阿里大佬带你,深入理解线程池底层原理
线程池
为什么要使用线程池
在实际使用中,线程是很占用系统资源的,如果对线程管理不善很容易导致系统问题。 因此,在大多数并发框架中都会使用线程池来管理线程,使用线程池管理线程主要有如下好处:
(1)降低资源消耗。通过复用已存在的线程和降低线程关闭的次数来尽可能降低系统性能损耗
(2)提升系统响应速度。通过复用线程,省去创建线程的过程,因此整体上提升了系统的响应速度
(3)提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源, 还会降低系统的稳定性,因此,需要使用线程池来管理线程。
线程池的工作原理
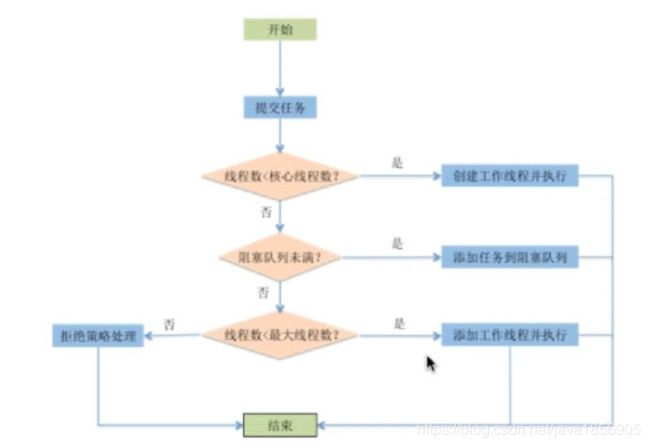
当一个并发任务提交给线程池,线程池分配线程去执行任务的过程如下:
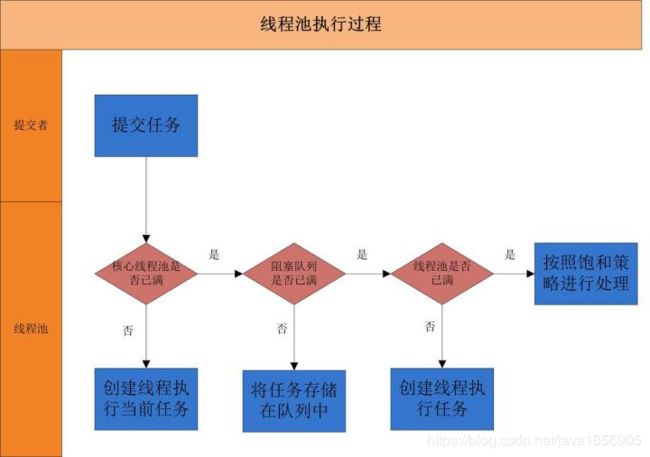
线程池执行所提交的任务过程主要有这样几个阶段:
(1)先判断线程池中核心线程池所有的线程是否都在执行任务。 如果不是,则新创建一个线程执行刚提交的任务,否则,核心线程池中所有的线程都在执行任务,则进入(2)
(2)判断当前阻塞队列是否已满,如果未满, 则将提交的任务放置在阻塞队列中;否则,则进入(3)
(3)判断线程池中所有的线程是否都在执行任务, 如果没有,则创建一个新的线程来执行任务,否则,则交给饱和策略进行处理
线程池执行逻辑
通过ThreadPoolExecutor创建线程池后,提交任务后执行过程是怎样的,下面来通过源码来看一看。execute()方法源码如下:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//如果线程池的线程个数少于corePoolSize则创建新线程执行当前任务
if (workerCountOf© < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//如果线程个数大于corePoolSize或者创建线程失败,则将任务存放在阻塞队列workQueue中
if (isRunning© && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//如果当前任务无法放进阻塞队列中,则创建新的线程来执行任务
else if (!addWorker(command, false))
reject(command); }
execute()执行过程:
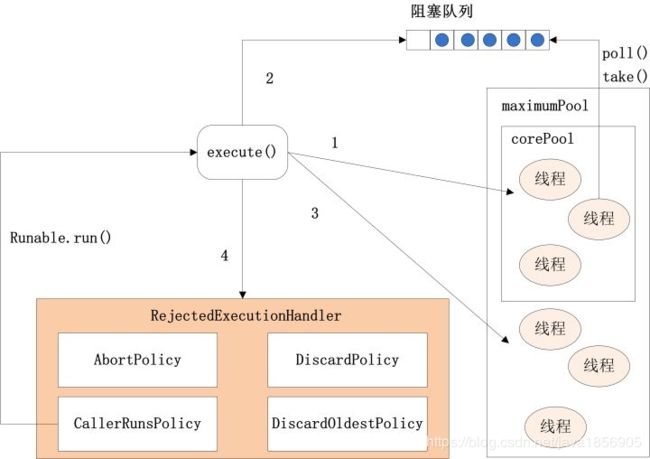
execute方法执行逻辑有这样几种情况:
(1)如果当前运行的线程少于corePoolSize,则会创建新的线程来执行新的任务,即使线程池中的其他线程是空闲的;
(2)如果运行的线程个数等于或者大于corePoolSize且小于maximumPoolSize,则会将提交的任务存放到阻塞队列workQueue中;
(3)如果当前workQueue队列已满的话,则会创建新的线程来执行任务;
(4)如果线程个数已经超过了maximumPoolSize,则会使用饱和策略RejectedExecutionHandler来进行处理增量的任务。
线程池的关闭
关闭线程池,可以通过shutdown和shutdownNow这两个方法。 它们的原理都是遍历线程池中所有的线程,然后依次中断线程。 shutdown和shutdownNow还是有不一样的地方:
shutdownNow首先将线程池的状态设置为STOP,然后尝试停止所有的正在执行和未执行任务的线程,并返回等待执行任务的列表
shutdown只是将线程池的状态设置为SHUTDOWN状态,然后中断所有没有正在执行任务的线程
可以看出shutdown方法会将正在执行的任务继续执行完,而shutdownNow会直接中断正在执行的任务。 调用了这两个方法的任意一个,isShutdown方法都会返回true, 当所有的线程都关闭成功,才表示线程池成功关闭,这时调用isTerminated方法才会返回true。
如何合理配置线程池参数
要想合理的配置线程池,就必须首先分析任务特性,可以从以下几个角度来进行分析:
任务的性质:CPU密集型任务,IO密集型任务和混合型任务。
任务的优先级:高,中和低。
任务的执行时间:长,中和短。
任务的依赖性:是否依赖其他系统资源,如数据库连接。
CPU密集型任务配置尽可能少的线程数量,如配置(N cpu)+1个线程的线程池。
