Mac MySQL安装和MySQL命令行
2018/04/17
安装MySQL (切记系统通知发过来的的初始密码)之后初次登录需要密码
https://segmentfault.com/a/1190000008472692
https://blog.csdn.net/pansanday/article/details/54915916
安装MySQL图形化界面工具(可不安装)
查看 mysql 端口号的方法是
show global variables like 'port';
Mac进入MySQL系统命令为
/usr/local/mysql/bin/mysql -u root -p 然后输入密码进入
首先手动启动Mysql应用程序
打开终端输入如下命令: /usr/local/mysql/bin/mysql -u root -p
(注意:Windows下的是: mysql -u root -p)
其中root为用户名。这时会出现如下命令:Enter password: 123456
这样就可以访问你的 数据库服务器了。
数据库操作
下面介绍一些关于从数据库创建到使用的一些简单的方法;
创建一个名字为mydatabase数据库: create database mydatabase ;
可以用以下地命令来查看创建的数据库是否成功: show databases ;
更改数据库名字 : alter databases Hdatabase ;
删除数据库 :drop database [if exists] mydatabase;
更改数据库mydatabase的字符集 : alter database mydatabase charset GBK ;
进入数据库: use mydatabase ;
用下面的命令来查看该数据库中的表: show tables ;
查询MySQL支持的存储引擎:show engines; show engines\g SHOW ENGINES\G
查询默认存储引擎 :SHOW VARIABLES LIKE 'storage_engine%';
表操作
用下面的命令来创建表:create table tb_admin (
->id int auto_increment primary key,
-> user varchar(30) not null,
-> password varchar(30) not null,
-> createtime datetime);
对于字符类型的有:
char:固定长度,存储
ANSI
字符,不足的补英文半角空格。
nchar:固定长度,存储Unicode字符,不足的补英文半角空格
varchar:可变长度,存储
ANSI
字符,根据数据长度自动变化。
nvarchar:可变长度,存储Unicode字符,根据数据长度自动变化。
也就是说:varchar 可变长度,
varchar(50)即长度为:50个字符
当有存入值时,就跟据实际的值的大小(长度)存入数据。
mysql
4.0版本以下
,varchar(50), 指的是
50字节
,如果存放utf8汉字时,只能存放16个(
每个汉字3字节
)
mysql 5.0版本以上,varchar(50), 指的是
50字符
,无论存放的是
数字、字母还是UTF8汉字
(
每个汉字3字节
),都可以存放50个。
用下面的命令来检查表的创建是否成功: show tables;
查看 表结构:show columns from 表名 from 库名;
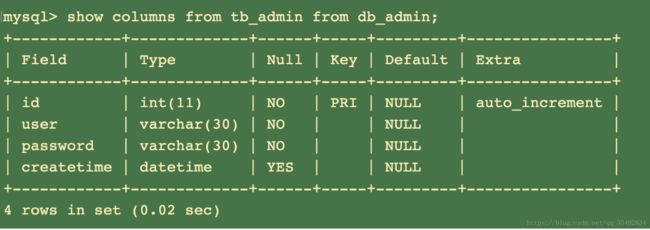
查看该表结构,表中字段的信息: desc 表名 ; describe 表名; show columns from 表名;
查看表中的某一列 :describe 数据表名 列名;
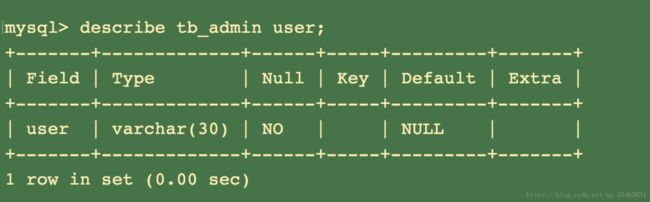
表增添新字段以及修改字段
初始表格

增加新字段 :alter table 表名 add 字段;

