Scrapy爬虫框架的介绍,实战
Scrapy介绍
Scrapy是什么?
Scrapy是一套基于Twisted的异步处理框架,是纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容或者各种图片。
Scrapy框架
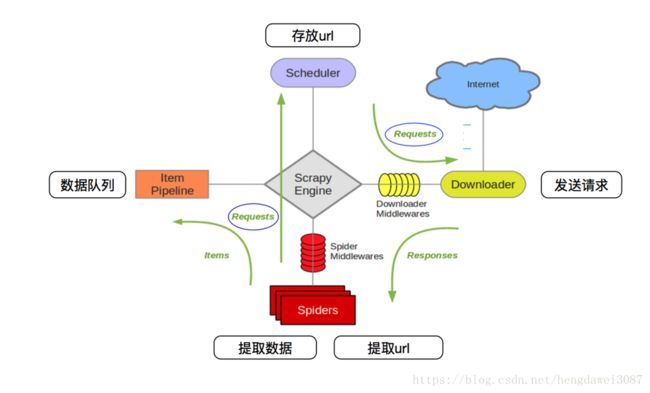
Scrapy Engine:Scrapy引擎相当于一个中枢站,负责Scheduler,Item Pipeline,Downloader和Spiders四个组件之间的通信。例如,将接收到的Spiders的Requests发送给Scheduler,将Spiders的存储请求发送给Item Pipeline。Scheduler发送的Requests,会被引擎提交到Downloader处理,而Downloader处理完成后会发送Responses给引擎,引擎将其发送至Spiders进行处理。
Spiders:相当于一个解析器,负责接收Scrapy Engine发送过来的Responses,对其进行解析,你可以在其内部编写解析的规则。解析好的内容可以发送存储请求给Scrapy Engine。在Spiders中解析出的新的url,可以向Scrapy Engine发送Requests请求。注意,入口url也是存储在Spiders中。
Downloader:下载器即对发送过来的url进行下载,并将下载好的网页反馈给Scrapy Engine。
Schedular:你可以把他理解成一个对列,存储Scrapy Engine发送过来的url,并按顺序取出url发送给Scrapy Engine进行requests操作。
Item Pipeline:在Item中你可以定义你的存储结构,方便数据存储。而在Pipeline中,你可以对数据进行存储操作,例如将数据存储至数据库,或者以csv格式存贮本地。
Downloader Middlewares:你可以在其中对ip进行代理,或封装自己的头文件,应对一些反爬虫机制。
Spider Middlewares:你可以添加代码来处理发送给 Spiders 的 response 及 spider 产生的 item 和 request。
创建scrapy爬虫项目
第一步,我们先来创建一个scrapy的爬虫项目。打开cmd,来到要创建的目录中输入以下命令。

创建成功后,将项目导入至PyCharm中
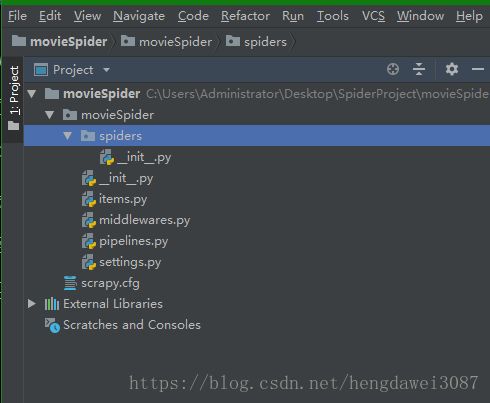
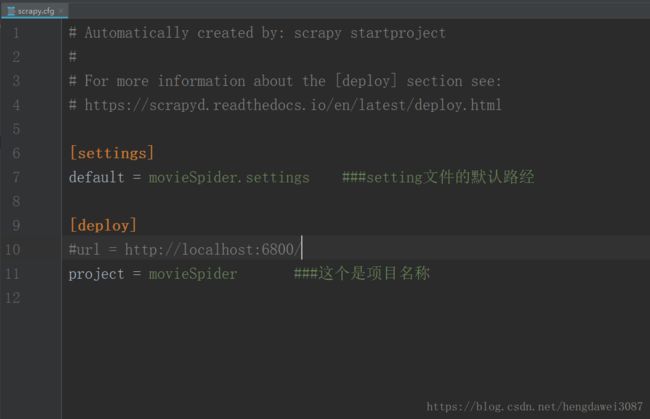
先来看配置文件scrapy.cfg。
setting.py文件中可以进行爬虫配置的设置
