【表情识别】数据集处理
数据集采用的是fer2013,该如果不想麻烦自己去官网下载,可以贡献一分( ̄▽ ̄)到
https://download.csdn.net/download/idwtwt/10590806
fer2013.tar.gz解压之后可以得到fer2013.csv,想了解csv格式请自行百度,该格式文件可以用office表格软件打开
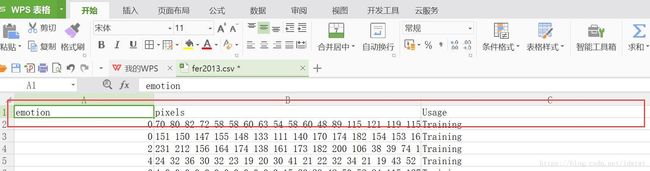
可以看到其实就三列——emotion,pixels,Usage
emotion:标签,共有7个标签,分别是:0=Angry, 1=Disgust, 2=Fear, 3=Happy, 4=Sad, 5=Surprise, 6=Neutral
pixels:人脸表情图片数据,是48*48个像素点。
Usage:有三种值Training,PublicTest,PrivateTest
些图片文件件可以使用opencv-python库
# Courtesy of Kaggle user 'NoBugs'
# Transforms string of numbers in .csv to image and saves it
import numpy as np
import cv2
import pandas as pd
import random
import os
curdir = os.path.abspath(os.path.dirname(__file__))
def gen_record(csvfile,channel):
data = pd.read_csv(csvfile,delimiter=',',dtype='a')
labels = np.array(data['emotion'],np.float)
imagebuffer = np.array(data['pixels'])
#删掉空格,每个图片转化为数组
images = np.array([np.fromstring(image,np.uint8,sep=' ') for image in imagebuffer])
#s释放临时buff
del imagebuffer
#最后一个维度的大小
num_shape = int(np.sqrt(images.shape[-1]))
#调整数组为48*48图片
images.shape = (images.shape[0],num_shape,num_shape)
# 三种Training,PublicTest,PrivateTest
dirs = set(data['Usage'])
class_dir = {}
for dr in dirs:
dest = os.path.join(curdir,dr)
class_dir[dr] = dest
if not os.path.exists(dest):
os.mkdir(dest)
data = zip(labels,images,data['Usage'])
for d in data:
label = int(d[0])
#根据标签存放图片到不同文件夹
destdir = os.path.join(class_dir[d[2]],str(label))
if not os.path.exists(destdir):
os.mkdir(destdir)
img = d[1]
filepath = unique_name(destdir,d[2])
print('[^_^] Write image to %s' % filepath)
if not filepath:
continue
sig = cv2.imwrite(filepath,img)
if not sig:
print('Error')
exit(-1)
def unique_name(pardir,prefix,suffix='jpg'):
#生成随机文件名
filename = '{0}_{1}.{2}'.format(prefix,random.randint(1,10**8),suffix)
filepath = os.path.join(pardir,filename)
if not os.path.exists(filepath):
return filepath
unique_name(pardir,prefix,suffix)
if __name__ == '__main__':
filename = './fer2013/fer2013.csv'
filename = os.path.join(curdir,filename)
gen_record(filename,1)
完成之后,图片数据分放到三个文件夹:Training,PublicTest,PrivateTest,在每个文件夹内,有包含0-6共七个文件夹,没分存放不同标签的表情图片。而实际上数据集不是特别大,完全可以考虑直接放在内存中,而不是转换为图片文件,一张一张地读取数据。
def _load_fer2013(self):
data = pd.read_csv(self.dataset_path)
pixels = data['pixels'].tolist()
width, height = 48, 48
faces = []
for pixel_sequence in pixels:
face = [int(pixel) for pixel in pixel_sequence.split(' ')]
# 将数组转换为48*48的二维矩阵
face = np.asarray(face).reshape(width, height)
#根据需要缩放
face = cv2.resize(face.astype('uint8'), self.image_size)
faces.append(face.astype('float32'))
faces = np.asarray(faces)
faces = np.expand_dims(faces, -1)
emotions = pd.get_dummies(data['emotion']).as_matrix()
return faces, emotions