修改字段定义:alter table 表名 modify 字段名 定义;
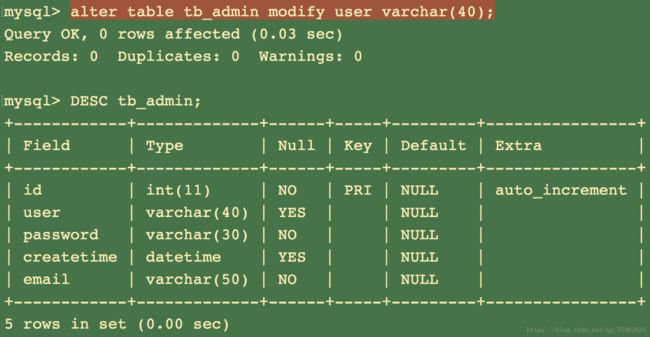
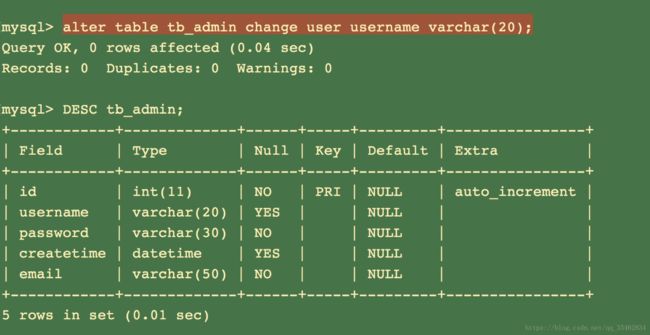
修改字段名
alter table 表名 change 需要修改的字段名 新字段名 字段定义;
删除字段:alter table 表名 drop 字段名;
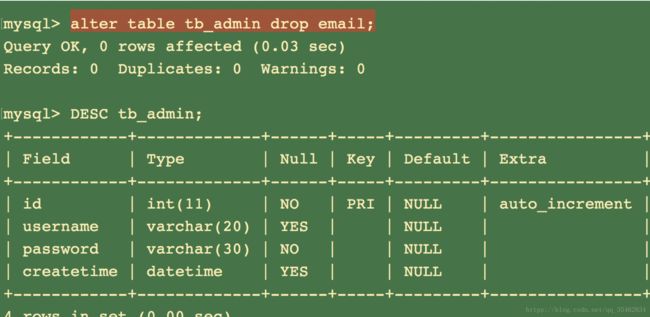
修改表名:alter table 表名 rename as 新表名;
将表tb_userNew 更名为 tb_userOld
alter table tb_userNew rename as tb_userOld;
重命名表:rename table 数据表名1 to 数据表名2;
将表tb_admin 重命名为tb_user
rename table tb_admin to tb_user;
复制表:create table 新表 like 旧表;
创建一份数据表tb_user的备份 tb_userNew
create table tb_userNew like tb_user;
复制表的结构并不复制表的数据
如果想要连表的数据一并复制执行下面命令行
create table
tb_userNew
as select * from
tb_user;
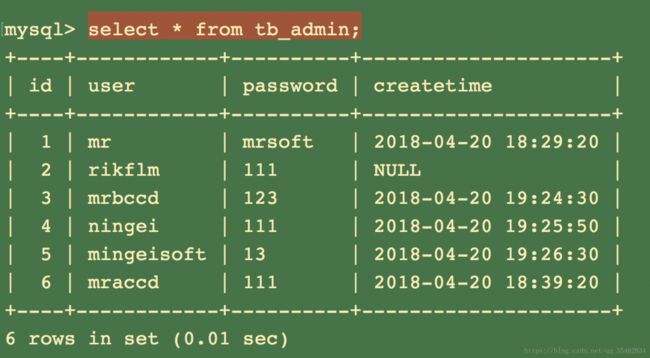
查看表中的数据:select * from 表名;
如果查看tb_admin表中的数据
select * from tb_admin;
删除表:drop table [if exists] 数据表名;
表中添加数据:
查看表的结构为

命令行进入数据库
use 数据库名;
insert into 表名 values(1,'mr','mrsoft','2018-04-20 18:29:20');#依据表的结构来进行添加
查看表数据信息:select * from 表名;
查看表中的某一列 :describe 数据表名 列名;

插入数据中的部分数据:use 库名;
insert into 表名(字段1,字段2,……) values(数据1,数据2,……);

插入多条数据:use 库名;
insert into 表名(字段1,字段2,……)
values(数据1,数据2,……)
,(数据1,数据2,……)
,(数据1,数据2,……)
,……