IO密集型任务则由于需要等待IO操作,线程并不是一直在执行任务,则配置尽可能多的线程,如2 * (N cpu)。
混合型的任务,如果可以拆分,则将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐率要高于串行执行的吞吐率,如果这两个任务执行时间相差太大,则没必要进行分解。
我们可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。
优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。它可以让优先级高的任务先得到执行,需要注意的是如果一直有优先级高的任务提交到队列里,那么优先级低的任务可能永远不能执行。
执行时间不同的任务可以交给不同规模的线程池来处理,或者也可以使用优先级队列,让执行时间短的任务先执行。
依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,如果等待的时间越长CPU空闲时间就越长,那么线程数应该设置越大,这样才能更好的利用CPU。
阻塞队列最好是使用有界队列,如果采用无界队列的话,一旦任务积压在阻塞队列中的话就会占用过多的内存资源,甚至会使得系统崩溃。
ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor继承了ThreadPoolExecutor类, 因此,整体上功能一致,线程池主要负责创建线程(Worker类), 线程从阻塞队列中不断获取新的异步任务,直到阻塞队列中已经没有了异步任务为止。 但是相较于ThreadPoolExecutor来说,ScheduledThreadPoolExecutor 具有延时执行任务和周期性执行任务的特性, ScheduledThreadPoolExecutor重新设计了任务类ScheduleFutureTask, ScheduleFutureTask重写了run方法使其具有可延时执行和可周期性执行任务的特性。 另外,阻塞队列DelayedWorkQueue是可根据优先级排序的队列,采用了堆的底层数据结构, 使得与当前时间相比,将待执行时间越靠近的任务放置到队头,以便线程能够获取到任务进行执行
线程池无论是ThreadPoolExecutor还是ScheduledThreadPoolExecutor, 在设计时的三个关键要素是:任务、执行者以及任务结果。 它们的设计思想也是完全将这三个关键要素进行了解耦。
执行者
任务的执行机制,完全交由Worker类,也就是进一步了封装了Thread。 向线程池提交任务,无论为ThreadPoolExecutor的execute方法和submit方法, 还是ScheduledThreadPoolExecutor的schedule方法,都是先将任务移入到阻塞队列中, 然后通过addWork方法新建了Work类,并通过runWorker方法启动线程,并 不断的从阻塞对列中获取异步任务执行交给Worker执行,直至阻塞队列中无法取到任务为止。
任务
在ThreadPoolExecutor和ScheduledThreadPoolExecutor中任务是指实现了Runnable接口和Callable接口的实现类。 ThreadPoolExecutor中会将任务转换成FutureTask类, 而在ScheduledThreadPoolExecutor中为了实现可延时执行任务和周期性执行任务的特性, 任务会被转换成ScheduledFutureTask类,该类继承了FutureTask,并重写了run方法。
任务结果
在ThreadPoolExecutor中提交任务后,获取任务结果可以通过Future接口的类, 在ThreadPoolExecutor中实际上为FutureTask类, 而在ScheduledThreadPoolExecutor中则是ScheduledFutureTask类
线程池的状态
线程池的状态有:
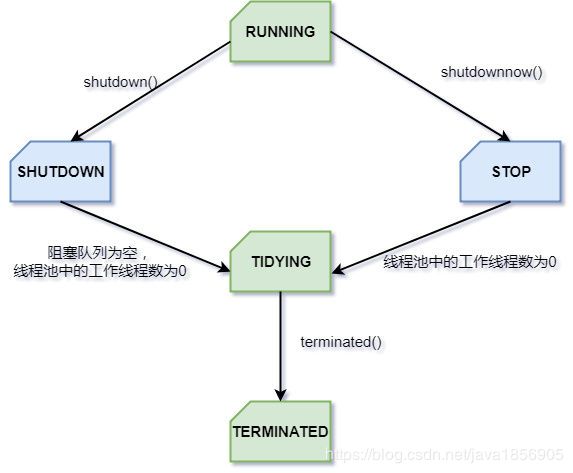
RUNNING:能接受新提交的任务,并且也能够处理阻塞队列中的任务;
SHUTDOWN:不再接受新提交的任务,但是可以处理存量任务(即阻塞队列中的任务);
STOP:不再接受新提交的任务,也不处理存量任务;
TIDYING:所有任务都已终止;
TERMINATED:默认是什么也不做的,只是作为一个标识。
状态转移如下图所示:
工作线程的生命周期:
