LDA Gibbs Sampling公式推导
Gibbs Sampling
Background
所有的推导可以说都是根据这张图片:
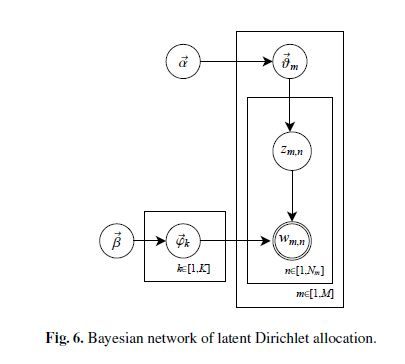
α∈RM×K
θm∈RK
β∈RK×V
ϕk∈RV
LDA的目的就是为了在给定 α,β 的情况下,求出 θ 和 ϕ 。
推导1 — 联合分布
求解 p(s,z|α,β)=p(w|z,β)⋅p(z|α)
两个部分 p(w|z,β) , p(z|α) 分别考虑。
对于第一部分: p(w|z,β)=∫p(x|z,ϕ)⋅p(ϕ|β)dϕ
- p(x|z,ϕ)=∑Kk=1p(w|zk,ϕk)=∑Kk=1∏Vv=1p(w|zk,ϕk,v)=ϕntkk,v ,其中 ntk 表示的是所有文档中属于topic k的词v的个数。
- p(ϕk|β)=Dir(ϕk|β)=1B(β)∏Vv=1ϕβv−1k,v
所以 p(w|z,β)=∫∏Kk=1∏Vv=1ϕnvk,v⋅∏Kk=11B(β)∏Vv=1ϕβv−1k,vdϕk,v=∏Kk=11B(β)∫∏Vv=1ϕnvk+βk−1k,vdϕk,v
而又有因为 ∫∏Kk=1pαk−1kdpk=B(α)
能得到 p(w|z,β)=∏Kk=1B(nk+β)B(β) ,其中 nk=[n1k,n2k,...,nVk] ,表示所有文档中,属于topic k的词v的个数。
同理,对于第二部分 p(z|α)
p(z|α)=∫p(z|θ)⋅p(θ|α)dθ=∏Mm=11B(α)∫∏Kk=1θnkm+α-1m,k)=∏Mm=1B(nm+α)B(α) ,其中 nm=[n1m,n2m,...,nKm] , nkm 表示第m个文档中属于第k个主题的词的个数。
所以综上 p(w,z|α,β)=∏Kk=1B(nk+β)B(β)⋅∏Mm=1B(nm+α)B(α)
推导2 — 条件分布
求解: p(zi=k|z−i,w)
首先,要得到 p(zi=k|z−i,w)=p(w,z)P(w,z−i)
根据上面,有 p(w,z|α,β)=∏Kk=1B(nk+β)B(β)⋅∏Mm=1B(nm+α)B(α)
所以在固定 α 和 β 之后,可以得到 p(w,z)P(w,z−i)=∏Kk=1B(nk+β)B(β)⋅∏Mm=1B(nm+α)B(α)∏Kk=1B(nk,−i+β)B(β)⋅∏Mm=1B(nm,−i+α)B(α)=B(nk+β)B(bk,−i+β)⋅B(nm+α)B(nm,−i+α)
B(nk,−i+β)=∏Vv=1Γ(nv,−i+βv)Γ(∑v=1Vnv,−i+βv)=Γ(n1+β1)⋅Γ(n2+β2)...Γ(ni−1+βi)...Γ(nV+βV)Γ(∑Vv=1nv,−i+βv)
B(nk+β)=∏Vv=1Γ(nv+βv)Γ(∑v=1Vnv,−i+βv)=Γ(n1+β1)⋅Γ(n2+β2)...Γ(ni−1+βi)...Γ(nV+βV)Γ(∑Vv=1nv+βv)
所以 B(nk+β)B(nk,−i+β)=Γ(ni+βi)Γ(ni−1+βi)⋅Γ(∑Vv=1nv,−i+βv)Γ(∑Vv=1nv+βv)
又因为 Γ(x+1)=x⋅Γ(x)
所以能够化简为 B(nk+β)B(nk,−i+β)=ni−1+βi∑Vv=1(nv,−i)+βv
同理 B(nm+α)B(nm,−i+α)=ni−1+αi∑Kk=1nk,−i+αk
所以得到 p(zi=k|z−i,w)∝ni−1+βi∑Vv=1nt,−i+Vβvnk−1+αi∑Vv=1nt,−i+Vαv
若 ∀i , βi=β,αi=α ,则得到
p(zi=k|z−i,w)∝ni−1+β∑Vv=1nt,−i+Vβnk−1+α∑Vv=1nt,−i+Vα
推导3 — 后验
根据Dirichlet和Multi-nomial的共轭性,也就是当先验是Dirichlet,likelihood是Multi-nomial,那么后验也是Dirichlet。也就是先验分布 Dir(p|α) ,后验分布 Dir(p|α+x) 。使用Dirichlet分布的期望来估计Multinomial分布的参数。
E(P)=(α1∑αi,α2∑αi,...,αK∑αi)
因此,只要能够识别出对于文档中的每一个单词的隐含主题,就能够求出两个公式。
p(z|w)=p(z,w)p(w) ,而 p(w)=∏i=1n∑k=1Kp(wi|zi=k)p(zi=k) ,计算量太大,所以我们才使用了前面证明的方法,来求得 p(zi=k|z−i,w) 。
所以综合上述
θ=[θ1,θ2,...,θM]
θm,k=nm,k+α∑Kk=1nm,k+Kα
ϕ=[ϕ1,ϕ2,...,ϕK]
ϕk,w=nk,w+βw∑Vv=1nk,i+Vβ
Appendix
写完了才发现有高清无码的paperParameter estimation for text analysis
代码实现在这里:github repo
这一章节内容也是参考了另外两篇不错的博客,然后对里面的公式进行更细致的推导
博客1
博客2