Python爬虫入门教程 2-100 妹子图网站爬取
妹子图网站----前言
从今天开始就要撸起袖子,直接写Python爬虫了,学习语言最好的办法就是有目的的进行,所以,接下来我将用10+篇的博客,写爬图片这一件事情。希望可以做好。
为了写好爬虫,我们需要准备一个火狐浏览器,还需要准备抓包工具,抓包工具,我使用的是CentOS自带的tcpdump,加上wireshark ,这两款软件的安装和使用,建议你还是学习一下,后面我们应该会用到。
妹子图网站---- 网络请求模块requests
Python中的大量开源的模块使得编码变的特别简单,我们写爬虫第一个要了解的模块就是requests。
妹子图网站---- 安装requests
打开终端:使用命令
pip3 install requests
等待安装完毕即可使用
接下来在终端中键入如下命令
# mkdir demo
# cd demo
# touch down.py
上面的linux命令是 创建一个名称为demo的文件夹,之后创建一个down.py文件,你也可以使用GUI工具,像操作windows一样,右键创建各种文件。
为了提高在linux上的开发效率,我们需要安装一个visual studio code 的开发工具
对于怎么安装vscode,参考官方的https://code.visualstudio.com/docs/setup/linux 有详细的说明。
对于centos则如下:
sudo rpm --import https://packages.microsoft.com/keys/microsoft.asc
sudo sh -c 'echo -e "[code]\nname=Visual Studio Code\nbaseurl=https://packages.microsoft.com/yumrepos/vscode\nenabled=1\ngpgcheck=1\ngpgkey=https://packages.microsoft.com/keys/microsoft.asc" > /etc/yum.repos.d/vscode.repo'
然后用yum命令安装
yum check-update
sudo yum install code
安装成功之后,在你的CentOS中会出现如下画面
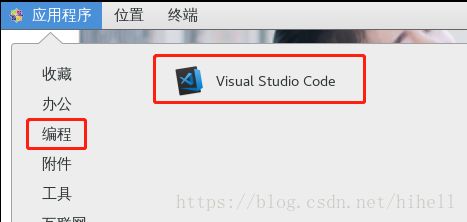
接着说我们上面的操作 ,因为我们这边是用gnome图形界面,所以后面的有些操作,我直接用windows的操作风格讲解了
打开软件>文件>打开文件>找到我们刚刚创建的down.py文件
之后,在VSCODE里面输入
import requests #导入模块
def run(): #声明一个run方法
print("跑码文件") #打印内容
if __name__ == "__main__": #主程序入口
run() #调用上面的run方法
tips:本教程不是Python3的基础入门课,所以有些编码基础,默认你懂,比如Python没有分号结尾,需要对齐格式。我会尽量把注释写的完整
按键盘上的ctrl+s保存文件,如果提示权限不足,那么按照提示输入密码即可
通过终端进入demo目录,然后输入
python3 down.py
显示如下结果,代表编译没有问题
[root@bogon demo]# python3 down.py
跑码文件
接下来,我们开始测试requests模块是否可以使用
修改上述代码中的
import requests
def run():
response = requests.get("http://www.baidu.com")
print(response.text)
if __name__ == "__main__":
run()
