级别RR下,事务B未被A阻塞。
实际情况究竟是什么样子的?假如再执行如下即可知:
事务C:
set session autocommit=0;
start transaction;
insert into test(name) values('qqq');
commit;
select * from test;展现结果如下:中间id为4,5缺失。

注意:并且就算将id为4,5的数据回滚,此处位置也不会被后续追加插入。
例二、插入并发(补充):
初始化:表结构

SET NAMES utf8;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for `test`
-- ----------------------------
DROP TABLE IF EXISTS `test`;
CREATE TABLE `test` (
`id` int(11) NOT NULL,
`name` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `un_id` (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
-- ----------------------------
-- Records of `test`
-- ----------------------------
BEGIN;
INSERT INTO `test` VALUES ('10', 'bobo'), ('20', 'chenghe'), ('30', 'lisi');
COMMIT;
SET FOREIGN_KEY_CHECKS = 1;事务A:insert into test(id,name) values (11,'xxxxx');
set session autocommit = 0;
start TRANSACTION;
insert into test(id,name) values (11,'xxxxx');事务B:insert into test(id,name) values (12,'yyyyy');
set session autocommit = 0;
start TRANSACTION;
insert into test(id,name) values (12,'yyyyy');测试顺序:事务A——》事务B:测试结果:事务B不被阻塞。
总结:由例一、例二可知:当插入并发的时候,锁的是主键id所在行。
例三、读写并发
create table `t_2`(
`id` int(10) not null,
`name` VARCHAR(10) not null default '',
`sex` VARCHAR(10) not null default '',
PRIMARY key(`id`)
)ENGINE = INNODB DEFAULT CHARACTER SET utf8;
insert into `t_2` VALUES(1,'bobo','male'),(3,'hebe','female'),
(5,'selina','female'),(9,'ella','female'),(10,'robot','male');
事务A:读事务:select * from t_2 where id BETWEEN 1 and 7 lock in share mode;(手动加s锁/读锁,后续会一并讲读写锁)

set session autocommit = 0;
start TRANSACTION;
select * from t_2 where id BETWEEN 1 and 7 lock in share mode;事务B:写事务:insert into `t_2` VALUES(2,'robot','male');
set session autocommit = 0;
start TRANSACTION;
insert into `t_2` VALUES(2,'robot','male');执行顺序:事务A——》事务B:结果事务B被阻塞。
猜想1:此处被事务A锁全表。导致事务B不可执行;
猜想2:此处被事务A锁了id区间段(1-7);
为了证明以上两个猜想,我做了几个实验,发现不仅1-7被锁住,甚至连id为8也无法插入。然而,id=10却可以插入。实际上事务A锁区间并不是id(1-7)而是id(1-9),如下图;

总结:锁住id为1-9区间段。原因是事务A执行的时候,id=7这条记录在表中找不到。所以锁住从id=1到后一条记录即id=9的区间。也就是说假如我事务A查询范围为id(1,13),当id=13找不到且13大于最大id时,会锁住1到正无穷。反之也是如此。画一张图方便理解。

