大数据学习之二 搭建伪分布式和完全分布式
搭建伪分布式和完全分布式
搭建伪分布式
1.在安装的Hadoop目录下的etc/hadoop路径下,找到core-site.xml文件

2.在中写入下面的内容
代码如下,需要根据自身linux情况进行更改主机名和hadoop版本号:
<property>
<name>fs.defaultFSname>
<value>hdfs://主机名1:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/module/hadoop-2.X.X/data/tmpvalue>
property>
3.打开hdfs-site.xml,输入如下内容

代码如下,需要根据自身linux情况进行更改主机名:
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>主机名1:50090value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
4.yarn-site.xml配置
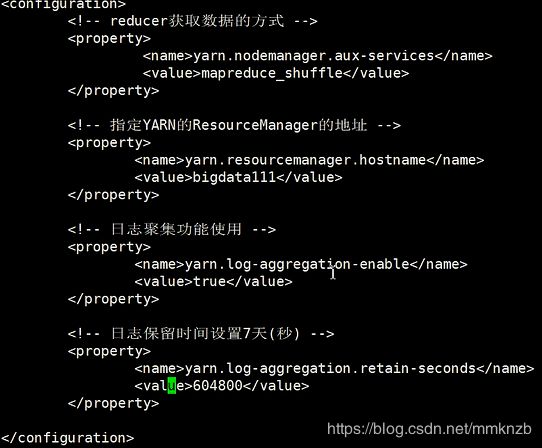
代码如下,需要根据自身linux情况进行更改主机名:
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>主机名1value>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
5.在mapred-site.xml中插入数据
代码如下,需要根据自身linux情况进行更改主机名:
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>主机名1:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>主机名1:19888value>
property>
6.在hadoop-env.sh、yarn-env.sh、mapred-env.sh中添加JAVA_HOME
例如:export JAVA_HOME=/opt/module/jdk1.8.0_144
7.在slaves文件中将localhost改为主机名
第一行是当前主机名,也是namenode所在的地方
剩下的是为了完成完全分布式所提前写入的主机名

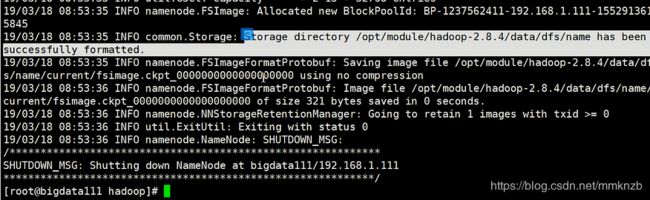
8.格式化并进行验证
执行hdfs namenode -format命令,进行格式化操作
执行后能够有如下内容就算格式化成功了
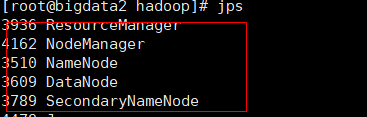
执行start-all.sh命令,启动伪分布式,如果没有设置ssh免密的话需要输入多次密码
执行jps命令,查看使用的端口号,当红框中的五个都存在即为成功
当启动时会有提示说不建议使用start-all.sh命令建议使用start-dfs.sh和start-yarn.sh
start-dfs.sh 只启动hdfs
start-yarn.sh 只启动yarn
start-all.sh启动yarn和hdfs
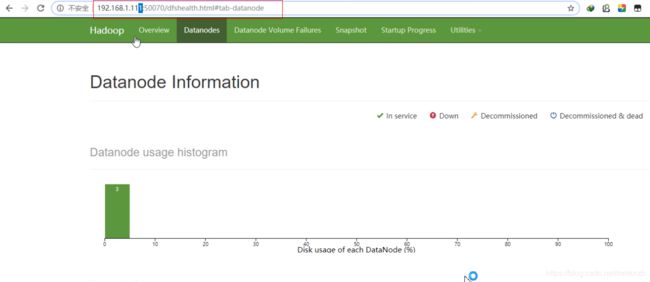
9.查看结果
在windows的浏览器上打开ip:50070的网址
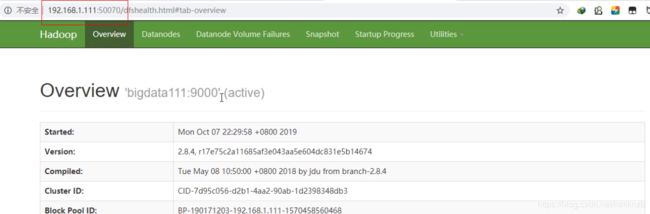
搭建完全分布式
1.将进程中除了jps的全部关闭掉,然后将虚拟机关闭
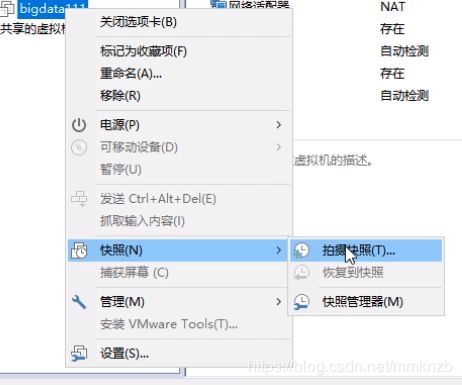
2.选中搭建好的那个虚拟机,右键快照,拍摄快照,将拍摄好的快照进行重命名为伪分布式to完全分布式(名字起什么无所谓, 只是为了方便查找)
3.然后选中虚拟机右键选择管理,克隆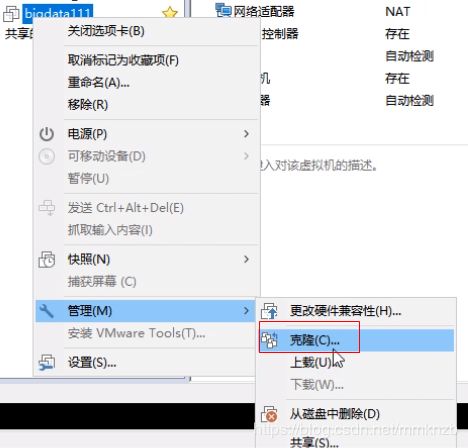
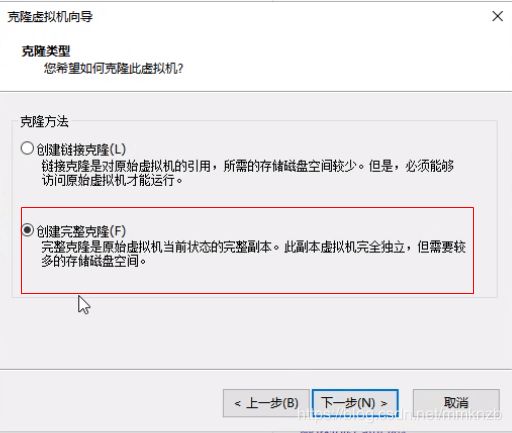
点击两次下一步,然后选择创建完整克隆
然后点击下一步,虚拟机的名称和位置进行修改,位置要跟主虚拟机在同一个父文件夹中
点击下一步
不要点击取消,等着自动蹦出克隆成功信息
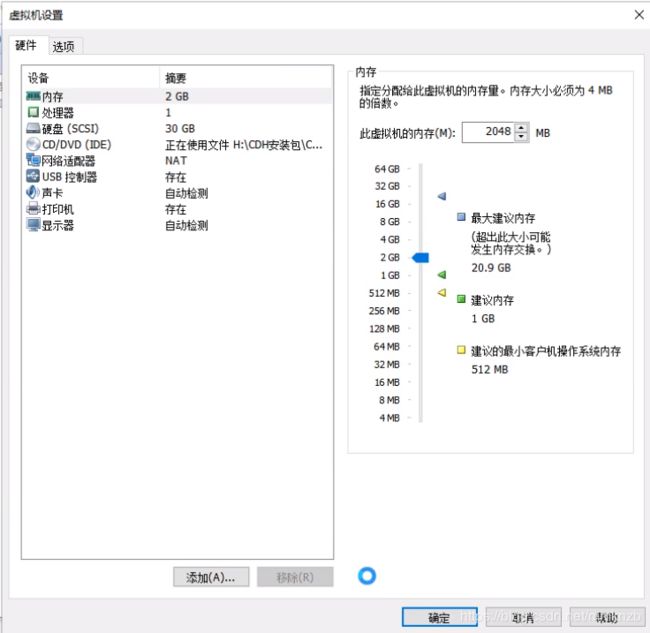
然后将克隆后的虚拟机的内存等根据电脑情况进行修改
4.点击开启克隆后的虚拟机,修改主机名和ip
点击开启克隆后的虚拟机,提示信息还是原先的主机名,一会就进行修改
这里的用户名和密码和之前的虚拟机一样
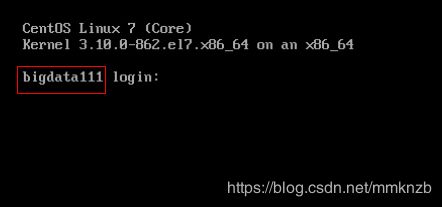
执行hostnamectl set-hostname 新的主机名命令,更改主机名
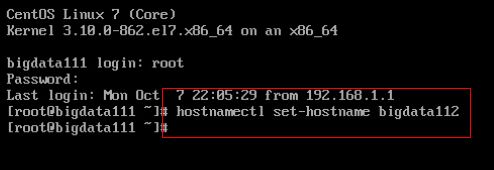
修改ip