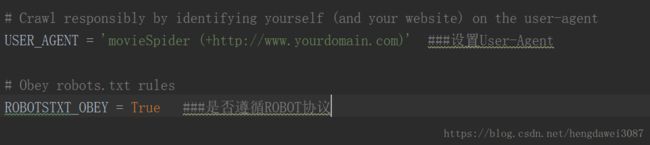

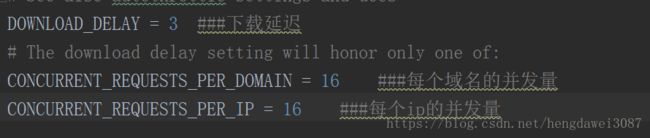

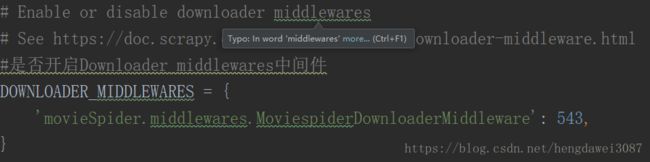
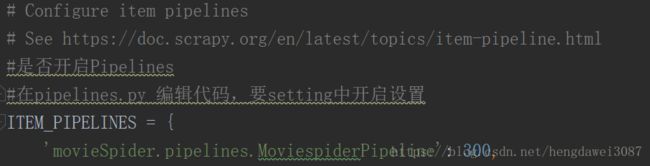
其它设置在以后开发项目中需要时再进行介绍,这里就不一一赘述(其实我也不太清楚,但不着急,慢慢来)
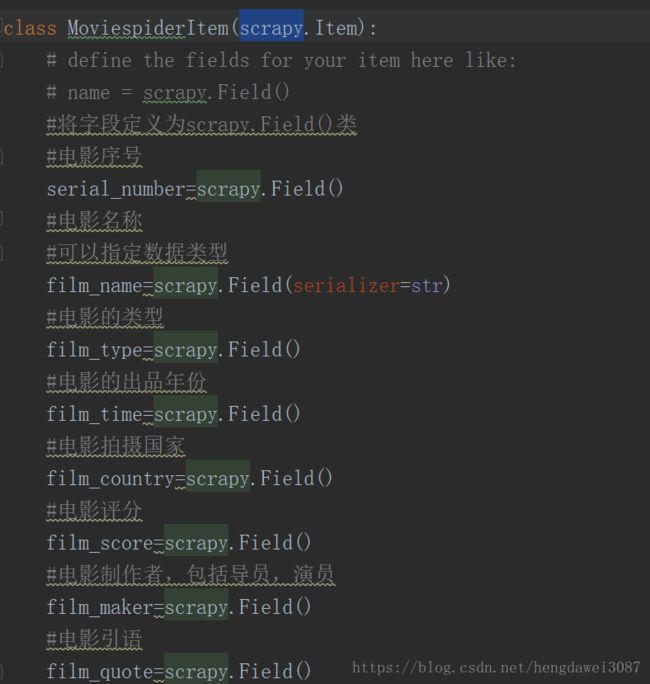
Item.py文件是用来定义存储结构的地方。
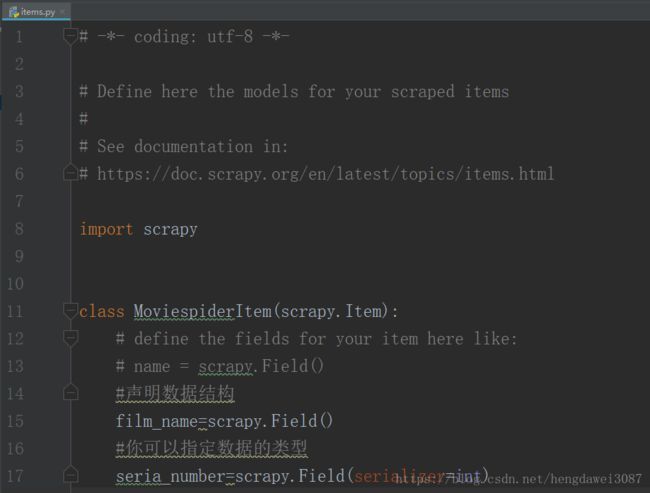
所以编写解析规则的spider文件在哪?是的,确实没找到,这里我们要用命令行生成spider文件,来到项目目录,输入一下命令。

这时我们就可以看到目录中已经生成了movie_spider.py文件,现在我们就可以在这里写解析规则了。
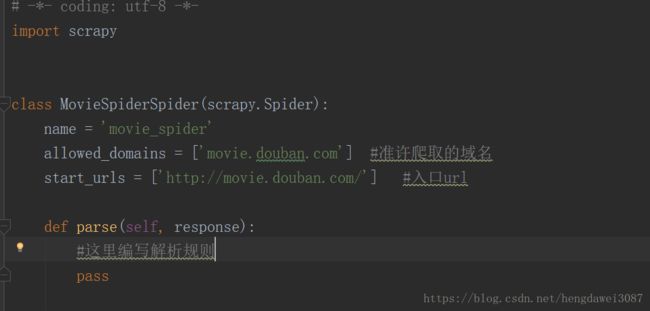
其它的我也不多做赘述,在下面的爬虫实战中会再详细说明。
Scrapy实战
目标
爬取豆瓣电影top250的所有电影信息,将信息存储至数据库。
分析
打开网页https://movie.douban.com/top250,分析我们要爬取的内容。
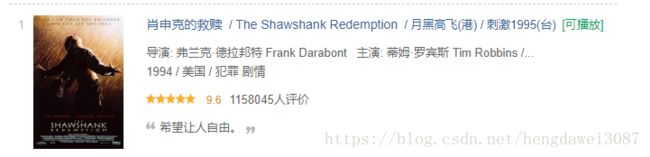
我们需要抓取电影的排名、名字、出品年份等信息。先在Item.py中定义数据结构。
再来分析一下网页源码,通过XPath规则定位到电影信息标签
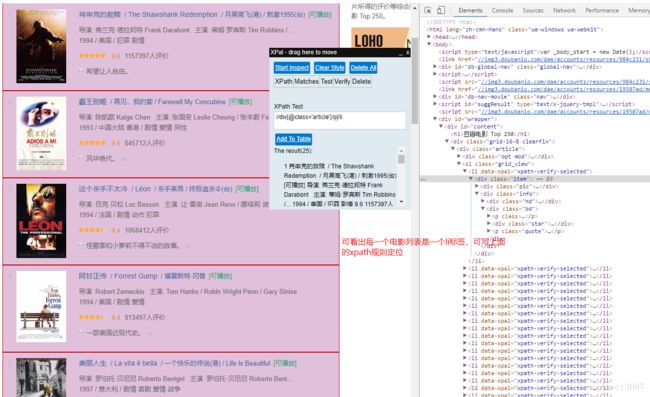
现在我们就开始爬虫
我们现在先编写spider文件
def parse(self, response):
#爬取电影item
movie_item=response.xpath("//div[@class='article']/ol/li")
for item in movie_item:
#创建存储对象
movieItem=MoviespiderItem()
#爬取电影信息
#电影序号
movieItem['serial_number']=item.xpath(".//div/div/em/text()").extract_first()
#电影名称
movieItem['film_name'] = item.xpath(".//div/div/div/a/span[@class='title']/text()").extract_first()
#电影的年份 制作人等信息
