二、 Hive语法树的生成
HiveQL是一个非标准的sql语言,实现了sql的大部分规范,同时添加了一些hive独有的特性。Hive使用antlr3定义HiveQL语言。
1.1 antlr3简介
ANTLR(ANother Tool for Language Recognition)是一款功能强大的语言构建工具,提供了词法分析、语法分析等功能。用户编写语言的词法规则和语法规则,然后通过antlr提供的运行时库将语言转换成抽象语法树。antlr支持java、c、c++、Python等多种语言。Antlr3是antlr的第三版,采用了自顶向下的语法分析方法LL(k),支持语法树重写,import、语法预测等功能。
1.2 antlr3语法规则
使用antlr3定义一种语言需要先通过antlr3定义语言的词法规则和语法规则,然后通过antlr3的工具转换成目标语言的词法分析器和语法分析器代码。如Hive词法规则HiveLexer.g文件和语法规则HiveParser.g文件会被antlr3生成目标语言java对应的HiveLexer.java和HiveParser.java文件。HiveLexer.java是Hive的词法分析器,HiveParser.java则是语法分析器。HiveQL语言经过HiveLexer和HiveParser的分析处理生成抽象语法树AST.
1.2.1语法规则
如下为antrl3定义词法和语法的规则:
grammar-type grammar name;
options { name1 = value; name2 = value2; ... }
import grammar1,grammar2…..;
tokens { token-name1; token-name2 = value; ... }
@header { ... }
@lexer::header { ... }
@members { ... }
«rules»grammar-type为语法类型,常用的包括lexer和parser,lexer是语言的词法规则,parser是语法规则。
options定义了一些可选参数,如下表所示:
| 名称 |
描述 |
| language |
目标语言,默认是java |
| tokenVocab |
指定词法分析器 |
| output |
输出类型,包含AST和template,Hive使用AST. |
| ASTLabelType |
AST节点类型,java默认为CommonTree |
| k |
LL(k)参数,LL分析中提前读取单词个数 |
import为导入的其他语法和词法文件。
tokes包含了所以语法树节点名称。
header包含java的import信息。
memers:antlr3可以在语法规则文件中嵌入目标语言的代码,如java代码等。memers可以定义该语法规则文件的类变量和方法。
rules:定义了语言的词法规则和语法规则。规则的一般格式为:
rule-name:rule1 | rule2…;
rule-name为规则名称,如果是词法规则,rule-name首字母必须大写,语法规则小写。每个规则后面可以包含多条规则,例如:
Letter: ‘a’…’z’ | ‘A’..’Z’; //定义字母
booleanValue: KW_TRUE | KW_FALSE;//定义布尔变量的值
1.2.2 AST生成
antlr3支持两种方式生成抽象语法树(AST):运算符和规则重写.
1) 运算符
语法规则中所有的节点(子规则或者常量)默认作为AST的子节点。可以使用”!”将节点排除语法树外;使用”^”可以将节点设置为语法树的根节点。如:
N : [0-9];
e : e’+‘e | ‘(‘! e !‘)’!;给定输入1+1,生成语法树为:

输入(1)生成的语法树则为:
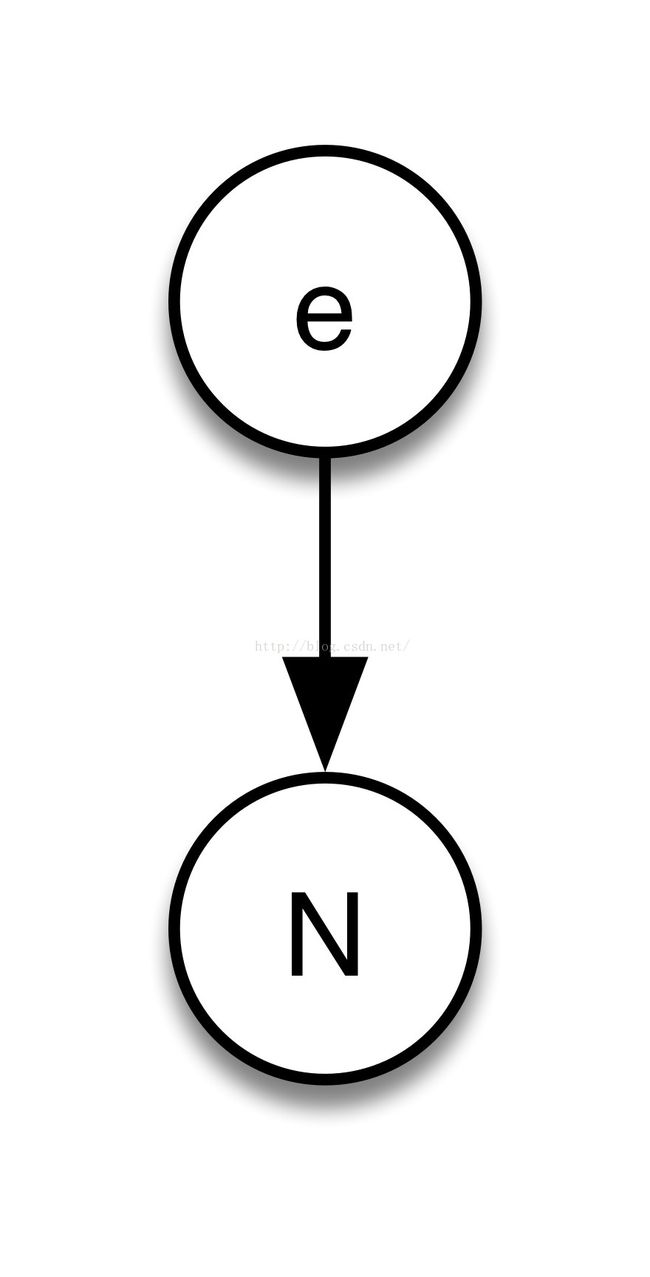
可见,左右两边的括弧被排除出AST了。
2)规则重写
antlr3可以在语法规则中使用”->”符号指定生成的语法树,称之为规则重写,如:
INT:[0-9]+
add: a=INT ‘+’ b=INT -> ^(ADD $a $b) 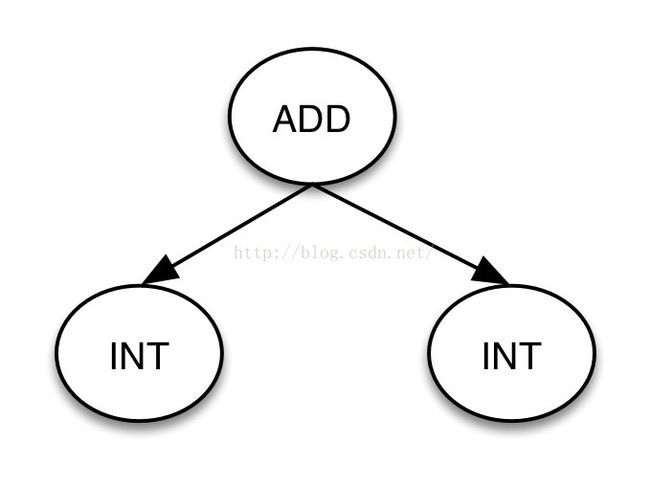
关于antlr3的详细使用请参考官方文档http://www.antlr3.org/
1.3 Hive语法树
Hive的词法规则和语法规则文件定义在Hive源码ql工程org/apache/hadoop/hive/ql/parse目录下,主要文件及功能说明如下表所示:
| 文件名 |
功能 |
| HiveLexer.g |
HiveQL词法规则 |
| IdentifiersParser.g |
定义HiveQL的常量、运算表达式、groupBy表达式,函数等语法规则。 |
| SelectClauseParser.g |
定义HiveQL的select语法规则。 |
| FromClauseParser.g
|
定义HiveQL的from语法规则,包括子sql和join的语法规则。 |
| HiveParser.g
|
定义HiveQL语法的总规则,包含其他规则。 |
HiveLexer.g文件比较简单,主要定义了Hive的关键词以及字符串、数字等的词法规则。部分规则如下:
KW_SELECT : 'SELECT';
KW_DISTINCT : 'DISTINCT';
KW_INSERT : 'INSERT';
KW_OVERWRITE :'OVERWRITE';
StringLiteral:
( '\'' ( ~('\''|'\\') | ('\\' .) )* '\''
| '\"' ( ~('\"'|'\\') | ('\\' .) )* '\"'
)+
;1.3.1 查询语句语法树
一条查询语句由以下几个部分组成:
1) select语句:表示关系代数中的投影运算。最简单的HiveQL语句可以只包含select语句,如select 1,2。
2) from语句:描述了查询的数据源,数据源主要包括表、子查询语句、join运算、集合运算等。
3) body语句:查询语句的主体部分,包括group by,distribute by,order by,sort by,limit,having,where,clusterby等。
下面首先介绍查询语句语法树整体结构,然后分别介绍select语句、from语句和body语句的语法树结构。
1.3.1.1 查询语句语法树结构
查询语句语法规则定义如下:
queryStatementExpression:queryStatementExpressionBody;
queryStatementExpressionBody:fromStatement | regularBodyqueryStatementExpression为select语句语法规则的起始规则,由queryStatementExpressionBody规则构成,该规则包含两种类型:fromStatement规则和regularBody规则。其中前者代表from在select语句前面的语句格式:
from 语句 select 语句 body语句
后者代表了from在select语句后面的语句格式:
select 语句 from 语句 body语句以regularBody类型(from在select语句后面)为例进行分析:

regularBody规则包含selectStatement规则,selectStatement规则包含select语句,from语句和body语句。通过规则重写生成的语法树结构如下:

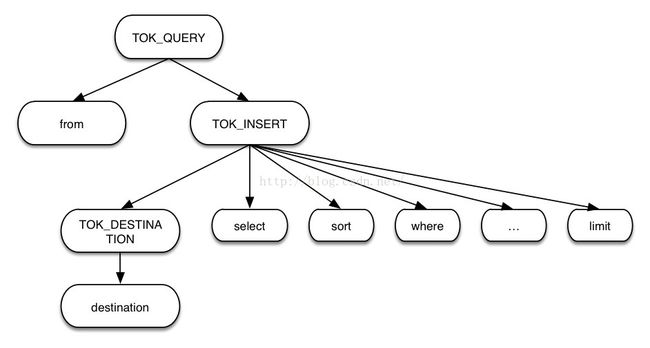
查询语句语法树结构
查询语句语法树由两部分组成:from和insert(TOK_INSERT为根节点的语法树)。其中from代表了from语句的语法树,为查询语句的数据源;insert是查询语句的主体部分,包括select语句语法树body语句语法树(sort,where,limit等)以及目的数据源TOK_DESTINATION。查询语句的目的数据源为临时目录,即Hive会将查询结果存放在临时文件中。这棵树给出了查询语句AST的整体结构,所有的查询语句都会换成这样一棵树,不同的只是from结构和body结构。
我们注意到,selectStatement语法规则中包含setOpSelectStatement规则,该规则定义了HiveQL语句的集合运算,如union all,union distinct,except(Hive1.x版本只支持union )等,以union all为例, setOpSelectStatement规则定义如下所示(为了叙述方便,省略了部分代码)。
setOpSelectStatement规则包含一个参数CommonTree t,由父规则selectStatement传入(见selectStatement的规则),表示union左边的HiveQL语句的语法树;规则中有一个闭包,由集合运算符和simpleSelectStatement组成(simpleSelectStatement是一个不包含集合运算,orderby,distribute by,cluster by,sort by语句的简单HiveQL语句)。规则中{表达式}?表示语法预测,相当于if语句的功能。当setOpSelectStatement为null时(+闭包第一次迭代时,setOpSelectStatement为null),生成的语法树左节点为CommonTree t,右节点为simpleSelectStatement;当setOpSelectStatement当前的语法树不为null,且为集合运算符为union all时,输出的语法树根节点是TOK_UNIONALL,左子节点为setOpSelectStatement在闭包迭代中已经生成的语法树,右子节点为simpleSelectStatement。
可见,HiveQL语句中只有一个union all运算符号时,语法树左右节点分别为运算两边的HiveQL语句对应的语法树;当包含多个union all运算符时,语法树左子节点是一个嵌套的union语法树,右子节点为最后一个HiveQL子查询语句的语法树。闭包之后,集合运算语句还包含body语句,最后通过规则重写生成的语法树结构如下图:

其中union表示闭包部分的语法树,如下图:

前面介绍了查询语句语法树的整体结构,下面分别介绍select语句、from语句以及body语句各个部分的语法树结构。
1.3.1.2 select语句语法树结构
select语句的语法定义在SelectClauseParser.g中,select语句除了可以包含表达式以外,还可以包含优化提示(如/+*MAPJON(a)*/)以及脚本。
对于不包含脚本的select语句,语法树分两种情况:
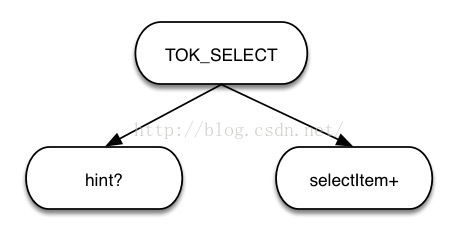
a) 对于select distinct [表达式列表] 的情况,语法树如下图所示。
TOK_SEECTDI节点表示这是一句包含distinct的语句,hint 表示优化提示语句,selectItem表示select类型,包括表达式和*。

HiveQL中表达式的语法树是一棵左型树,比如:a>2 and b>3 or c<4的语法树如下:
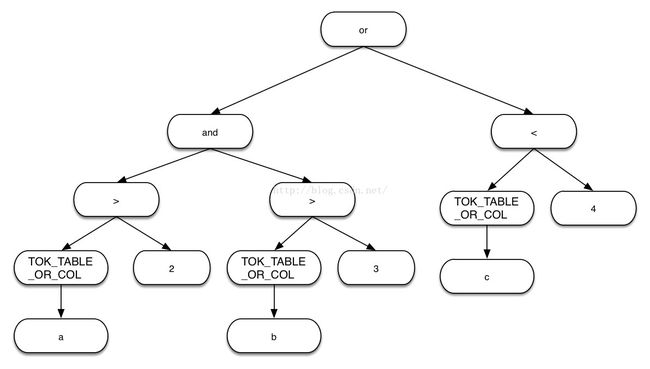
Hive在算子生成阶段,会将select distinct语句转换成select group by语句,如select distinct a会转换成select a group by a。
b)对于select [表达式列表] 的情况,语法树如下:
c) 对于select中包含脚本的情况,语法树如下:
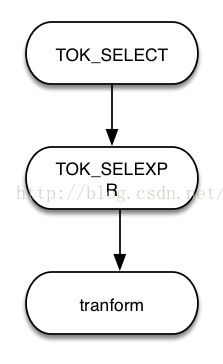
tranform为脚本语句的语法树。
1.3.1.3 from语句
前面已经介绍过,from语句描述了查询的数据来源。from语句语法树结构如下:

from_src为数据来源的语法树,HiveQL中查询语句的数据来源包括以下几类:
1) 表
数据来自数据库中的一张表,其 from语法树一般形式如下所示。

表from_src语法树结构
2) subquery
数据来自另外一个查询语句,语法树形式如下所示。
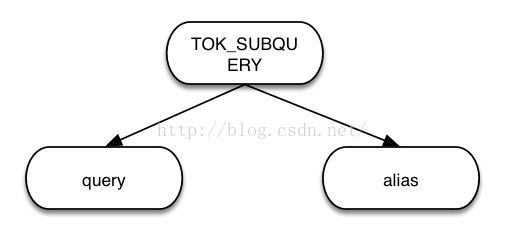
sbuquery from_src语法树结构
3) join运算
HiveQL支持inner join、cross join、left outer join、right outer join、full outer join以及left semi join等join类型。join运算的语法树结构如下:

from join语法树
joinToken表示join类型,该节点包含两个from_src语法树,其中左边标记为红色的from_src语法树可以嵌套包含另外一个joinToken树;expr表达joinon后面的表达式。可见,join语法树是一棵左型树。
其他数据来源还包括虚拟表格,lateralview以及分表函数,这里不一一展开。
1.3.1.4 body语句
body语句包括where,limit,sortby,group by等语句,下面介绍部分body语句的语法树结构。
1) where
where语句的语法定义在FromClauseParser.g中,语法树如下:

2) group by
group by语法定义在IdentifiersParser.g文件中,语法树如下:

expr为group by后面的表达式,+表示group by后可以有多个表达式。
HiveQL支持GROUPINGSETS clause功能,允许将一条group by语句按照分组转换成多条group by语句的union运算。例如下表转换关系:
表2-1 GROUPING SETS等价的HiveQL语句
| GROUPING SETS语句 |
等价的HiveQL语句 |
| SELECT a, b, SUM(c) FROM tab1 GROUP BY a, b GROUPING SETS ( (a,b) ) |
SELECT a, b, SUM(c) FROM tab1 GROUP BY a, b |
| SELECT a, b, SUM( c ) FROM tab1 GROUP BY a, b GROUPING SETS ( (a,b), a) |
SELECT a, b, SUM( c ) FROM tab1 GROUP BY a, b UNION SELECT a, null, SUM( c ) FROM tab1 GROUP BY a
|
| SELECT a,b, SUM( c ) FROM tab1 GROUP BY a, b GROUPING SETS (a,b)
|
SELECT a, null, SUM( c ) FROM tab1 GROUP BY a UNION SELECT null, b, SUM( c ) FROM tab1 GROUP BY b
|
GROUPING SETS的语法树如下:

GROUPINGSETS语法树
expr为group by表达式,groupingSetExpr为分组表达式。
HiveQL同时还支持cubegroup by和rollup group by,其中cubegroup by是对所有group by表达式的排列组合进行GROUPINGSETS分组,例如:
GROUP BY a,b WITH CUB等价于GROUP BY a,b GROUPING SETS((a,b),(a),(b),());rollup group by则是从层次角度做聚合运算,例如:GROUP BY a,b,c WITH ROLLUP等价于GROUP BY a,b,cGROUPING SETS((a,b,c),(a,b),(a,c),()).Cube Group和RollupGroup对应的语法树分别如下:
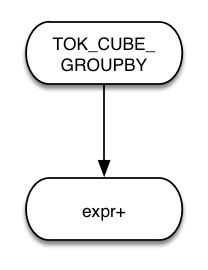
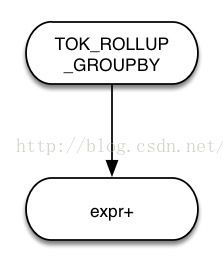
cube groupby rollup groupby
1.3.2 insert语句语法树
HiveQL支持单insert语句以及多insert语句。
1) 单insert语句的语法树
Hive的insert语句分为insert into和insert overwrite两种类型,例如:
from table a insert into tablec select a.*;
from table a insert overwrite table c select a.*;insert into表示在目标表上插入数据,insertoverite则会覆盖原有数据。
下面分别给出这两种类型的查询语句的语法树:

insert into语法树
insert into语句语法树结构和查询语法树类似,都包含两部分组成:from和insert(TOK_INSERT为根节点的语法树)。只是将TOK_DESTINATION替换成TOK_INSERT_IN。TOTOK_INSERT_INTO表示数据插入的目标,为table_dest和table_cols(可选),table_dest代表一张表,table_cols为表的字段列表,如果不指定table_cols,默认为表的所有字段。
insert overwrite语法树
insertoverite语法树结构也和查询语法树相似,由from和insert两部分组成。不同之处在于数据存储的目的地不同,查询语数据存储在临时文件(TOK_TMP_FILE)中,而insert overwrite语句的目的地是destination,包括table_dest(表)和tok_dir(文件目录)两类。
2)多insert语句的语法树
多insert语句可以将同一个数据源(from语句)的数据insert到多个目标数据源,例如:
from a
insert overwrite table b select * where id<100
insert overwrite table c select * where id<200
insert into table d select * where id<300将表a中的数据分别输出到b,c,d中。
多insert语句的语法树结构和上面介绍的单insert语句语法树类似,不同之处在于会包括多个insert,语法树如下:

insert为对应insert分支的insert语法树。单个Insert语句可以看成是insert为1时的特殊情况。
1.2.3 总结
查询语句和insert语句是HiveQL的核心语句,了解其语法树结构对后面分析Hive逻辑算子生成有重要作用。通过前面的分析,可以发现查询语句和insert语句语法结构相似,查询语句和insert语句语法树都具有相同的根节点TOK_QUERY,且都包括from数据源和insert两部分,insert部分有目的数据源、select和body部分组成。语法结构如下图所示:

HiveQL 查询和insert语句语法树整体结构
查询语句和insert语句语法树不同之处在于目的数据源的不同,具体见下表:
| 语句类型 |
目的数据源 |
目的数据写方式 |
| 查询 |
临时文件,语法树节点TOK_TEMP_FILE |
覆盖写如,语法树节点为TOK_DESTINATION |
| Insert overwrite |
包括表和文件两种类型。 |
同上 |
| Insert into |
表,还可以指定表的字段名列表。 |
增量添加。语法树节点为TOK_INSERT_INTO |