hadoop基础----hadoop实战(四)-----myeclipse开发MapReduce---myeclipse搭建hadoop开发环境并运行wordcount
我们在上一章已经尝试了在在hadoop中运行MapReduce。
hadoop基础----hadoop实战(三)-----hadoop运行MapReduce---对单词进行统计--经典的自带例子wordcount
其实hadoop学习可以分成2部分,一部分是hadoop的运维性能优化,一部分就是hadoop开发----写MapReduce。
本章我们尝试正常的开发流程----用myeclipse写wordcount单词统计的MapReduce并运行。
版本
hadoop 1.2.1 安装过程可查看
hadoop基础----hadoop实战(一)-----hadoop环境安装---手动安装官方1.0版本
myeclipse 10.7.1
安装Hadoop开发插件
新版本的hadoop安装路径下contrib/目录里有个插件hadoop-*.*.*-eclipse-plugin.jar(不同版本*会有差异), 拷贝到myeclipse根目录下/dropins目录下。然后重新启动myeclipse即可。
我的hadoop安装目录是在虚拟机中的/home/joe/hadoop/hadoop-1.2.1
我们在安装目录下找一下插件。
发现hadoop-1.2.1版本是没有eclipse-plugin.jar插件的。但是在src/contrib/目录下可以看到eclipse-plugin文件夹,此中包含的即是我们所需要的eclipse插件的源码工程。
需要把源码进行配置打包编译成jar才能用。

配置编译eclipse-plugin的jar包有点麻烦。
有兴趣的可以参考下面2篇文章,也可以直接下载其他人编译好的来使用:
下载地址
hadoop-eclipse-plugin-1.2.1.jar
编译教程
编译hadoop 1.2.1 Hadoop-eclipse-plugin插件
大数据学习笔记——hadoop1.2.1 eclipse_plugin编译、安装及使用
无论是自己编译的还是下载别人编译好的,我们现在有了一个hadoop-eclipse-plugin-1.2.1.jar 如图:
放到myeclipse安装目录的/dropins目录下。然后重启myeclipse。
重启成功后会提示加载插件成功。
在myeclipse的选项卡中Window ---->Prefrences中如果出现了Hadoop Map/Reduce则说明安装插件成功。

(ps:这里的hadoop installation directory需要把hadoop的安装包解压到本机windows系统再去选择,详细步骤往下看)
设置本地的Hadoop安装运行目录
因为我们是在myeclipse中运行mapreduce,所以需要用到一些hadoop相关的包,如果是打成jar在linux的hadoop上运行是不需要这个流程的,但是为了本地测试方便,我们把linux上的安装包下载下来解压到D盘中。选择它作为本地Hadoop安装运行目录。

Window ---->Prefrences---->Hadoop Map/Reduce选择该路径OK即可。

显示Map/Reduce选项卡


这时候我们可以看到出现了MapReduce的视图:
![]()


ps:如果Map/Reduce Locations视图没出现的话需要打开。因为下一步需要用到。
【Window】->【Show View】->【Map/Reduce Locations】->【OK】
或者
【Window】->【Show View】->【Other...】->【MapReduce Tools】->【Map/Reduce Locations】->【OK】

创建hadoop连接
新建连接
在Map/Reduce Locations选项卡视图中右键单击 选择新建new hadoop location。


配置连接
根据我们之前的安装情况填入相关信息:
location name
可以自己起个名字作为当前链接的标识。我这里随便起一个名称叫hadooptest。
Map/Reduce Master
这个框里
Host:就是jobtracker 所在的集群机器
Hort:就是jobtracker 的port
这两个参数就是安装hadoop配置的mapred-site.xml里面mapred.job.tracker里面的ip和port 。


也就是我们应该填 192.168.30.180 和 9001。
DFS Master
这个框里
Host:就是namenode所在的集群机器
Port:就是namenode的port
这两个参数就是core-site.xml里面fs.default.name里面的ip和port。
(Use M/R master host,这个复选框如果选上,就默认和Map/Reduce Master这个框里的host一样,如果不选择,就可以自己定义输入,这里jobtracker 和namenode在一个机器上,所以是一样的,就勾选上就可以了)