info_item=item.xpath(".//div/div/div[@class='bd']/p[1]/text()").extract()
#电影制作人
movieItem['film_maker']="".join(info_item[0].split())
#电影年份
movieItem['film_time'] =(''.join(info_item[1].split())).split('/')[0]
#电影出品国家
movieItem['film_country'] = (''.join(info_item[1].split())).split('/')[1]
#电影类型
movieItem['film_type'] = (''.join(info_item[1].split())).split('/')[2]
#电影引用
movieItem['film_quote'] = item.xpath(".//div/div/div[@class='bd']/p[2]/span/text()").extract_first()
#电影评分
movieItem['film_score'] = item.xpath(".//div/div/div[@class='bd']/div/span[@class='rating_num']/text()").extract_first()
#将数据传到pipeline
yield movieItem
#解析下一页url
next_page=response.xpath("//div[@class='paginator']/span[@class='next']/link/@href").extract()
#判断是否有下一页
if next_page:
next_page=next_page[0]
url=self.start_urls[0]+next_page
#将下一页url传给调度器
yield scrapy.Request(url,callback=self.parse)我们来运行一下,是否能够爬取到我们所需要的内容。在cmd命令行中输入命令
E:\code\Python\python spider\movieSpider>scrapy crawl movieSpider爬取结果
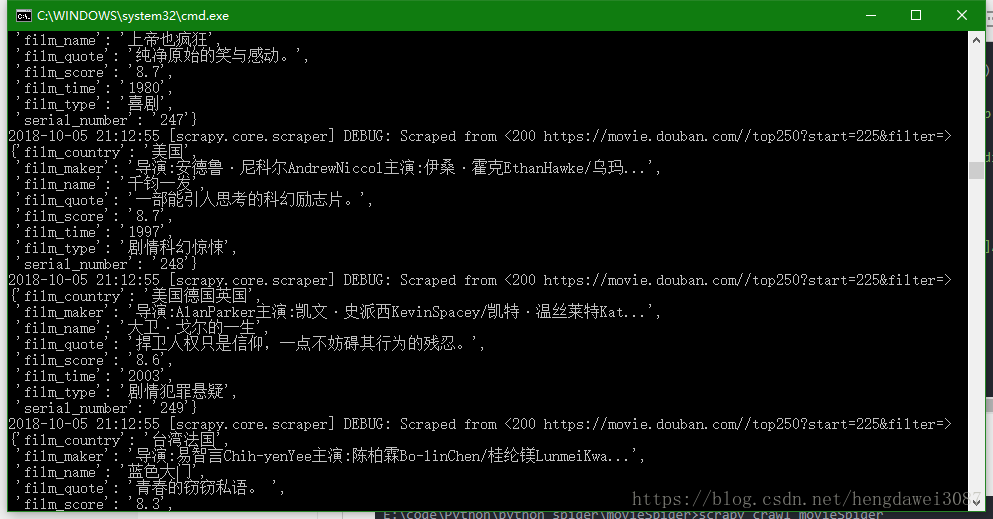
可以看到我们已经爬取到了需要的内容。不过有一点需要注意,爬取前要在setting.py中设置User-Agent
![]()
既然爬取到内容,就要对内容进行存储,先来说如何存储到本地。以csv文件存至本地只需要输入以下命令
E:\code\Python\python spider\movieSpider>scrapy crawl movie_spider -o movie_list.csv运行后我们可以来到爬虫目录中查看到我们保存的csv文件
