Caffe入门实例:mnist手写数字识别训练和自己手写数字的识别
第一部分:准备数据和测试网络
MNIST(Mixed National Institute of Standards and Technology)是一个大型手写体数字识别数据库,广泛应用与机器学习领域的训练和测试。MNIST包括60000个训练集和10000个测试集,每张图都已经进行尺寸归一化、数据居中处理,固定大小为28×28像素。这里写图片描述,下载数据集

一、下载数据集
使用Caffe源码目录中data/mnist下用get_mnist.sh脚本下载。
$ cd data/mnist/
$ ./get_mnist.sh
数据集可以直接从github下载,包括数据集和代码,使用如下指令:
git clone https://github.com/Jack-Cherish/DeepLearning/tree/master/mnist
如果github网速过慢,也可以从百度云下载:
链接: https://pan.baidu.com/s/1_FarKhi9herjAYPdHIWZsg 密码: 2cme
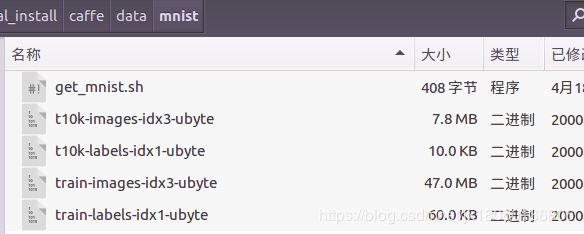
下载成功后在data/mnist 目录下多出四个文件
文件名 说明
train-images-idx3-ubyte 训练集,图片
train-labels-idx1-ubyte 训练集,标签
t10k-images-idx3-ubyte 测试集,图片
t10k-labels-idx1-ubyte 测试集,标签
二、转换格式
下载到的数据集为二进制文件,需要转换为LMDB或LEVELDB才能被Caffe识别。
$ ./examples/mnist/create_mnist.sh
Creating lmdb...
Done.
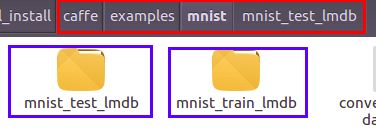
在examples/mnist目录下生成了mnist_train_lmdb/ 和mnist_test_lmdb/ 两个目录,每个目录下都有两个文件:data.mdb和lock.mdb。
顾名思义,mnist_train_lmdb是LMDB格式的训练集,mnist_test_lmdb是LMDB格式的测试集。
三、训练网络
目前系统还不支持GPU运行,修要将训练网络改成CPU模式。将examples/mnist/lenet_solver.prototxt最后一行修改如下
# solver mode: CPU or GPU
solver_mode: CPU
运行examples/mnist/train_lenet.sh脚本
$ ./examples/mnist/train_lenet.sh
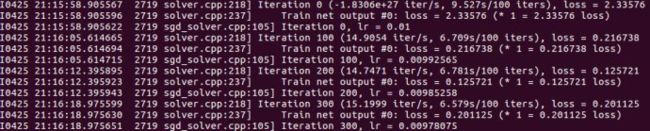
由于没有使用GPU加速,训练时间可能较长。数据输出最后几行如下
I1108 00:22:17.995280 8674 solver.cpp:454] Snapshotting to binary proto file examples/mnist/lenet_iter_10000.caffemodel
// 保存训练好的权值文件
I1108 00:22:18.007494 8674 sgd_solver.cpp:273] Snapshotting solver state to binary proto file examples/mnist/lenet_iter_10000.solverstate
// 保存训练状态
I1108 00:22:18.075494 8674 solver.cpp:317] Iteration 10000, loss = 0.00255292
I1108 00:22:18.075568 8674 solver.cpp:337] Iteration 10000, Testing net (#0)
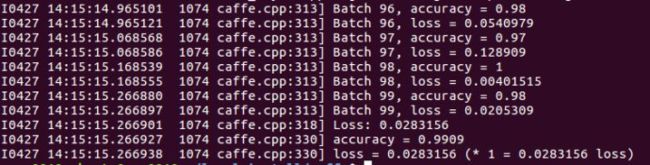
I1108 00:22:25.076969 8674 solver.cpp:404] Test net output #0: accuracy = 0.9908
// 最终分类准确率为 99.08%
I1108 00:22:25.077057 8674 solver.cpp:404] Test net output #1: loss = 0.0278366 (* 1 = 0.0278366 loss)
// 最终loss值为 0.0278366
I1108 00:22:25.077070 8674 solver.cpp:322] Optimization Done.
I1108 00:22:25.077077 8674 caffe.cpp:254] Optimization Done.