也就是我们应该填 192.168.30.180 和 9000。
user name
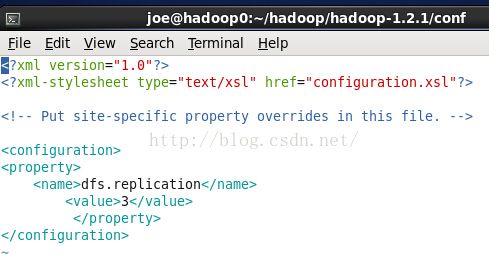
这个是连接hadoop的用户名。如果hdfs-site.xml配置中的是:
如上所示为false时,则不需要验证用户名,这个用户名随便设,否则就要改成在linux中搭建hadoop平台使用的linux帐号---我用的是joe。
我们这里没有设置,所以还是填写joe。
配置完成后如图:

配置临时目录
advance parameters tab页中可以编辑修改目录等参数。可以根据需求进行调整。
找到临时目录参数"hadoop.tmp.dir"。
我这里把它修改成我们之前hadoop安装时设置的临时目录,跟core-site.xml中设置的对应。

如图,我这里需要设置成/home/joe/hadoop/hadooptmpdir
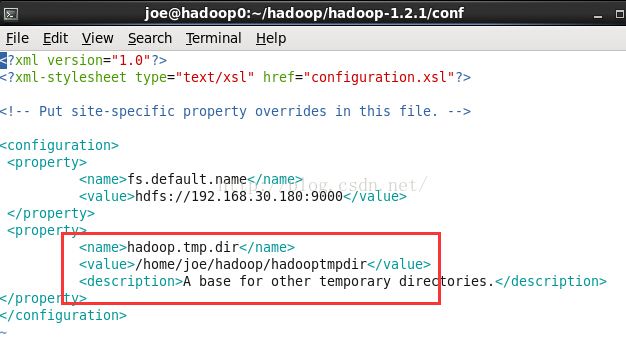

然后点击finish按钮,此时,这个视图中就有多了一条记录。

如果我们已经要启动了windows系统中的sshd服务(一般都是开启的,没有开启的话自己查下资料开启一下),而且启动了linux中的hadoop集群。
这时,我们的DFS Location就已经能连接上了,也就是在项目图中看hadoop集群上的文件。如图:

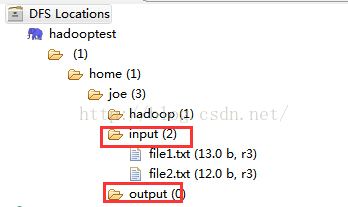
创建输入目录
DFS Locations中右键可以很方便的创建目录,我们就可以先创建输入输出目录。
我这里就在home/joe目录下创建一个input目录(output不需要创建,会自动生成)如图

然后分别输入目录名,创建可能需要一定的时间,请等待一段时间后再刷新。

这个时候在linux的hadoop中也可以看到我们通过DFS Locations创建的目录

上传需要处理的文件
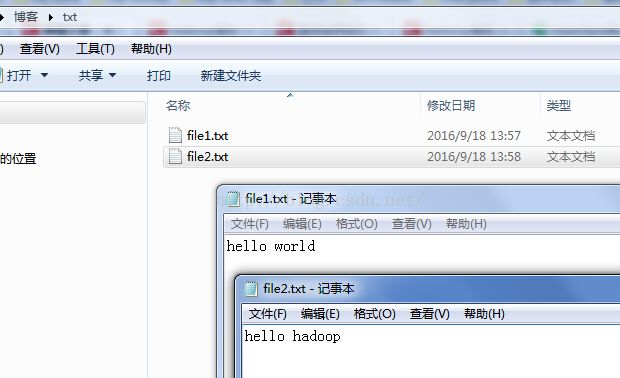
为了结果运行的是否正确,我们这里需要创建2个文件,跟之前的一样:
file1.txt中内容是
hello world
file2.txt中内容是
hello hadoop

我们在本地windows中创建之后通过DFS Locations上传上去.