运行结果(出现下图代表你运行成功了):

接下来,我们实际下载一张图片试试,比如下面这张图片

修改代码,在这之前,我们修改一些内容
由于每次修改文件,都提示必须管理员权限,所以你可以使用linux命令修改权限。
[root@bogon linuxboy]# chmod -R 777 demo/
import requests
def run():
response = requests.get("http://www.newsimg.cn/big201710leaderreports/xibdj20171030.jpg")
with open("xijinping.jpg","wb") as f :
f.write(response.content)
f.close
if __name__ == "__main__":
run()
运行代码之后,发现在文件夹内部生成了一个文件
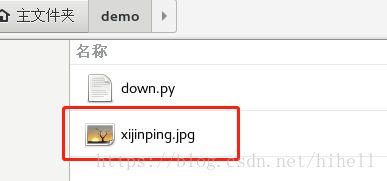
但是打开文件之后发现,这个文件并不能查阅,这代表这个文件压根没有下载下来
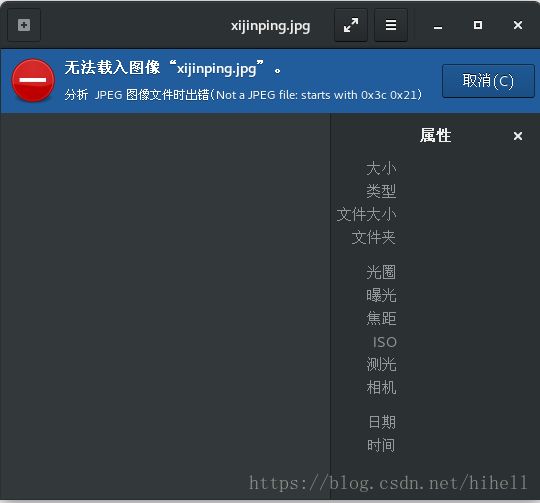
我们继续修改代码,因为有的服务器图片,都做了一些限制,我们可以用浏览器打开,但是使用Python代码并不能完整的下载下来。
修改代码
import requests
def run():
# 头文件,header是字典类型
headers = {
"Host":"www.newsimg.cn",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5383.400 QQBrowser/10.0.1313.400"
}
response = requests.get("http://www.newsimg.cn/big201710leaderreports/xibdj20171030.jpg",headers=headers)
with open("xijinping.jpg","wb") as f :
f.write(response.content)
f.close()
if __name__ == "__main__":
run()
好了,这次在终端编译一下python文件
python3 down.py
发现图片下载下来了
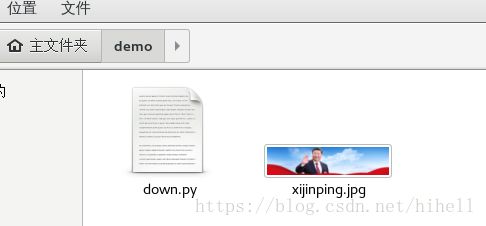
我们重点查看上述代码中 requests.get部分,添加了一个headers的实参。这样我们程序就下载下来了完整的图片。
妹子图网站---- Python爬虫页面分析
有了上面这个简单的案例,我们接下来的操作就变的简单多了。爬虫是如何进行的呢?
输入域名->下载源代码->分析图片路径->下载图片
上面就是他的步骤
输入域名
我们今天要爬的网站叫做 http://www.meizitu.com/a/pure.html
为啥爬取这个网站,因为好爬。
好了,接下来分析这个页面
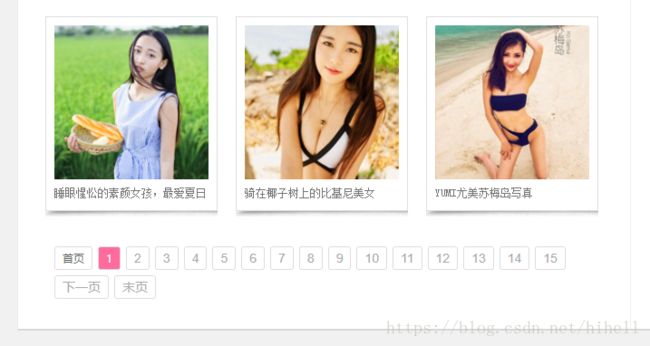
做爬虫很重要的一点,就是你要找到分页的地方,因为有分页代表着有规律,有规律,我们就好爬了(可以做的更智能一些,输入首页网址,爬虫自己就能分析到这个网站中的所有地址)
上面图片中,我们发现了分页,那么找规律吧

使用火狐浏览器的开发者工具,发现分页规律
http://www.meizitu.com/a/pure_1.html
http://www.meizitu.com/a/pure_2.html
http://www.meizitu.com/a/pure_3.html
http://www.meizitu.com/a/pure_4.html
