语言模型,bert,transformer,rnn
RNN问题:
问题. 1
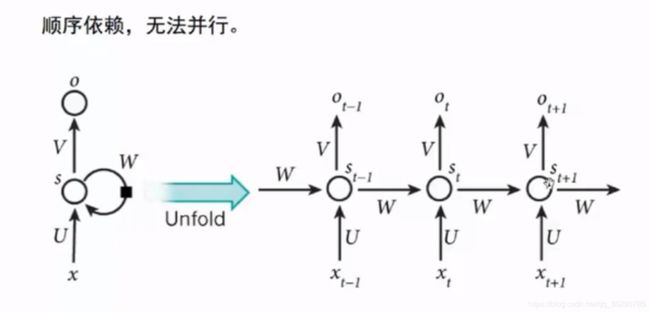
导致时间太长,效率低,不能够很深
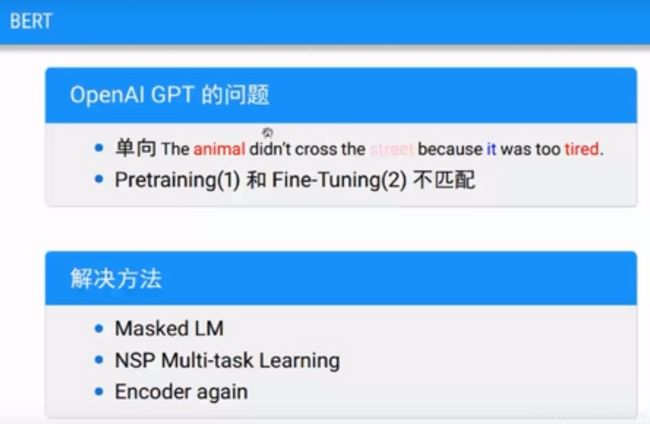
问题2:
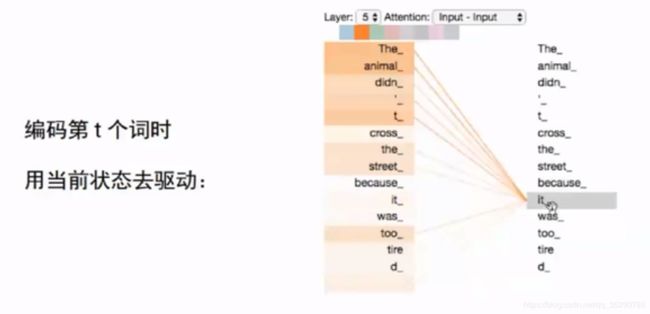
单项信息流,‘it’需要考虑前后的情况,RNN不支持

解决方法,
多个RNN如encoder-decoder就用attention,单个RNN就是Self-attention

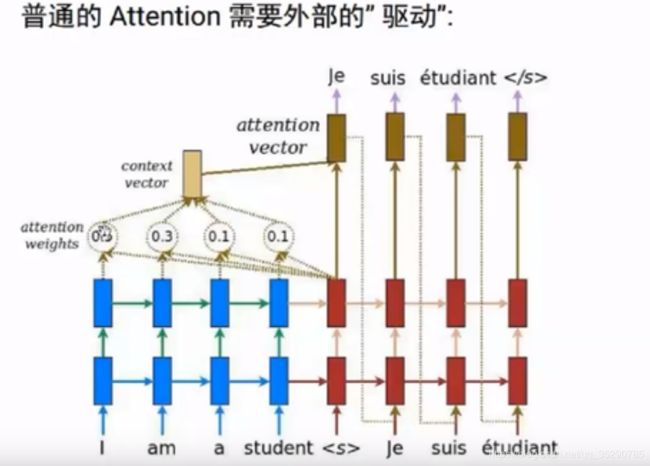
1.attention
如翻译模型中,需要之前的encoder信息
2.self-attention
自驱动的
Transform结构:
如翻译模型,用到了6层的encoder-decoder,每层中用了self-attention来解决RNN在多层中的问题