同理,上传也需要消耗一定的时间,请等待一段时间后再刷新。

新建mapreduce项目
经过前面的准备我们开始创建mapreduce项目,在过程中需要选择Hadoop的安装路径。
如果是windows系统安装的hadoop则填写本地的安装路径,如果是linux系统中安装的hadoop则需要写linux中安装的绝对路径。
我们之前在安装篇已经知道 安装目录是 /home/joe/hadoop/hadoop-1.2.1。
创建项目步骤如下:
如果前面设置了本地hadoop安装运行目录则步骤为:
【File】->【New】->【Project...】->【Map/Reduce】->【Map/Reduce Project】->【Project name: WordCount】->【Next】->【Allow output folders for source folders】->【Finish】
否则为:
【File】->【New】->【Project...】->【Map/Reduce】->【Map/Reduce Project】->【Project name: WordCount】->【Configure Hadoop install directory...】->【Hadoop installation directory:d:/hadoop/hadoop-1.2.1】->【Apply】->【OK】->【Next】->【Allow output folders for source folders】->【Finish】




创建成功后出现了wordCount项目如下,已经自动引入了hadoop的一些包:
ps:Map/Reduce Project与普通java项目的区别其实就是会自动引入hadoop的相关jar包,新建一个普通jar项目再引入用到的jar其实是一样的效果。
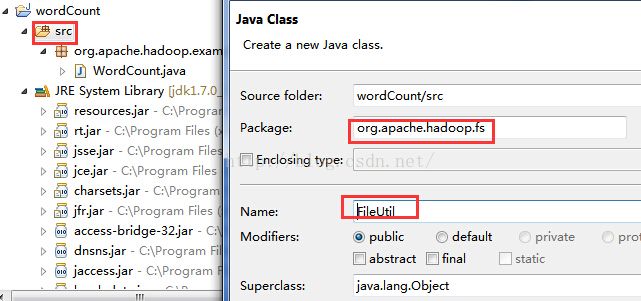
新建计数MapReduce的类WordCount
【wordCount】->【src】->【右键New】->【Class】->【Package: org.apache.hadoop.examples】->【Name: WordCount】->【Finish】
 、
、

Package和Name可以随意起,不过为了对应,我们还是按规范取名。点击Finish,就新建了一个类。

这个时候这个类就空的,如果是我们正常的开发流程的话,这里就是我们写mapreduce的地方。
但是我们是为了实现hadoop的经典例子单词计数---WordCount。
那我们可以在本地hadoop的安装目录src中找到WordCount的源码直接粘贴上去。

粘贴过来的完整代码为:
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
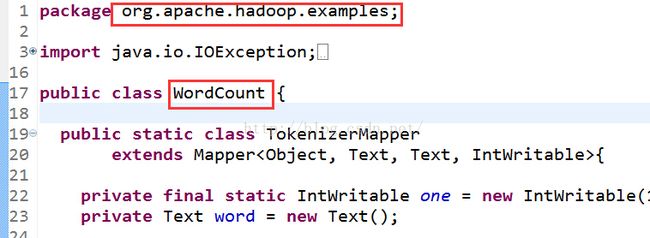
public class WordCount {
public static class TokenizerMapper
extends Mapper{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount ");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
配置运行参数
我们在linux中运行WordCount例子时都知道 需要传参数进去,比如输入目录和输出目录。
我们在myeclipse中运行也需要传入参数,这个参数就是我们需要配置的。
【Run】->【Run Configurations】->【Java Application】->【Word Count】->【Arguments】->【Program arguments: hdfs://192.168.30.180:9000/home/joe/input/* hdfs://192.168.30.180:9000/home/joe/output】->【VM arguments: -Xms512m -Xmx512m】->【Apply】->【Close】->【Run】->【Run As】->【Run On Hadoop】
参数地址的ip与端口需要跟我们前面设置的对应,路径需要与我们创建的路径对应:


如果之前没运行过 需要新建一个运行项目命名为WordCount,project名不用改,在search中选中WordCount类然后点击Apply即可:


然后点击Arguments,填写参数,填写完后不马上run,因为需要run on hadoop,所以先close:
参数分别是:
hdfs://192.168.30.180:9000/home/joe/input/* hdfs://192.168.30.180:9000/home/joe/output
和
-Xms512m -Xmx512m