好了,接下来用Python实现这部分(以下写法有部分面向对象的写法,没有基础的同学,请百度找些基础来看,不过对于想学习的你来说,这些简单极了)
import requests
all_urls = [] #我们拼接好的图片集和列表路径
class Spider():
#构造函数,初始化数据使用
def __init__(self,target_url,headers):
self.target_url = target_url
self.headers = headers
#获取所有的想要抓取的URL
def getUrls(self,start_page,page_num):
global all_urls
#循环得到URL
for i in range(start_page,page_num+1):
url = self.target_url % i
all_urls.append(url)
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0',
'HOST':'www.meizitu.com'
}
target_url = 'http://www.meizitu.com/a/pure_%d.html' #图片集和列表规则
spider = Spider(target_url,headers)
spider.getUrls(1,16)
print(all_urls)
上面的代码,可能需要有一定的Python基础可以看懂,不过你其实仔细看一下,就几个要点
第一个是 class Spider(): 我们声明了一个类,然后我们使用 def __init__去声明一个构造函数,这些我觉得你找个教程30分钟也就学会了。
拼接URL,我们可以用很多办法,我这里用的是最直接的,字符串拼接。
注意上述代码中有一个全局的变量 all_urls 我用它来存储我们的所有分页的URL
接下来,是爬虫最核心的部分代码了
我们需要分析页面中的逻辑。首先打开 http://www.meizitu.com/a/pure_1.html ,右键审查元素。
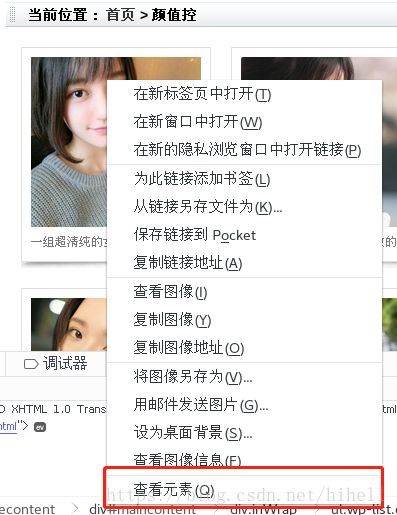
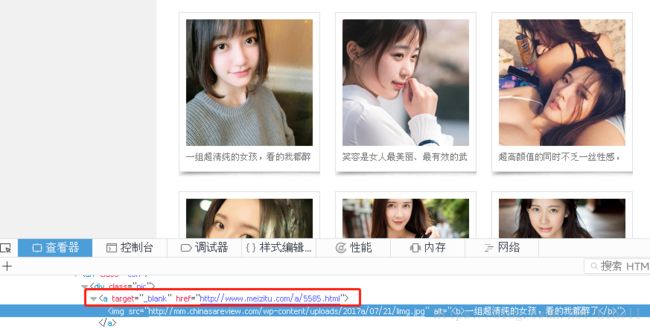
发现上图红色框框里面的链接
点击图片之后,发现进入一个图片详情页面,发现竟然是一组图片,那么现在的问题是
我们要解决第一步,需要在 http://www.meizitu.com/a/pure_1.html 这种页面中爬取所有的 http://www.meizitu.com/a/5585.html 这种地址
这里我们采用多线程的方式爬取(这里还用了一种设计模式,叫观察者模式)
import threading #多线程模块
import re #正则表达式模块
import time #时间模块
首先引入三个模块,分别是多线程,正则表达式,时间模块
新增加一个全局的变量,并且由于是多线程操作,我们需要引入线程锁
all_img_urls = [] #图片列表页面的数组
g_lock = threading.Lock() #初始化一个锁
声明一个生产者的类,用来不断的获取图片详情页地址,然后添加到 all_img_urls 这个全局变量中
#生产者,负责从每个页面提取图片列表链接
class Producer(threading.Thread):
def run(self):
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0',
'HOST':'www.meizitu.com'
}
global all_urls
while len(all_urls) > 0 :
g_lock.acquire() #在访问all_urls的时候,需要使用锁机制
