![]() 100天搞定机器学习(Day1-34)
100天搞定机器学习(Day1-34)
![]()
100天搞定机器学习|Day35 深度学习之神经网络的结构
![]()
100天搞定机器学习|Day36 深度学习之梯度下降算法
本篇为100天搞定机器学习之第37天,亦为3Blue1Brown《深度学习之反向传播算法》学习笔记。
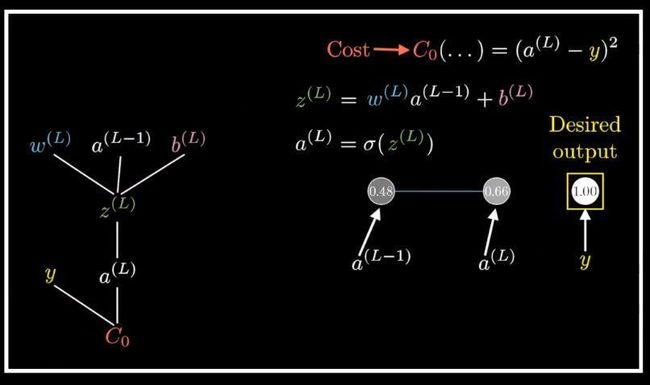
上集提到我们要找到特定权重和偏置,从而使代价函数最小化,我们需要求得代价函数的负梯度,它告诉我们如何改变连线上的权重偏置,才能让代价下降的最快。反向传播算法是用来求这个复杂到爆的梯度的。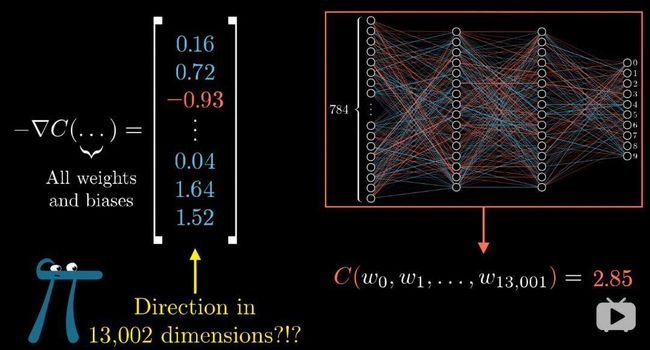
上一集中提到一点,13000维的梯度向量是难以想象的。换个思路,梯度向量每一项的大小,是在说代价函数对每个参数有多敏感。如下图,我们可以这样里理解,第一个权重对代价函数的影响是是第二个的32倍。
我们先不要管反向传播算法这一堆公式,当我们真正理解了这算法,这里的每一步就会无比清晰了。
我们来考虑一个还没有被训练好的网络。我们并不能直接改动这些激活值,只能改变权重和偏置值。但记住,我们想要输出层出现怎样的变动,还是有用的。我们希望图像的最后分类结果是2,我们期望第3个输出值变大,其余输出值变小,并且变动的大小应该与现在值和目标值之间的差成正比。举个例子,增大数字2神经元的激活值,就应该比减少数字8神经元的激活值来得重要,因为后者已经很接近它的目标了。
进一步,就来关注数字2这个神经元,想让它的激活值变大,而这个激活值是把前一层所有激活值的加权和加上偏置值。要增加激活值,我们有3条路可以走,一增加偏置,二增加权重,或者三改变上一层的激活值。先来看如何调整权重,各个权重它们的影响力各不相同,连接前一层最亮的神经元的权重,影响力也最大,因为这些权重与大的激活值相乘。增大这几个权重,对最终代价函数造成的影响,就比增大连接黯淡神经元的权重所造成的影响,要大上好多倍。
请记住,说到梯度下降的时候,我们并不只看每个参数是增大还是变小,我们还看改变哪个参数的性价比最大。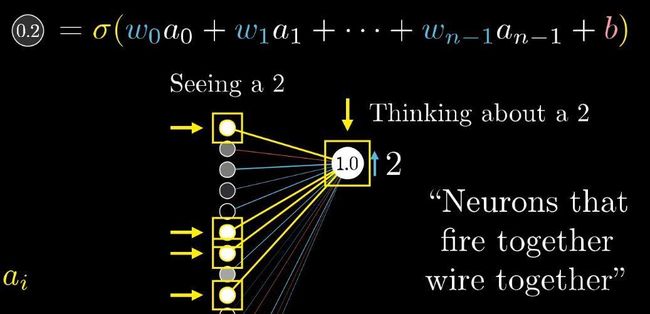