运行
配置完参数后可以运行了,对着wordCount项目右键,run as---》run on hadoop。
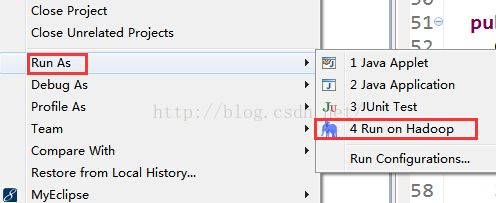

选中之前创建的hadoop连接:

可能遇到的问题
Failed to set permissions of path
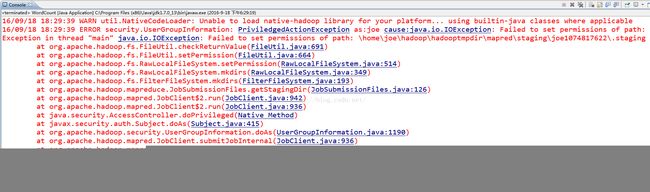
原因
这是windows的文件权限问题,会在运行时检查是否有fs的操作权限,因为我们是在myeclipse中运行的,所以是没有fs的权限的。
把wordcount项目打成jar包放到linux的hadoop中运行是没有问题的。
在源码中也可以看到错误出现在权限验证上:
然后依据at org.apache.hadoop.fs.FileUtil.checkReturnValue(FileUtil.java:690)这个错误信息找到了源代码,
然后一步步调试到Win32FileSystem.class中的
public native boolean setPermission(File f, int access, boolean enable, boolean owneronly);方法,
这个native格式的方法可能在c或者c++里面调用了,没法继续跟踪了,所以我这里的解决方法是把
private static void checkReturnValue(boolean rv, File p,
FsPermission permission
) throws IOException {
if (!rv) {
throw new IOException("Failed to set permissions of path: " + p +
" to " +
String.format("%04o", permission.toShort()));
}
}
标记经色部分的代码先注释掉,保证在windows下測试通过。
解决方法
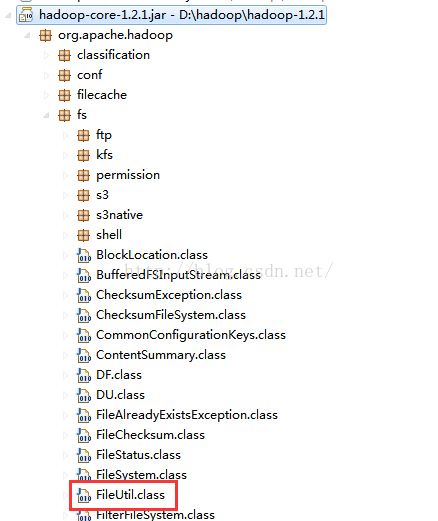
方法一修改src中的文件后重新打jar包替换

方法二在wordCount项目中新建一个一样的class修改


Output directory hdfs already exists
错误信息
16/09/18 19:11:36 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/09/18 19:11:36 INFO mapred.JobClient: Cleaning up the staging area file:/home/joe/hadoop/hadooptmpdir/mapred/staging/joe1823456898/.staging/job_local1823456898_0001
16/09/18 19:11:36 ERROR security.UserGroupInformation: PriviledgedActionException as:joe cause:org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://192.168.30.180:9000/home/joe/output already exists
Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://192.168.30.180:9000/home/joe/output already exists
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:137)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:973)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:936)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1190)
at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:936)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:550)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:580)
at org.apache.hadoop.examples.WordCount.main(WordCount.java:67)
原因
解决方法
正常运行控制台输出