page_url = all_urls.pop() #通过pop方法移除最后一个元素,并且返回该值
g_lock.release() #使用完成之后及时把锁给释放,方便其他线程使用
try:
print("分析"+page_url)
response = requests.get(page_url , headers = headers,timeout=3)
all_pic_link = re.findall('',response.text,re.S)
global all_img_urls
g_lock.acquire() #这里还有一个锁
all_img_urls += all_pic_link #这个地方注意数组的拼接,没有用append直接用的+=也算是python的一个新语法吧
print(all_img_urls)
g_lock.release() #释放锁
time.sleep(0.5)
except:
pass
上述代码用到了继承的概念,我从threading.Thread中继承了一个子类,继承的基础学习,你可以去翻翻 http://www.runoob.com/python3/python3-class.html 菜鸟教程就行。
线程锁,在上面的代码中,当我们操作all_urls.pop()的时候,我们是不希望其他线程对他进行同时操作的,否则会出现意外,所以我们使用g_lock.acquire()锁定资源,然后使用完成之后,记住一定要立马释放g_lock.release(),否则这个资源就一直被占用着,程序无法进行下去了。
匹配网页中的URL,我使用的是正则表达式,后面我们会使用其他的办法,进行匹配。
re.findall()方法是获取所有匹配到的内容,正则表达式,你可以找一个30分钟入门的教程,看看就行。
代码容易出错的地方,我放到了
try: except: 里面,当然,你也可以自定义错误。
如果上面的代码,都没有问题,那么我们就可以在程序入口的地方编写
for x in range(2):
t = Producer()
t.start()
执行程序,因为我们的Producer继承自threading.Thread类,所以,你必须要实现的一个方法是 def run 这个我相信在上面的代码中,你已经看到了。然后我们可以执行啦~~~
运行结果:
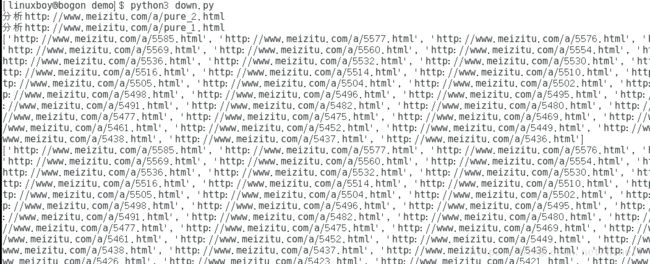
这样,图片详情页面的列表就已经被我们存储起来了。
接下来,我们需要执行这样一步操作,我想要等待图片详情页面全部获取完毕,在进行接下来的分析操作。
这里增加代码
#threads= []
#开启两个线程去访问
for x in range(2):
t = Producer()
t.start()
#threads.append(t)
# for tt in threads:
# tt.join()
print("进行到我这里了")
注释关键代码,运行如下
[linuxboy@bogon demo]$ python3 down.py
分析http://www.meizitu.com/a/pure_2.html
分析http://www.meizitu.com/a/pure_1.html
进行到我这里了
['http://www.meizitu.com/a/5585.html',
把上面的tt.join等代码注释打开
[linuxboy@bogon demo]$ python3 down.py
分析http://www.meizitu.com/a/pure_2.html
分析http://www.meizitu.com/a/pure_1.html
['http://www.meizitu.com/a/5429.html', ......