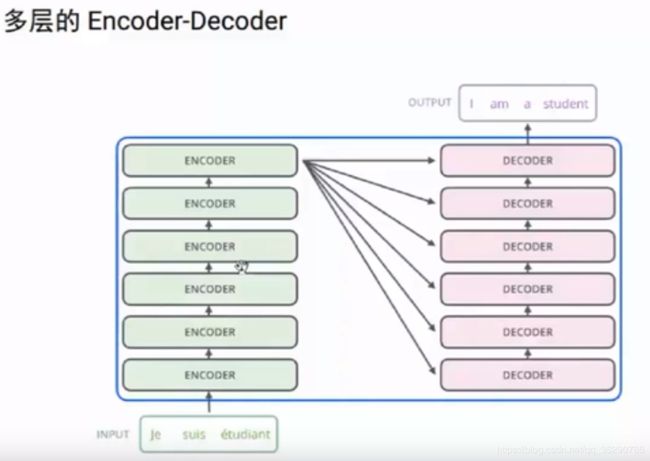
每层的结构是一样的
单层的结构 :
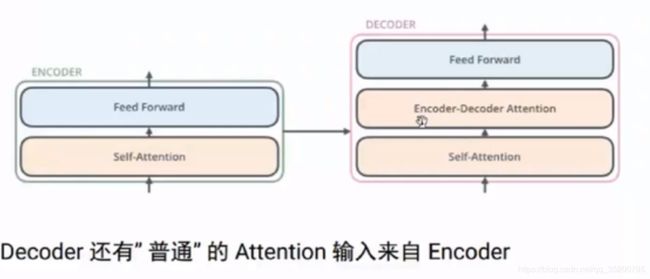
encoder:自attention+全连接层
decoder:自attention+普通encoder-decoder 的attention+全连接层
例子:
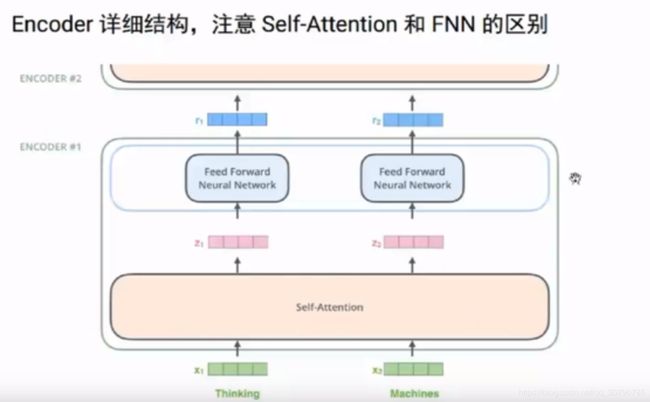
在embedding后selt-attention部分,是依赖所有的输入,即包含x1,x2的,而得到z1,z2后,是独立往上层网络传的,只要有z1就可以算r1,不需要z2.
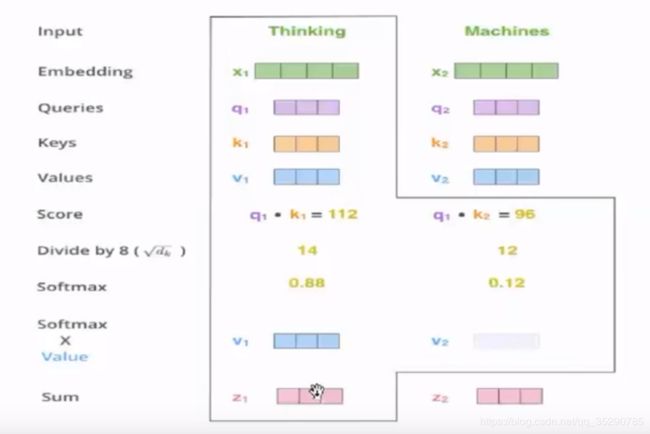
self-attention计算
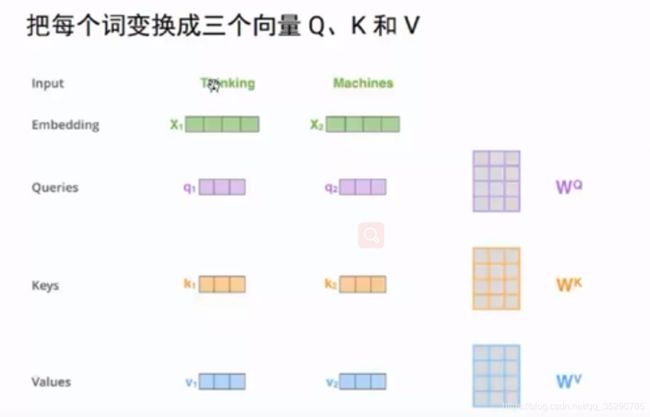
加权计算:
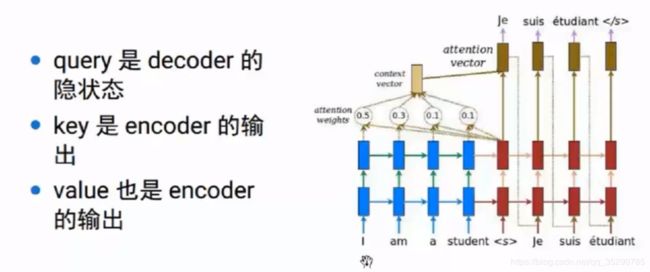
