scrapy 爬虫框架中 ajax 异步加载 post请求方式的
scrapy 爬虫框架中 ajax 异步加载 post请求方式的处理方法:
以福建省公共资源交易电子公共服务网站为例https://www.fjggfw.gov.cn/Website/JYXXNew.aspx,爬取招标结果,打开F12控制台界面如下图所示:
Request Method:POST
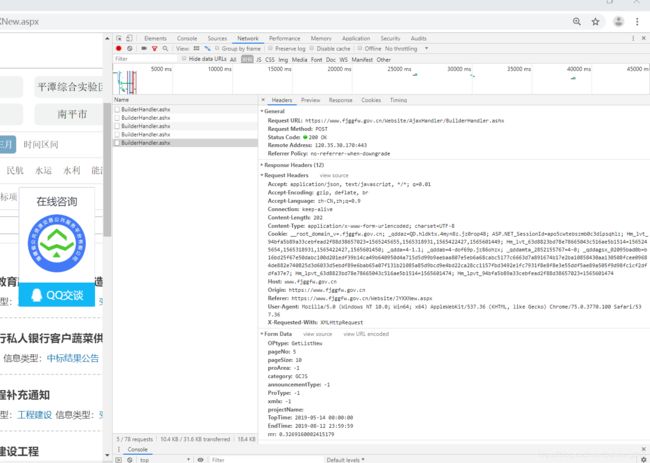
post请求方式中主要是Form Data中的信息,及每次请求Cookie信息,通过构造Cookie与param,设置scrapy.FormRequest,即可对服务器发起请求
try:
yield scrapy.FormRequest(self.base_url, formdata= params, callback=self.parse, cookies=self.Cookie, dont_filter=True)
except:
print("FormRequest报错")
pass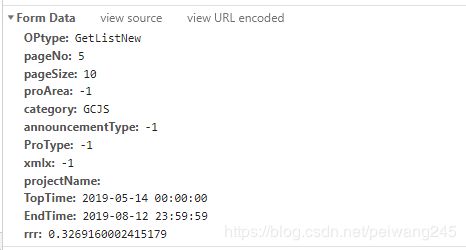
完整代码如下:
import scrapy
import sys
sys.path.append(r'C:\Users\admin\Desktop\buildingS')
from buildingS.items import BidItem
from urllib.parse import urlencode
import json
class BidSpider(scrapy.spiders.Spider):
name = "bidVfj"
allow_domains = ["fjggfw.gov.cn"]
base_url = 'https://www.fjggfw.gov.cn/Website/AjaxHandler/BuilderHandler.ashx?'
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
Cookie = {
'_qddac': '4-3-1.4euvh3.51etrl.jz7ny77d',
'__root_domain_v': '.fjggfw.gov.cn',
'_qddaz': 'QD.hldktx.4myn8z.jz0rop48',
'ASP.NET_SessionId': '2vw4lzuocibr4nnhxsthnkoa',
'Hm_lvt_63d8823bd78e78665043c516ae5b1514': '1565232336,1565245654,1565318931,1565422427',
'Hm_lvt_94bfa5b89a33cebfead2f88d38657023': '1565232336,1565245655,1565318931,1565422427',
'Hm_lpvt_94bfa5b89a33cebfead2f88d38657023': '1565569989',
'Hm_lpvt_63d8823bd78e78665043c516ae5b1514': '1565569990',
'_qdda': '4-1.4euvh3',
'_qddab': '4-okbsm1.jz7ny77h',
'_qddamta_2852155767=': '4-0',
'_qddagsx_02095bad0b': 'ba8daf85fe0dbeb0a65a7ea578a68929ff792177b87c13b3d9814691d5e079395d73da9a63d4e4dc40372ff0b2be56289e7c533dd0d63924c5efad41f77c98c4db44cb6ac7e47072e67fada11102036bc4b391cd9855444824b1f352724e11a0e0bd6359823b1633ef2881fecf9fed10d843e0803d0dad0f3f907099eb15e252'
}
def start_requests(self):
pages = 10
for page in range(1,pages):
params = {
'OPtype': 'GetListNew',
"pageNo": str(page),
"pageSize":'10',
"proArea":'-1',
'category':'GCJS',
'announcementType': '-1',
'ProType': '-1',
'xmlx':'-1',
"projectName":'',
"TopTime":'2019-05-14 00:00:00',
"EndTime":'2019-08-14 23:59:59',
}
try:
yield scrapy.FormRequest(self.base_url, formdata= params, callback=self.parse, cookies=self.Cookie, dont_filter=True)
except:
print("FormRequest报错")
pass
def parse(self, response):
print("*" * 50)
item = BidItem()
try:
if response.text: # str(response.content,'utf-8')
jsons = json.loads(response.text)
bids = jsons.get('data')
for bid in bids:
item['name'] = bid.get('NAME')
item['district'] = bid.get('AREANAME')
item['endRegistration'] = None
item['type'] = bid.get('PROTYPE_TEXT')
item['purl'] = '--'
item['tenderee'] = '--'
item['tenderer'] = '--'
item['address'] = '--'
item['docnmb'] = bid.get('PLATFORM_CODE')
item['startaffich'] = bid.get('TM')
item['endaffich'] = None
item['startRegistration'] = None
yield item
except:
print('response 为空')
pass