Hadoop集群搭建---step1(虚拟机环境准备)
typora-root-url: G:\知识总结\归纳整理
Hadoop集群搭建—step1(虚拟机环境准备)
#使用iso(centos 6.9)镜像文件进行安装
三台机器规划
| IP地址 | 主机名 | |
|---|---|---|
| 第一台机器 | 192.168.52.100 | node01.hadoop.com |
| 第一台机器 | 192.168.52.110 | node02.hadoop.com |
| 第一台机器 | 192.168.52.120 | node03.hadoop.com |
通过直接复制安装后的安装文件,然后更改mac地址与ip地址也可以实现多台虚拟机的快速创建
1.修改基本配置
1.1 在VmWare上加载我们的linux操作系统
在虚拟机当中更改我们的名称为CDH1,CDH2,CDH3,并为三台虚拟机更改mac地址
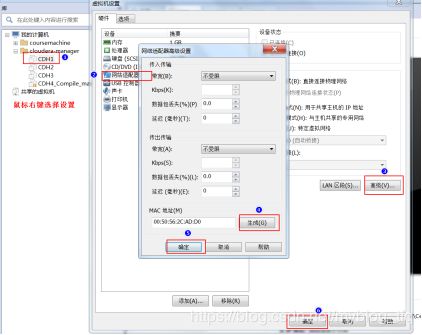
1.2 开启linux系统更改设置
#确认好VmWare生成的网关地址,另外确认VmNet8网卡已经配置好了IP地址。
更改mac地址:
vim /etc/udev/rules.d/70-persistent-net.rules
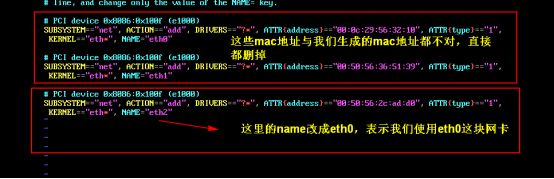
更改ip地址:
vim /etc/sysconfig/network-scripts/ifcfg-eth0
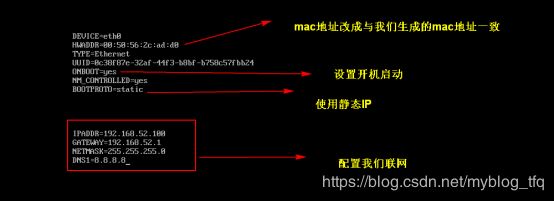
#第二台第三台机器重复上述步骤,并设置IP网址为192.168.52.110,192.168.52.120
1.3 重启linux系统
1.4 关闭防火墙
原因:集群内部的机器间多个软件需要通过端口相互通讯,如果没关闭防火墙,有些软件可能工作不了。
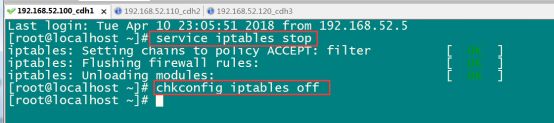
三台机器执行以下命令(root用户来执行):
service iptables stop
chkconfig iptables off
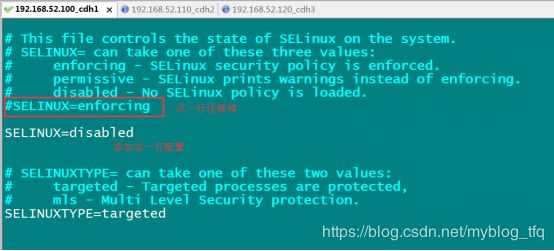
1.5 三台机器关闭selinux
原因:安全增强型 Linux简称 SELinux,它是 Linux 的一个安全子系统,SELinux 的结构及配置非常复杂,要学精难度较大。很多 Linux 系统管理员嫌麻烦都把 SELinux 关闭了。
vim /etc/selinux/config
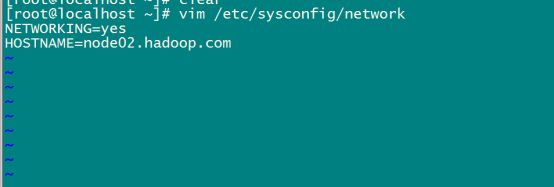
1.6 三台机器更改主机名
vim /etc/sysconfig/network
1.7 三台机器做主机名与IP地址的映射
vim /etc/hosts

1.8 三台机器重启
reboot -h now
2.三台机器机器免密码登录
原因:在搭建大数据集群时,可能需要将一个文件分发给其他的机器,这里我们用ssh的客户端命令来实现,每次分发文件都需要输入被分发文件的登录密码,为了简化这一操作,我们对其配置免密登录。
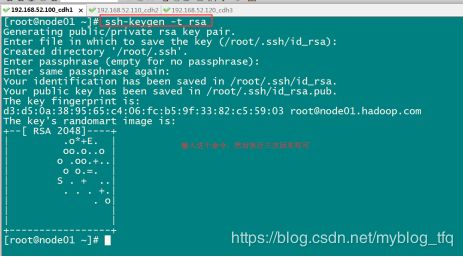
2.1 三台机器生成公钥与私钥
在三台机器执行以下命令,生成公钥与私钥:
ssh-keygen -t rsa
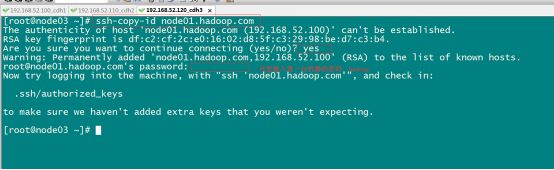
2.2 拷贝公钥到同一台机器
三台机器执行命令:
ssh-copy-id node01.hadoop.com
2.3 复制第一台机器的认证到其他机器
在第一台机器上面执行以下命令:
scp /root/.ssh/authorized_keys node02.hadoop.com:/root/.ssh
scp /root/.ssh/authorized_keys node03.hadoop.com:/root/.ssh