进行到我这里了
发现一个本质的区别,就是,我们由于是多线程的程序,所以,当程序跑起来之后,print("进行到我这里了")不会等到其他线程结束,就会运行到,但是当我们改造成上面的代码之后,也就是加入了关键的代码 tt.join() 那么主线程的代码会等到所以子线程运行完毕之后,在接着向下运行。这就满足了,我刚才说的,先获取到所有的图片详情页面的集合,这一条件了。
join所完成的工作就是线程同步,即主线程遇到join之后进入阻塞状态,一直等待其他的子线程执行结束之后,主线程在继续执行。这个大家在以后可能经常会碰到。
下面编写一个消费者/观察者,也就是不断关注刚才我们获取的那些图片详情页面的数组。
添加一个全局变量,用来存储获取到的图片链接
pic_links = [] #图片地址列表
#消费者
class Consumer(threading.Thread) :
def run(self):
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0',
'HOST':'www.meizitu.com'
}
global all_img_urls #调用全局的图片详情页面的数组
print("%s is running " % threading.current_thread)
while len(all_img_urls) >0 :
g_lock.acquire()
img_url = all_img_urls.pop()
g_lock.release()
try:
response = requests.get(img_url , headers = headers )
response.encoding='gb2312' #由于我们调用的页面编码是GB2312,所以需要设置一下编码
title = re.search('(.*?) | 妹子图 ',response.text).group(1)
all_pic_src = re.findall('![.*?src="(.*?)"]()
',response.text,re.S)
pic_dict = {title:all_pic_src} #python字典
global pic_links
g_lock.acquire()
pic_links.append(pic_dict) #字典数组
print(title+" 获取成功")
g_lock.release()
except:
pass
time.sleep(0.5)
看到没有,上面的代码其实和我们刚才写的极其相似,后面,我会在github上面把这部分代码修改的更加简洁一些,不过这才是第二课,后面我们的路长着呢。
代码中比较重要的一些部分,我已经使用注释写好了,大家可以直接参考。大家一定要注意我上面使用了两个正则表达式,分别用来匹配title和图片的url这个title是为了后面创建不同的文件夹使用的,所以大家注意吧。
#开启10个线程去获取链接
for x in range(10):
ta = Consumer()
ta.start()
运行结果:
[linuxboy@bogon demo]$ python3 down.py
分析http://www.meizitu.com/a/pure_2.html
分析http://www.meizitu.com/a/pure_1.html
['http://www.meizitu.com/a/5585.html', ......
is running
is running
is running
is running
is running
is running
is running
is running
进行到我这里了
is running
is running
清纯美如画,摄影师的御用麻豆 获取成功
宅男女神叶梓萱近日拍摄一组火爆写真 获取成功
美(bao)胸(ru)女王带来制服诱惑 获取成功
每天睁开眼看到美好的你,便是幸福 获取成功
可爱女孩,愿暖风呵护纯真和执着 获取成功
清纯妹子如一缕阳光温暖这个冬天 获取成功 .....
是不是感觉距离成功有进了一大步
接下来就是,我们开篇提到的那个存储图片的操作了,还是同样的步骤,写一个自定义的类
class DownPic(threading.Thread) :
def run(self):
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0',
'HOST':'mm.chinasareview.com'
}
while True: # 这个地方写成死循环,为的是不断监控图片链接数组是否更新
global pic_links
# 上锁
g_lock.acquire()
if len(pic_links) == 0: #如果没有图片了,就解锁
# 不管什么情况,都要释放锁
g_lock.release()
continue
else:
pic = pic_links.pop()
g_lock.release()
# 遍历字典列表
for key,values in pic.items():
path=key.rstrip("\\")
is_exists=os.path.exists(path)
# 判断结果
if not is_exists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
print (path+'目录创建成功')
else:
# 如果目录存在则不创建,并提示目录已存在
print(path+' 目录已存在')
for pic in values :
filename = path+"/"+pic.split('/')[-1]
if os.path.exists(filename):