例四、读写并发(续)
表结构:表还是例三的表。

事务A:select * from t_2 where id=14 lock in share mode;加S锁查询一条不存在的数据。
set session autocommit = 0;
start TRANSACTION;
select * from t_2 where id=14 lock in share mode;事务B:insert into `t_2` VALUES(11,'robot','male');插入一条数据id=11。
set session autocommit = 0;
start TRANSACTION;
insert into `t_2` VALUES(11,'robot','male');执行顺序:事务A——》事务B:事务B被阻塞。
结论:同例三上,锁住10
补充:不知道有没有小伙伴发现,例三、例四的查询我都手动加S锁/读锁。假如不加S锁会怎样。在innodb引擎中,不加锁会因为多版本并发控制(MVCC)快照读。之后会细说快照读,现在只需要理解为,在查询结果是查询时间点查询数据库的一份快照,非原数据,不会阻塞写操作。
三、脏读/不可重复读/幻读/加锁读的几个例子来分析事务四个隔离级别RU/RC/RR/S。
此处附上修改事务隔离级别和问题关系及代码:
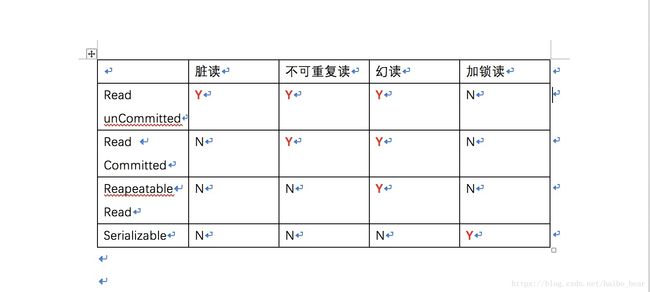
000、查询隔离级别:修改隔离级别:
select @@global.tx_isolation,@@tx_isolation;
set global transaction isolation level read committed;
set session transaction isolation level read committed;
set global transaction isolation level repeatable read;
set session transaction isolation level repeatable read;脏读:事务可以读取未提交的数据。
隔离级别为READ UNCOMMITTED才会出现。举个例子:
表结构上例三如下:
事务A:插入未提交。
set global transaction isolation level read UNCOMMITTED;
set session transaction isolation level read UNCOMMITTED;
select @@global.tx_isolation,@@tx_isolation;
set session autocommit = 0;
start TRANSACTION;
insert into `t_2` VALUES(11,'robot','male');
事务B:查询id>10。
set global transaction isolation level read UNCOMMITTED;
set session transaction isolation level read UNCOMMITTED;
select @@global.tx_isolation,@@tx_isolation;
set session autocommit = 0;
start TRANSACTION;
select * from t_2 where id>9;
执行顺序:事务A——》事务B:事务B能查到如下:产生脏读。
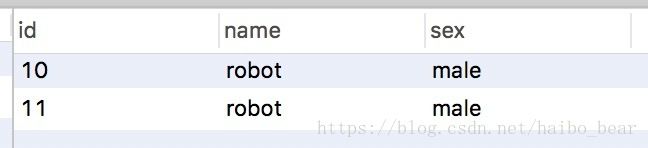
实际工作中很少有这样的情况,毕竟使用读未提交隔离级别的真心没见过。
不可重复读:因为两次执行同样的查询,可能会得到不一样的结果。
隔离级别低于或等于READ COMMITTED才会出现。这个概念比较难理解的地方在于,你会默认想当然的认为只要已经提交commit,就应该能被其它事务看到。实际上,这样就会造成同一个事务,两次查询得到不一样的结果。为了更好理解,因为RR隔离级别能避免这种情况,所以我做了一个对比。
举个例子:
事务RR隔离级别:
set global transaction isolation level REPEATABLE read ;
set session transaction isolation level REPEATABLE read;
select @@global.tx_isolation,@@tx_isolation;事务A:两条查询语句;
set session autocommit = 0;
start TRANSACTION;
select * from t_2 where id>9;
--中间有延时---
select * from t_2 where id>9;
事务B:插入并提交。
set session autocommit = 0;
start TRANSACTION;
insert into `t_2` VALUES(11,'robot','male');
commit;执行顺序:事务A执行到第三行查询,事务B执行完,事务A执行第5行查询。查看两次结果。均看不到id=11的结果。同一事务,两次查询中没有修改,查询结果相同。完美!
将隔离级别改为,事务RC隔离级别:
set global transaction isolation level read COMMITTED;
set session transaction isolation level read COMMITTED;
select @@global.tx_isolation,@@tx_isolation;执行顺序:事务A执行到第三行查询,事务B执行完,事务A执行第5行查询。(同上)查看两次结果。第一次看不到,第二次能看到id=11的结果。同一事务,两次查询中没有修改,查询结果不相同。不可重复读。
PS:其实还是看需求,看同一事务中,是否需要看到已提交的结果。
幻读:当事务A读取某个范围记录时,事务B又在该范围插入新纪录,事务A再次读同一范围记录时,会产生幻行。
隔离级别为低于等于REPEATABLE READ都会出现。(也就是基本上没法避免,除非使用最后一种隔离级别)
其实在一开始例一,已经见到了幻读。只是当时没有在意。在此拎出来单独讲一下。
初始化:表结构(id自增)
SET NAMES utf8;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for `test`
-- ----------------------------
DROP TABLE IF EXISTS `t_3`;
CREATE TABLE `t_3` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=latin1;
-- ----------------------------
-- Records of `test`
-- ----------------------------
BEGIN;
INSERT INTO `t_3` VALUES ('1', 'bobo'), ('2', 'chenghe'), ('3', 'lisi');
COMMIT;
SET FOREIGN_KEY_CHECKS = 1;因为不可重复读这个特性,在rc级别已经被处理。但是,当插入之后。还是会出现一些很奇怪的事。
事务A:
set global transaction isolation level REPEATABLE read ;
set session transaction isolation level REPEATABLE read;
select @@global.tx_isolation,@@tx_isolation;
set session autocommit = 0;
start TRANSACTION;
select * from t_3;
insert into t_3(name) values('simayi');
--中间有延时:其他事务插入---
insert into t_3(name) values('zhugeliang');
select * from t_3;
commit;事务B:
set global transaction isolation level REPEATABLE read ;
set session transaction isolation level REPEATABLE read;
select @@global.tx_isolation,@@tx_isolation;
set session autocommit = 0;
start TRANSACTION;
select * from t_3;
insert into t_3(name) values('caocao');执行顺序:事务B在事务A两个插入之间延时处。
查询结果发现,同一个事务两个连续的插入,中间居然有空行。id=5呢?被事务B吃掉了么?虽然事务B连提交都没有,但是还是吃掉了这个id。幻读由此发生。
加锁读:读取的每一行记录都加锁。
加锁读能解决前面所有的问题:脏读/不可重复读/幻读。但,它自身就是一个问题。每一个都事务都加锁了。那肯定在并发的时候会出现性能瓶颈。所以根据需求权衡是否要采用这种方式。
set global transaction isolation level SERIALIZABLE;
set session transaction isolation level SERIALIZABLE;
select @@global.tx_isolation,@@tx_isolation;四、多版本并发控制(MVCC):
书中MVCC对快照读的定义:只查找早于当前事务版本的数据行。
前面一直在说快照读,快照读到底是怎么一回事。快照读只在RR/RC隔离级别下工作。而且之前读写并发的时候,读写并发的读都不是快照读,说明快照读是一种非阻塞的读。举个例子。
初始化:表结构
例一、同一事务内:
事务A-1:
select @@global.tx_isolation,@@tx_isolation;
set session autocommit = 0;
start TRANSACTION;
select * from t_3;通过以下代码查看当前事务id/事务版本号:执行完事务A-1,事务id=15800
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX;事务A-2:
-----接事务A-1
insert into t_3(name) values('simayi');
select * from t_3;通过上面代码查看当前事务id/事务版本号:执行完事务A-2,事务id依然是=15800
执行顺序:事务A-1-->事务A-2。执行结果。事务A-1:查询结果和表结构相同。事务A-2:查询结果多插入了一条数据。
结论:同一事务不同语句事务版本号唯一。
例二、不同事务内(默认隔离级别RR):
事务A:
select @@global.tx_isolation,@@tx_isolation;
set session autocommit = 0;
start TRANSACTION;
select * from t_3;
----延时事务B执行在此-----
select * from t_3;通过代码查看当前事务id/事务版本号:执行完事务A,事务id=15805;
事务B:
select @@global.tx_isolation,@@tx_isolation;
set session autocommit = 0;
start TRANSACTION;
select * from t_3;
insert into t_3(name) values('simayi');
select * from t_3;通过代码查看当前事务id/事务版本号:执行事务B,未提交时,事务id=15806;
执行顺序:事务A——》事务B (+commit)——》事务A,发现事务A始终事务id=15805,所以不会查到比事务id15805大的数据。
事务C:
select @@global.tx_isolation,@@tx_isolation;
set session autocommit = 0;
start TRANSACTION;
select * from t_3;执行顺序:再执行事务C:事务C事务ID为15807。可以看到事务B提交的结果。
画一张图吧,干巴巴的代码看起来很令人费解。