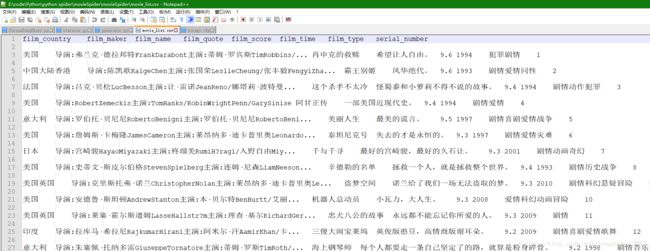
相对于保存至本地,将我们的爬虫项目保存至数据库中,更方便我们对数据进行操作,也更适应企业要求。这里我使用的是mysql数据库,我们需要先创建数据库,在创建存贮内容的表,这一过程我就略过了,现在主要讲我们如何连接数据库,并将内容进行保存。首先我们要明确一点,我们在Scrapy项目的哪一组件进行这一操作,在文章的开头已经描述过,Pipeline组件是用来进行数据存储的。我们先来setting文件中设置我们的mysql参数,这样也更方便今后的操作,也更有逻辑性。
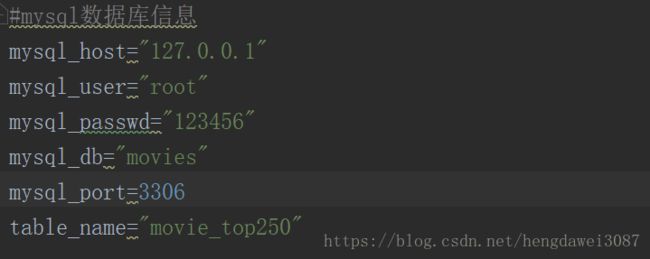
再来我们就可以在Pipeline中进行存储操作了
# -*- coding: utf-8 -*-
import pymysql
from movieSpider.settings import table_name,mysql_port,mysql_db,mysql_passwd,mysql_user,mysql_host
class MoviespiderPipeline(object):
def __init__(self):
#连接数据库
#self.conn=pymysql.connect(host=host,port=port,user=user,password=passwd,db=database,charset='utf8')
self.conn = pymysql.connect(host=mysql_host, user=mysql_user, password=mysql_passwd, db=mysql_db,port=mysql_port)
#创建游标对象
self.cur=self.conn.cursor()
def process_item(self, item, spider):
#将item转化为dict类型
data=dict(item)
#将数据插入数据库
self.cur.execute("INSERT INTO movie_top250 (serial_number,film_name,film_country,film_time,film_type,film_maker,film_score,film_quote) VALUE (%(serial_number)s,%(film_name)s,%(film_country)s,%(film_time)s,%(film_type)s,%(film_maker)s,%(film_score)s,%(film_quote)s)",data)