continue
else:
response = requests.get(pic,headers=headers)
with open(filename,'wb') as f :
f.write(response.content)
f.close
我们获取图片链接之后,就需要下载了,我上面的代码是首先创建了一个之前获取到title的文件目录,然后在目录里面通过下面的代码,去创建一个文件。
涉及到文件操作,引入一个新的模块
import os #目录操作模块
# 遍历字典列表
for key,values in pic.items():
path=key.rstrip("\\")
is_exists=os.path.exists(path)
# 判断结果
if not is_exists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
print (path+'目录创建成功')
else:
# 如果目录存在则不创建,并提示目录已存在
print(path+' 目录已存在')
for pic in values :
filename = path+"/"+pic.split('/')[-1]
if os.path.exists(filename):
continue
else:
response = requests.get(pic,headers=headers)
with open(filename,'wb') as f :
f.write(response.content)
f.close
因为我们的图片链接数组,里面存放是的字典格式,也就是下面这种格式
[{"妹子图1":["http://mm.chinasareview.com/wp-content/uploads/2016a/08/24/01.jpg","http://mm.chinasareview.com/wp-content/uploads/2016a/08/24/02.jpg"."http://mm.chinasareview.com/wp-content/uploads/2016a/08/24/03.jpg"]},{"妹子图2":["http://mm.chinasareview.com/wp-content/uploads/2016a/08/24/01.jpg","http://mm.chinasareview.com/wp-content/uploads/2016a/08/24/02.jpg"."http://mm.chinasareview.com/wp-content/uploads/2016a/08/24/03.jpg"]},{"妹子图3":["http://mm.chinasareview.com/wp-content/uploads/2016a/08/24/01.jpg","http://mm.chinasareview.com/wp-content/uploads/2016a/08/24/02.jpg"."http://mm.chinasareview.com/wp-content/uploads/2016a/08/24/03.jpg"]}]
需要先循环第一层,获取title,创建目录之后,在循环第二层去下载图片,代码中,我们在修改一下,把异常处理添加上。
try:
response = requests.get(pic,headers=headers)
with open(filename,'wb') as f :
f.write(response.content)
f.close
except Exception as e:
print(e)
pass
然后在主程序中编写代码
#开启10个线程保存图片
for x in range(10):
down = DownPic()
down.start()
运行结果:
[linuxboy@bogon demo]$ python3 down.py
分析http://www.meizitu.com/a/pure_2.html
分析http://www.meizitu.com/a/pure_1.html
['http://www.meizitu.com/a/5585.html', 'http://www.meizitu.com/a/5577.html', 'http://www.meizitu.com/a/5576.html', 'http://www.meizitu.com/a/5574.html', 'http://www.meizitu.com/a/5569.html', .......
is running
is running
is running
进行到我这里了
清纯妹子如一缕阳光温暖这个冬天 获取成功
清纯妹子如一缕阳光温暖这个冬天目录创建成功
可爱女孩,愿暖风呵护纯真和执着 获取成功
可爱女孩,愿暖风呵护纯真和执着目录创建成功
超美,纯纯的你与蓝蓝的天相得益彰 获取成功
超美,纯纯的你与蓝蓝的天相得益彰目录创建成功
美丽冻人,雪地里的跆拳道少女 获取成功
五官精致的美眉,仿佛童话里的公主 获取成功
有自信迷人的笑容,每天都是灿烂的 获取成功
五官精致的美眉,仿佛童话里的公主目录创建成功
有自信迷人的笑容,每天都是灿烂的目录创建成功
清纯美如画,摄影师的御用麻豆 获取成功
文件目录下面同时出现
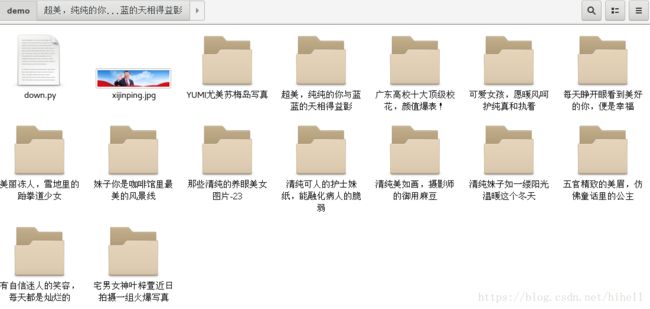
点开一个目录

好了,今天的一个简单的爬虫成了
最后我们在代码的头部写上
# -*- coding: UTF-8 -*-
防止出现 Non-ASCII character 'xe5' in file报错问题。
欢迎关注「非本科程序员」 回复 【妹子图】获取资源