第三个可以增加神经元激活值的方法是改变前一层的激活值,如果所有正权重链接的神经元更亮,所有负权重链接的神经元更暗的话,那么数字2的神经元就会更强烈的激发。我们也要依据对应权重的大小,对激活值做成比例的改变,我们并不能直接改变激活值,仅对最后一层来说,记住我们期待的变化也是有帮助的。
不过别忘了,从全局上看,只只不过是数字2的神经元所期待的变化,我们还需要最后一层其余的每个输出神经元,对于如何改变倒数第二层都有各自的想法。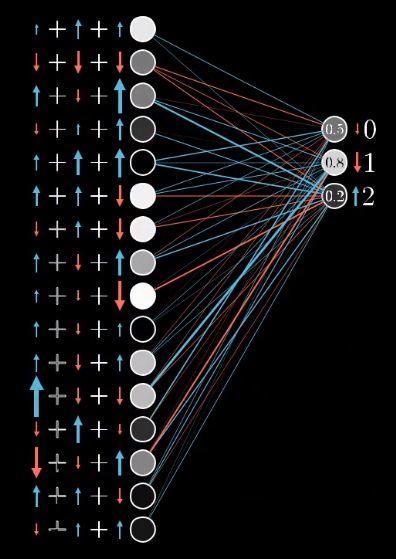
我们会把数字2神经元的期待,和别的输出神经元的期待全部加起来,作为如何改变倒数第二层的指示。这些期待变化不仅是对应的权重的倍数,也是每个神经元激活值改变量的倍数。
这其实就是在实现反向传播的理念了,我们把所有期待的改变加起来,得到一串对倒数第二层改动的变化量,然后重复这个过程,改变倒数第二层神经元激活值的相关参数,一直循环到第一层。我们对其他的训练样本,同样的过一遍反向传播,记录下每个样本想怎样修改权重和偏置,最后再去一个平均值。
这里一系列的权重偏置的平均微调大小,不严格地说,就是代价函数的负梯度,至少是其标量的倍数。神奇吧?
如果梯度下降的每一步都用上每一个训练样本计算的话,那么花费的时间就太长了。实际操作中,我们一般这样做:首先把训练样本打乱,然后分成很多组minibatch,每个minibatch就当包含了100个训练样本好了。然后你算出这个minibatch下降的一步,这不是代价函数真正的梯度,然而每个minibatch会给一个不错的近似,计算量会减轻不少。

可以这样比喻:沿代价函数表面下山,minibatch方法就像醉汉漫无目的的溜下山,但是速度很快。而之前的方法就像细致入微的人,事先准确的算好了下山的方向,然后谨小慎微的慢慢走。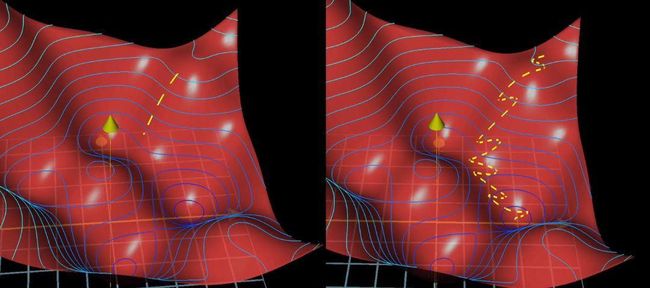
这就是随机梯度下降

总结一下:反向传播算法算的是单个训练样本怎样改变权重和偏置,不仅说每个参数应该变大还是变小,还包括这些变化的比例是多大才能最快地降低cost。真正的梯度下降,对好几万个训练范例都这样操作,然后对这些变化取平均值,这样计算太慢了,我们要把所有样本分到各个minibatch中,计算每个minibatch梯度,调整参数,不断循环,最终收敛到cost function的局部最小值上。理解是一回事,如何表示出来又是另一回事,下一期,我们一起将反向传播算法用微积分的形式推导出来,敬请期待!