3.三台机器时钟同步
原因:多个机器共同提供一个服务,假设上传一个文件到集群上,A机器记录的时间是18:00,而B机器记录的时间是18:05,此时对于集群来说,文件的创建时间就存在歧义,因此,集群内部的每个机器的时间都应该同步。
方式一:通过网络进行时钟同步
1.通过网络连接外网进行时钟同步,必须保证虚拟机连上外网(手动)
ntpdate us.pool.ntp.org;
2.阿里云时钟同步服务器(手动)
ntpdate ntp4.aliyun.com
3.三台机器定时任务(修改配置文件)
crontab -e
添加一下内容:
*/1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;
方式二:通过某一台机器进行同步
以192.168.52.100这台服务器的时间为准进行时钟同步
1.确定是否安装了ntpd的服务
rpm -qa | grep ntpd
A.如果没有安装,可以进行在线安装
yum -y install ntpd
B.启动ntpd的服务
service ntpd start
C.设置ntpd的服务开机启动
chkconfig ntpd on
2.编辑/etc/ntp.conf
vim /etc/ntp.conf
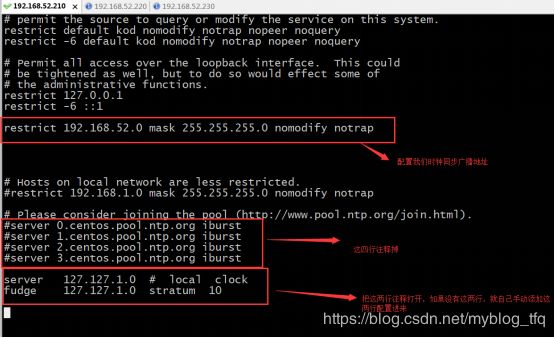
A.添加一下内容:
restrict 192.168.52.0 mask 255.255.255.0 nomodify notrap
B.注释一下四行内容:
#server 0.centos.pool.ntp.org
#server 1.centos.pool.ntp.org
#server 2.centos.pool.ntp.org
#server 3.centos.pool.ntp.org
C.去掉以下内容的注释,如果没有这两行注释,那就自己添加上:
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10
D.配置以下内容,保证BIOS与系统时间同步:
vim /etc/sysconfig/ntpd
E.添加一行内容 :
SYNC_HWLOCK=yes

3.另外两台机器与第一台机器时间同步
A.另外两台机器与192.168.52.100进行时钟同步
crontab -e
B.添加一下内容:
*/1 * * * * /usr/sbin/ntpdate 192.168.52.100
4.三台机器安装jdk
原因:Hadoop的底层实现就是Java , 所以首先必须安装Linux版的Java环境。
4.1 查看自带的openjdk
rpm -qa | grep java
4.2 卸载系统自带的openjdk
rpm -e java-1.6.0-openjdk-1.6.0.41-1.13.13.1.el6_8.x86_64 tzdata-java-2016j-1.el6.noarch java-1.7.0-openjdk-1.7.0.131-2.6.9.0.el6_8.x86_64 --nodeps
4.3 上传jdk并解压然后配置环境变量
说明:为了保持我们的安装环境统一和一致,我们这里创建两个约定俗成的文件夹,来进行我们的软件包的存放和软件的安装
A.所有软件的安装路径:
mkdir -p /export/servers
B.所有软件压缩包的存放路径:
mkdir -p /export/softwares
C.上传jdk到/export/softwares路径下去,并解压:(jdk版本为1.8.0_141)
tar -zxvf jdk-8u141-linux-x64.tar.gz -C ../servers/
D.配置环境变量:
vim /etc/profile
export JAVA_HOME=/export/servers/jdk1.8.0_141
export PATH=:$JAVA_HOME/bin:$PATH
E.修改完成之后记得 source /etc/profile生效