PS:假如隔离级别为RC:那么事务A两条查询结果将不同。第二条查询语句将会查询到新插入的数据。因为RR级别总是读事务开始时刻的事务快照(15805)。RC级别总是读当前数据行的最新快照(15807)。
此处还有一个知识点:UNDO、REDO日志。略。
五、存储引擎:
存储引擎不打算多讲。大概就是面试题的套路。常用两种InnoDB和MyisAm引擎。两种存储引擎的区别和优缺点及应用场景。默认平时使用InnoDB就够了。略。
六、聚集索引:
首先不打算讲聚集索引和普通索引的区别和联系,打算讲一下有索引和没有索引的区别。虽然我们平时因为MVCC快照读,导致读写不会互相阻塞。但是假如我们使用的是S锁的读。举个例子如下:
初始化:数据表:id为primary key,name 为普通字段,未加索引。(RR隔离级别)
事务A:S锁查询一条不存在的数据。
select @@global.tx_isolation,@@tx_isolation;
set session autocommit = 0;
start TRANSACTION;
select * from t_3 where name = 'zhugeliang' lock in share mode;事务B:任何对已知的索引有读写的操作都执行不了。例如增加一行,需要增加索引。删除一行,需要删除索引。更新一行,需要锁定当前索引行。
select @@global.tx_isolation,@@tx_isolation;
set session autocommit = 0;
start TRANSACTION;
insert into t_3(name) values('caocao');结论:当s锁读一条不存在的记录,当条件字段没索引的时候,会索已知整表索引。凡是写操作(增删改)都将被阻塞。
解决方案:给name字段加普通索引。这样当查找name=‘不存在的记录’ 的索引时查不到,也就不会索对应的聚集索引。
反之引出聚集索引的使用。当查询条件为普通索引的时候,会先根据普通索引查到对应的聚集索引,再通过聚集索引查到value值。假如name为普通索引,id为聚集索引。查询条件为select * from t_3 where name = 'bobo';
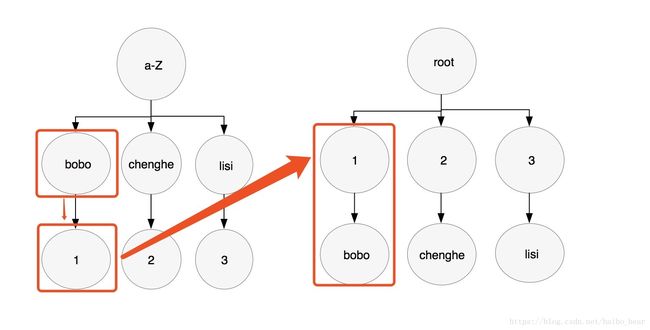
如上,左图为普通索引bobo查找到聚集索引id=1,然后通过聚集索引id=1查找聚集索引上该条数据的其他信息。
写的有点累,有问题再说。~over