16/09/18 19:19:03 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/09/18 19:19:03 INFO input.FileInputFormat: Total input paths to process : 2
16/09/18 19:19:03 WARN snappy.LoadSnappy: Snappy native library not loaded
16/09/18 19:19:03 INFO mapred.JobClient: Running job: job_local1169610468_0001
16/09/18 19:19:03 INFO mapred.LocalJobRunner: Waiting for map tasks
16/09/18 19:19:03 INFO mapred.LocalJobRunner: Starting task: attempt_local1169610468_0001_m_000000_0
16/09/18 19:19:03 INFO mapred.Task: Using ResourceCalculatorPlugin : null
16/09/18 19:19:03 INFO mapred.MapTask: Processing split: hdfs://192.168.30.180:9000/home/joe/input/file1.txt:0+13
16/09/18 19:19:03 INFO mapred.MapTask: io.sort.mb = 100
16/09/18 19:19:04 INFO mapred.MapTask: data buffer = 79691776/99614720
16/09/18 19:19:04 INFO mapred.MapTask: record buffer = 262144/327680
16/09/18 19:19:04 INFO mapred.MapTask: Starting flush of map output
16/09/18 19:19:04 INFO mapred.MapTask: Finished spill 0
16/09/18 19:19:04 INFO mapred.Task: Task:attempt_local1169610468_0001_m_000000_0 is done. And is in the process of commiting
16/09/18 19:19:04 INFO mapred.LocalJobRunner:
16/09/18 19:19:04 INFO mapred.Task: Task 'attempt_local1169610468_0001_m_000000_0' done.
16/09/18 19:19:04 INFO mapred.LocalJobRunner: Finishing task: attempt_local1169610468_0001_m_000000_0
16/09/18 19:19:04 INFO mapred.LocalJobRunner: Starting task: attempt_local1169610468_0001_m_000001_0
16/09/18 19:19:04 INFO mapred.Task: Using ResourceCalculatorPlugin : null
16/09/18 19:19:04 INFO mapred.MapTask: Processing split: hdfs://192.168.30.180:9000/home/joe/input/file2.txt:0+12
16/09/18 19:19:04 INFO mapred.MapTask: io.sort.mb = 100
16/09/18 19:19:04 INFO mapred.MapTask: data buffer = 79691776/99614720
16/09/18 19:19:04 INFO mapred.MapTask: record buffer = 262144/327680
16/09/18 19:19:04 INFO mapred.MapTask: Starting flush of map output
16/09/18 19:19:04 INFO mapred.MapTask: Finished spill 0
16/09/18 19:19:04 INFO mapred.Task: Task:attempt_local1169610468_0001_m_000001_0 is done. And is in the process of commiting
16/09/18 19:19:04 INFO mapred.LocalJobRunner:
16/09/18 19:19:04 INFO mapred.Task: Task 'attempt_local1169610468_0001_m_000001_0' done.
16/09/18 19:19:04 INFO mapred.LocalJobRunner: Finishing task: attempt_local1169610468_0001_m_000001_0
16/09/18 19:19:04 INFO mapred.LocalJobRunner: Map task executor complete.
16/09/18 19:19:04 INFO mapred.JobClient: map 100% reduce 0%
16/09/18 19:19:04 INFO mapred.Task: Using ResourceCalculatorPlugin : null
16/09/18 19:19:04 INFO mapred.LocalJobRunner:
16/09/18 19:19:04 INFO mapred.Merger: Merging 2 sorted segments
16/09/18 19:19:04 INFO mapred.Merger: Down to the last merge-pass, with 2 segments left of total size: 53 bytes
16/09/18 19:19:04 INFO mapred.LocalJobRunner:
16/09/18 19:19:05 INFO mapred.Task: Task:attempt_local1169610468_0001_r_000000_0 is done. And is in the process of commiting
16/09/18 19:19:05 INFO mapred.LocalJobRunner:
16/09/18 19:19:05 INFO mapred.Task: Task attempt_local1169610468_0001_r_000000_0 is allowed to commit now
16/09/18 19:19:05 INFO output.FileOutputCommitter: Saved output of task 'attempt_local1169610468_0001_r_000000_0' to hdfs://192.168.30.180:9000/home/joe/output
16/09/18 19:19:05 INFO mapred.LocalJobRunner: reduce > reduce
16/09/18 19:19:05 INFO mapred.Task: Task 'attempt_local1169610468_0001_r_000000_0' done.
16/09/18 19:19:05 INFO mapred.JobClient: map 100% reduce 100%
16/09/18 19:19:05 INFO mapred.JobClient: Job complete: job_local1169610468_0001
16/09/18 19:19:05 INFO mapred.JobClient: Counters: 19
16/09/18 19:19:05 INFO mapred.JobClient: File Output Format Counters
16/09/18 19:19:05 INFO mapred.JobClient: Bytes Written=25
16/09/18 19:19:05 INFO mapred.JobClient: FileSystemCounters
16/09/18 19:19:05 INFO mapred.JobClient: FILE_BYTES_READ=68294
16/09/18 19:19:05 INFO mapred.JobClient: HDFS_BYTES_READ=63
16/09/18 19:19:05 INFO mapred.JobClient: FILE_BYTES_WRITTEN=281922
16/09/18 19:19:05 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=25
16/09/18 19:19:05 INFO mapred.JobClient: File Input Format Counters
16/09/18 19:19:05 INFO mapred.JobClient: Bytes Read=25
16/09/18 19:19:05 INFO mapred.JobClient: Map-Reduce Framework
16/09/18 19:19:05 INFO mapred.JobClient: Reduce input groups=3
16/09/18 19:19:05 INFO mapred.JobClient: Map output materialized bytes=61
16/09/18 19:19:05 INFO mapred.JobClient: Combine output records=4
16/09/18 19:19:05 INFO mapred.JobClient: Map input records=2
16/09/18 19:19:05 INFO mapred.JobClient: Reduce shuffle bytes=0
16/09/18 19:19:05 INFO mapred.JobClient: Reduce output records=3
16/09/18 19:19:05 INFO mapred.JobClient: Spilled Records=8
16/09/18 19:19:05 INFO mapred.JobClient: Map output bytes=41
16/09/18 19:19:05 INFO mapred.JobClient: Total committed heap usage (bytes)=1556938752
16/09/18 19:19:05 INFO mapred.JobClient: Combine input records=4
16/09/18 19:19:05 INFO mapred.JobClient: Map output records=4
16/09/18 19:19:05 INFO mapred.JobClient: SPLIT_RAW_BYTES=232
16/09/18 19:19:05 INFO mapred.JobClient: Reduce input records=4
查看运行结果
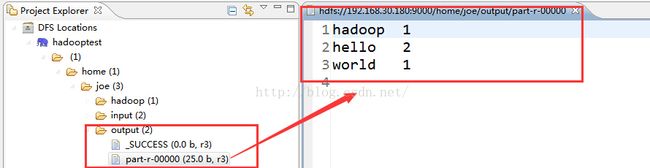
生产环境的运行开发流程
我们本章学习了怎么在myeclipse中写mapreduce并测试运行。
但是生产环境中一般都是在linux中定时运行的 不会通过myeclipse来操作,那么一般来说我们的myeclipse只提供测试运行。
最终还是要把mapreduce打成jar包放到linux中运行。
linux中运行的方法已经在上一章中讲述。当然我们也可以借助jenkins等自动编译运行组件与maven和svn配合使用,更方便。
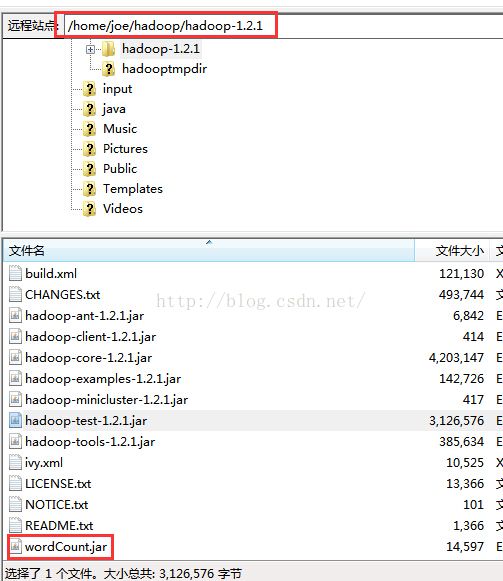
我们把wordCount项目打包成一个jar包。


并上传到linux的hadoop安装目录中/home/joe/hadoop/hadoop-1.2.1。
在linux中运行hadoop命令
hadoop jar /home/joe/hadoop/hadoop-1.2.1/wordCount.jar org.apache.hadoop.examples.WordCount /home/joe/input /home/joe/output2
这个地方的需要与运行的包名类名一致。
成功运行后可以看到结果



说明我们创建的wordCount项目和打的jar包没问题,能正常使用运行。
现在我们已经熟悉了流程,下一章就开始详细的学习mapreduce的写法。