普通attention计算:
self-attention中的query,key,和value值可以看做普通attention一种特例
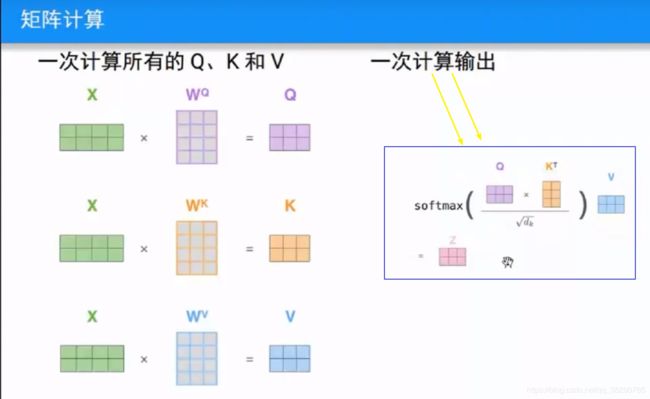
矩阵计算:
多个上面的计算 合并,通过矩阵计算
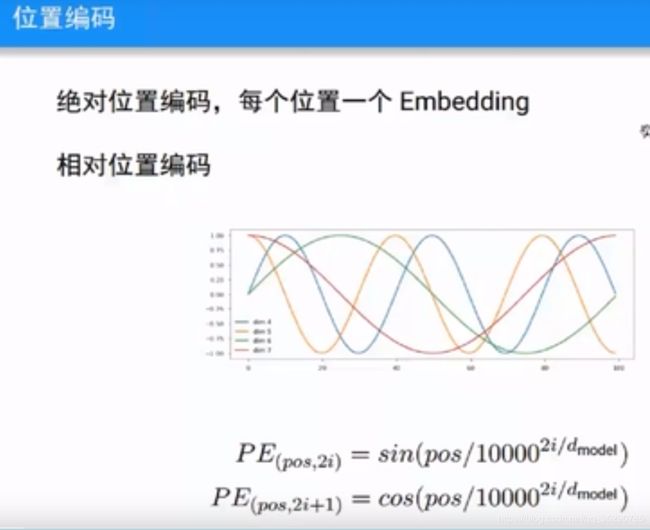
位置编码,传统使用的是
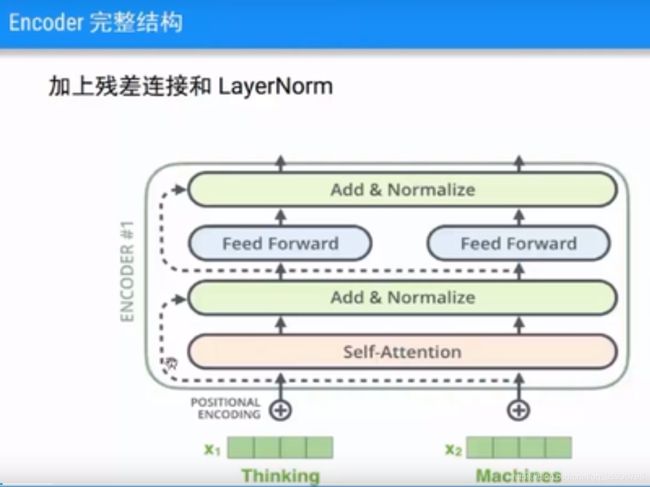
残差连接,和归一化
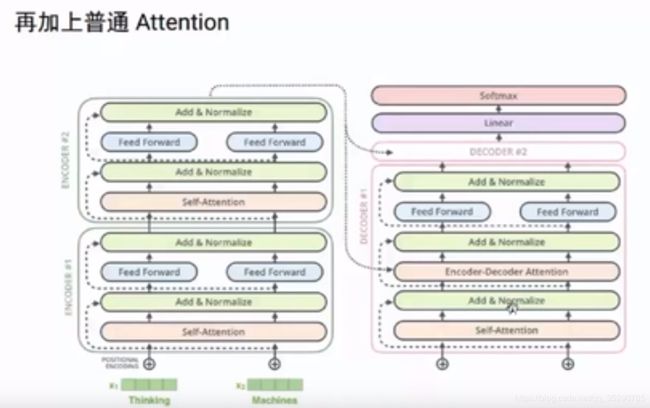
加上普通attention
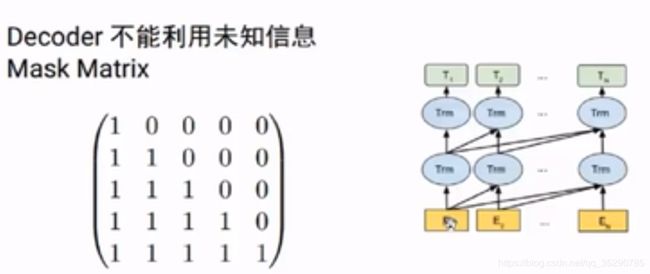
翻译第二个词可以看第一个词的信息,不能看没有翻译的第三个词

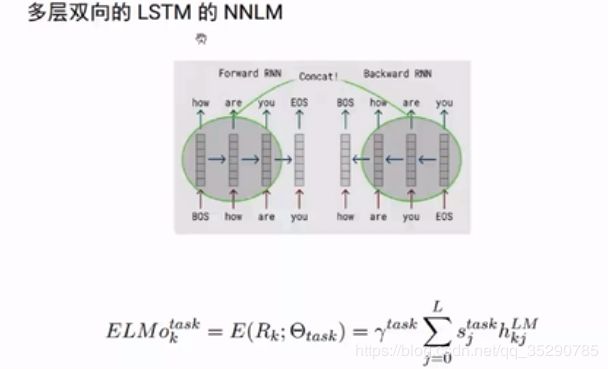
ELMo 模型,加入了上下文语义信息。