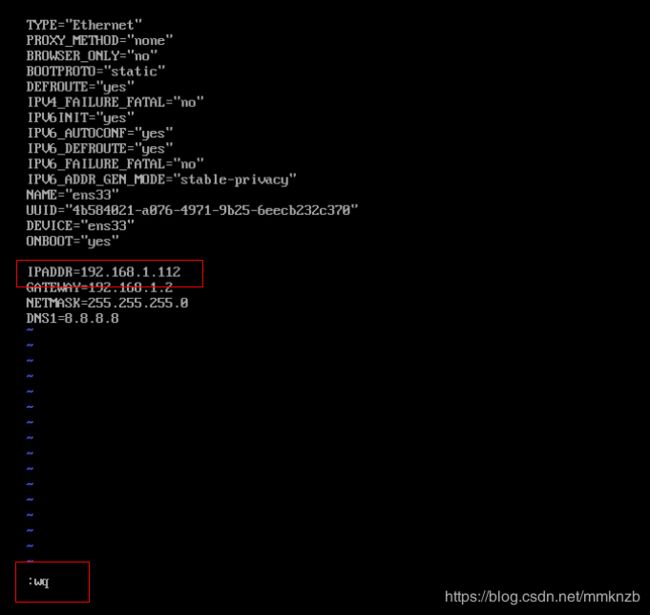
修改完毕后,执行service network restart命令进行重启,当出现ok后即为重启成功

执行ip addr命令查看ip
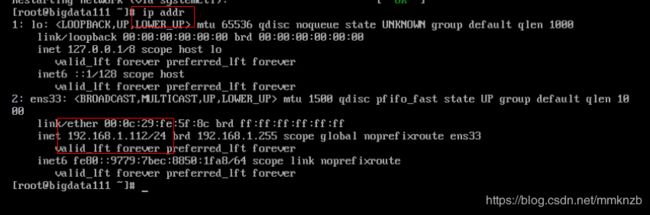
然后来ping百度和192.168.1.2看看是否可以ping通

然后就可以通过Xshell连接了,按照上面的步骤在生成第三台虚拟机
5.使用Xshell进行快速实现免密登录
通过Xshell连接后,进行分屏

然后在工具中选择发送键输入到所有会话
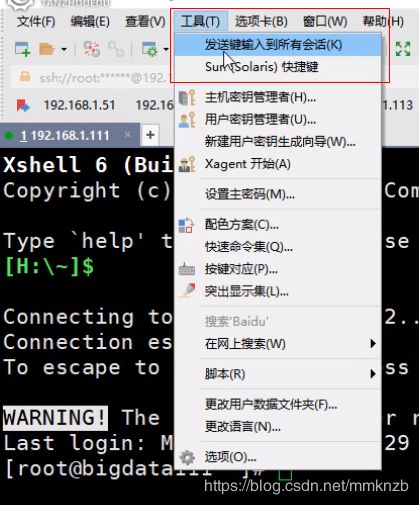
设置免密登陆
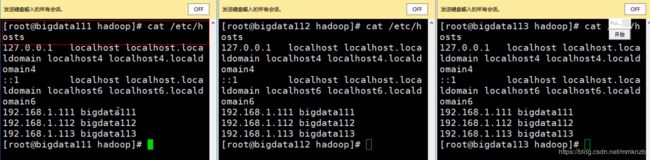
先查看**/etc/hosts**文件中是否是将三个主机名与IP的映射设置好
生成公钥和私钥:ssh-key gen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥),将公钥拷贝到要免密登录的目标机器上
多次执行ssh-copy-id命令,有几个主机执行几次
ssh-copy-id 主机名1
ssh-copy-id 主机名2
ssh-copy-id 主机名3
…
当设定完成后输入ssh 主机名命令,看看多台主机是否都能够免密登录,然后exit退出
ssh 主机名1
exit
ssh 主机名2
exit
ssh 主机名3
exit

进入到hadoop目录下

删除data和logs文件夹里的内容,注意,data和logs前面没有斜杠(/)
rm -rf data/ logs/**

然后,只在主虚拟机上进行格式化
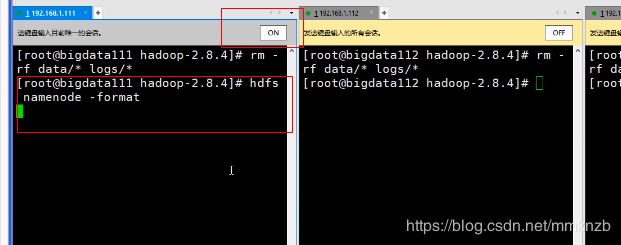
然后在主虚拟机上启动集群

然后同步所有虚拟机进行jps命令

启动项目后,到windows的浏览器上进行查看