训练的最终结果保存在examples/mnist/lenet_iter_10000.caffemodel中。
测试训练好的模型
四、使用MNIST测试集对训练好的模型进行测试
$ ./build/tools/caffe.bin test -model examples/mnist/lenet_train_test.prototxt -weights examples/mnist/lenet_iter_10000.caffemodel -iterations 100
命令行参数:
test 表示只做预测
-model examples/mnist/lenet_train_test.prototxt 指定模型描述文件
-weights examples/mnist/lenet_iter_10000.caffemodel 指定训练好的权值文件
iterations 100 指定测试迭代次数,每次迭代的数据量在模型描述文件中设定batch_size: 100,迭代100次刚好覆盖测试集的10000个样本。
第二部分:测试单个手写数字
思路梳理
手写数字图片必须满足以下条件:
(1)必须是256位黑白色
(2)必须是黑底白字
(3)像素大小必须是28x28
(4)数字在中间,上下左右没有过多空白
利用模型lenet_iter_10000.caffemodel测试单张手写体数字所需要的文件:
(1)待测试图片(自己画的也行,网络上下的也行);需要注意的是,不管是什么格式,都要转换为28*28大小的黑白灰度图像,具体转化方法请自行百度,不想转化的我这里提供给大家一组我转化好的图片资源供大家下载链接: https://pan.baidu.com/s/1boGHQzl 密码: qfd6
(2)deploy.prototxt(模型描述型文件);
(3)network.caffemodel(模型权值文件),在本例中就是lenet_iter_10000.caffemodel
(4)labels.txt(标签文件);
(5)mean.binaryproto(二进制图像均值文件);
(6)classification.bin(二进制程序名)。与二进制均值文件配合使用,只是均值文件不同的模型有不同的均值文件,而这个bin文件为通用的,就是任何模型都可以做分类使用。
所需文件生成
生成deploy.prototxt文件
deploy.prototxt文件和lenet_train_test.prototxt文件类似,或者说对后者改动可得到前者。在examples/mnist目录下复制一份lenet_train_test.prototxt修改并保存后得到deploy.prototxt如下:
name: "LeNet"
layer {
name:"data"
type: "Input"
top: "data"
input_param { shape: { dim: 1 dim: 1 dim: 28 dim: 28 } }
}
layer {
name:"conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name:"pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name:"conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
convolution_param {
num_output: 50
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name:"pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name:"ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
}
}
layer {
name:"relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
layer {
name:"ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
}
}
layer {
name:"prob"
type: "Softmax"
bottom: "ip2"
top: "prob"
}
生成labels.txt标签文件
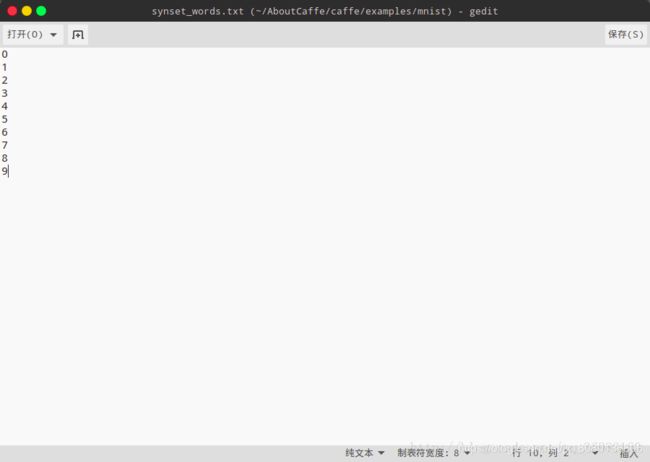
在当前目录下新建一个txt文件,命名为synset_words.txt,里面内容为我们训练mnist的图片内容,共有0~9十个数,那么我们就建立如下内容的标签文件:
生成mean.binaryproto二进制均值文件
caffe作者为我们提供了一个计算均值的文件compute_image_mean.cpp,放在caffe根目录下的tools文件夹里面,运行下面命令生成mean.binaryproto二进制均值文件:
生成的mean.binaryproto均值文件保存在了examples/mnist目录下。
分类器classification.bin
在example文件夹中有一个cpp_classification的文件夹,打开它,有一个名为classification的cpp文件,这就是caffe提供给我们的调用分类网络进行前向计算,得到分类结果的接口。
开始测试
在caffe根目录下命令:
./build/examples/cpp_classification/classification.bin examples/mnist/deploy.prototxt examples/mnist/lenet_iter_10000.caffemodel examples/mnist/mean.binaryproto examples/mnist/synset_words.txt examples/images/3.jpg 