Tensorflow实现DNN,手写数字识别
机器学习入门的时候,看吴恩达的视频,会有一个手写数字识别的作业,当时是用octave实现了核心的部分,之后了解了tensorflow,发现实现一个手写数字识别系统简直不要太简单,当时看的是这篇博客 ,清晰易懂。在此自己理清一下思路。注:代码参考这个博客
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("G:/tensorflow/data", one_hot=True)这两句是直接使用tensorflow中的模块,input_data 直接导入数据到项目中,第一个参数给定下载数据到目标目录,one_hot参数指将数据转成one_hot形式,如手写数字是0-9,若为0 ,则转为10维数据[1,0,0,0,0,0,0,0,0,0]。
import tensorflow as tf
learning_rate = 0.001
train_epochs = 20
batch_size = 64要使用tensorflow, 首先要引入它,然后应该初始化一个图,但是tensorflow中会默认一个图graph,所以可以跳过。此处设置学习速率为0.001,即模型优化时,采用的梯度下降方法,以0.001的学习速率向最优点逼近。train_epochs是指训练的轮数,每次训练选取batch_size组数据,每轮可以训练 mnist.train.num_examples / batch_size次。所以这是一个随机梯度下降(SGD)。
n_input = 784
n_hidden1 = 100
n_hidden2 = 100
n_classes = 10n_input为输入向量的维度,由于手写数字是28*28的(展开即784),故输入向量维度都是784,此处神经网络为2个隐藏层,1个输出层,隐藏层均为100个神经元。
x = tf.placeholder(tf.float32, shape=[None, n_input])
y = tf.placeholder(tf.float32, shape=[None, n_classes])设置两个占位符,x为输入,shape中第一个值为none代表行为不确定维度,第二个值表示有n_input列,同理得到y的设置。
weights = {'h1': tf.Variable(tf.random_normal([n_input, n_hidden1])),
'h2': tf.Variable(tf.random_normal([n_hidden1, n_hidden2])),
'out': tf.Variable(tf.random_normal([n_hidden2, n_classes]))}
biases = {'b1': tf.Variable(tf.random_normal([n_hidden1])),
'b2': tf.Variable(tf.random_normal([n_hidden2])),
'out': tf.Variable(tf.random_normal([n_classes]))}tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None) 实现从正态分布中输出随机值,参数的意义:
shape: 输出的张量的格式,如[3,2],即3行2列的矩阵,必须
mean: 正态分布的均值,默认为0。
stddev: 正态分布的标准差,默认为1。
dtype: 输出的类型。
seed: 一个整数,当设置之后,每次生成的随机数都一样,如果想每次都生成不一样,可以设置为None。
name: 操作的名字。tf.Variable()声明一个图变量
综上,这部分代码是生成了6个随机变量,h1,h2是隐藏层的权重,b1,b2是隐藏层的偏置,out分别是输出层的权重和偏置。
def inference(input_x):
layer_1 = tf.nn.relu(tf.matmul(x, weights['h1']) + biases['b1'])
layer_2 = tf.nn.relu(tf.matmul(layer_1, weights['h2']) + biases['b2'])
out_layer = tf.matmul(layer_2, weights['out']) + biases['out']
return out_layertf.matmul(a,b)即a*b
tf.nn.relu(features,none),比较fetures与0的大小,比0大则返回features,否则返回0.
综上,这部分代码是定义了一个函数,输入向量,返回通过3层神经网络之后的输出向量。
logits = inference(x)
prediction = tf.nn.softmax(logits)- tf.nn.softmax(logits),对上面得到的输出向量计算分类的概率,这样得到的10维向量就是该输入数字属于0-9这10个类的各自的概率。
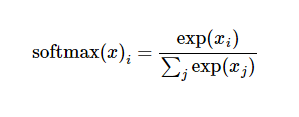
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
train_op = optimizer.minimize(loss)tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y),首先对输出的向量求softmax,然后与实际值y比较,求交叉熵,即:
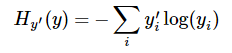
这里是将向量中所有维度的值的交叉熵求和。tf.reduce_mean(A,axis=0) 求平均值,指对输出的所有向量的交叉熵求均值,若axis不写,默认整体求均值,为0则按列求均值,为1则按行求均值。
tf.train.AdamOptimizer(learning_rate)adam优化算法,是一种基于梯度下降的变种算法,根据损失函数对每个参数的梯度的一阶矩估计和二阶矩估计动态调整针对于每个参数的学习速率。可以参考这篇介绍
此处实例化一个优化函数,然后用optimizer.minimize()计算得到最优的模型参数。
pre_correct = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))
accuracy = tf.reduce_mean(tf.cast(pre_correct, tf.float32))- tf.argmax(prediction, 1) 对所有预测的输出向量按列求最大值
- tf.equal(A,B) 判断A,B向量对应位置元素是否相等,返回同维向量,相应位置为true或false
- tf.cast() 实现类型转换
综上,实现预测值与实际输出的比较,并计算准确率,此处是指预测正确的数量/总数。
init = tf.global_variables_initializer()tensorflow中声明一张图及其内部张量节点之后,要先初始化。
with tf.Session() as sess:
sess.run(init)
total_batch = int(mnist.train.num_examples / batch_size)
for epoch in range(train_epochs):
for batch in range(total_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size)
sess.run(train_op, feed_dict={x:batch_x, y:batch_y})
if epoch % 10 == 0:
loss_, acc = sess.run([loss, accuracy], feed_dict={x:batch_x, y:batch_y})
print("epoch {}, loss {:.4f}, acc {:.3f}".format(epoch, loss_, acc))
print("optimizer finished!")
#计算测试集的准确度
test_acc = sess.run(accuracy, feed_dict={x:mnist.test.images, y:mnist.test.labels})
print('test accuracy', test_acc)tensorflow中,要实现计算,都是在session中进行的,且应用with结构,无需手动关闭会话。
sess.run(init),初始化所有张量
total_batch = int(mnist.train.num_examples / batch_size) 求的每轮训练有多少组数据
batch_x, batch_y = mnist.train.next_batch(batch_size) 每次得到下一个batch的数据
sess.run(train_op, feed_dict={x:batch_x, y:batch_y}) ,feed_dict的作用是给使用placeholder创建出来的tensor赋值。另外, feed 数据作为 run() 调用的参数. feed 只在调用它的方法内有效, 方法结束, feed 就会消失.。
loss_, acc = sess.run([loss, accuracy], feed_dict={x:batch_x, y:batch_y}) 每10轮训练。输出一次损失值和准确率。
20轮训练完成后,计算测试集的准确率,本方法输出结果为0.9312.