self.conn.commit()
return item我们来运行一下,看是否保存到数据库,运行前记得,要在setting中开启pipeline
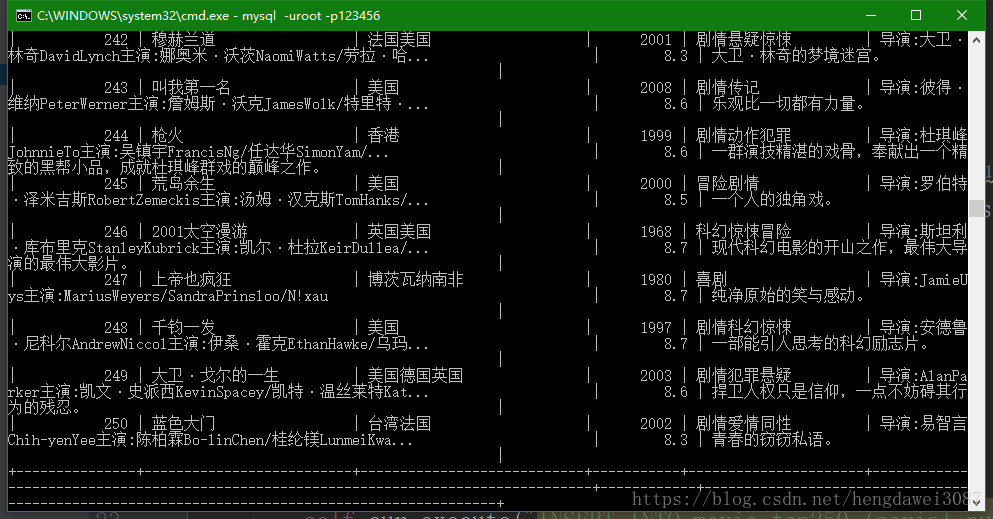
最后,我们再来讲一下基本的反爬机制,主要有设置头文件中的User-Agent,设置代理ip,我就讲讲前面一种方法,因为后一种方法需要代理服务器,我买不起,也就不讲了。这里又该在哪里写我们的代码呢,我们再回去看看文章开头的j框架图,显然,我们需要在Downloader middlwares中实现。来到middlwares.py文件中,声明一个类,在类内的默认函数process_request中进行实现。当然,再次提醒,我们需要在setting文件中开启此方法。

class random_user_agent(object):
def process_request(self,request,spider):
#user_agent设备列表
USER_AGENT_LIST = ['MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23',
'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)',
'Opera/9.0 (Macintosh; PPC Mac OS X; U; en)',
'iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)',
'Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)',
'iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0',
'Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)',
'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)']
#从USER_AGENT_LIST随机选择
user_agent=random.choice(USER_AGENT_LIST)
request.headers["User_Agent"]=user_agent
总结
这篇文章只能算是scrapy爬虫的一个入门,在各式各样的需求中,爬虫项目要比这复杂的多,而且网站的反爬机制也复杂的多,需要学的还很多,此文章是为了加深自己的记忆和理解,也是想给刚入门的人一个参考,文章有什么错误的地方,希望各位大佬指出,也希望给我一些指点和帮助