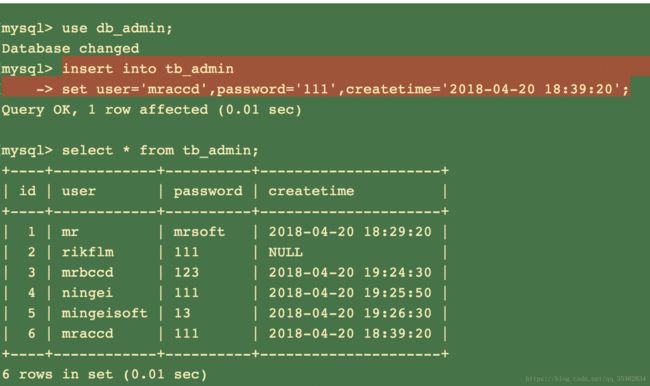
使用insert ……set 语句插入数据:
use 数据库名;
insert into 表名
set 字段1=数据1, 字段2=数据2, 字段3=数据3,……
插入查询结果
例:把db_admin.tb_mrbook表中的user和pass列插入db_admin.tb_admin中
先查询tb_mrbook
select * from tb_mrbook;
insert into db_admin.tb_admin
(user,password)
select user,pass from tb_mrbook;
修改数据
将管理员信息表tb_admin中的mrbccd的管理员密码123修改为456:
update db_admin.tb_admin set password='456' where user='mrbccd';
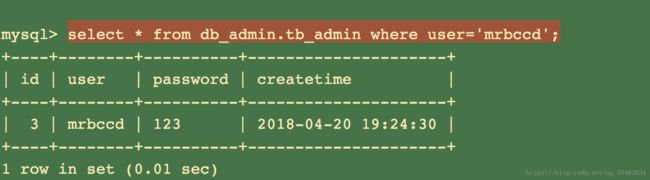
查看某一字段行
select * from db_admin.tb_admin where user='mrbccd';
删除数据
use db_admin;
delete from tb_admin where user='mr';
删除所有数据
truncate [table] 数据表名;
使用该语句表中的auto_increment自动计数器将重新设定为该列的初始值 无删除记录
delete删除auto_increment则不这样而且删除会有删除记录
表的查询
查询全表数据:
use 数据库名;
select * from 数据表名;
查询表中的一列或者多列:select 字段1,字段2,…… from 表名;

查看某一字段行where查找
select * from db_admin.tb_admin where user='mrbccd';

从一张表或者多张表中获取数据
例:从tb_admin表和tb_students表中查询tb_admin.id、tb_admin.user、tb_students.id、tb_students.name字段的值
命令如:select tb_admin.id,tb_admin.user,tb_students.id,tb_students.name from tb_admin,tb_students;
总结 前面写了增删改最后说一下查
查
查询所有字段
:select * from 表名;
查询指定字段
:select 字段名 from 表名;
查询指定数据
:select * from 表名 where 字段1=数据1;
查询关键字
:select * from 表名 where 条件 [not] in(数据1,数据2,……);
带关键字 between and的范围查询
:select * from 表名 where 条件 [not] between 取值1 and 取值2;
带like的字符匹配查询
:含有两种通配符%和_ A%B 搜索以A开头以B结尾的数据 %A%搜索含有A的数据
m_n搜索以m开头以n结尾的三个字符 _ 代表任意一个字符中英文字符视作无差距。
例:查询tb_login表中user字段中包含mr字符的数据:select * *from tb_login where user like '%mr%';
使用is [not] null查询空值用来判断字段是否为空值(null)
查询tb_book表中name 字段的值为空的记录:select books,row from tb_book where row is null;
带有and or的多条件查询
:select * from tb_login where user='mr' and section='php';
select * from tb_login where section='php' or section'程序开发';
使用distinct 去除结果中的重复行
:select distinct 字段名 from 表名;
使用order by 对查询结果排序
:order by 字段名 [asc(升序)|desc(降序)];
使用group by 分组查询
:只显示该组中的一条信息:select id,books,talk from tb_book group by talk;
使用limit 限制查询数量 通过id的升序排列查询三条信息
:select * from tb_login order by id asc limit 3;
从第5条开始查询3条信息:select * from tb_login order by id asc limit 5,3;
函数
select count(*) from tb_login;查询对于除*以外的任何参数,返回所选择集合中非null值的行的数目。
select sum(row) from tb_book; 显示row字段中字段的总和。
select avg(row) from tb_book;显示row字段的平均值为0的计算在内,为null的不计算在内。
select max(row)from tb_book;显示row字段中数字最大的值。
select min(row)from tb_book;显示row字段中数字最小的值。
查询tb_login表中的记录,但user字段值必须在tb_book表中的user字段中出现过
:
select * from tb_login where user in (select user from tb_book);
带有比较运算符的子查询
:select id,books,row from tb_book where row>=(select row from tb_row where id=1);
合并查询结果
:union 和 union all
select user from tb_book
union
select user from tb_login;
合并相同查询结果项进行输出显示
select user from tb_book
union all
select user from tb_login;
列举所有查询结果
SQL中常用模糊查询的四种匹配模式&&正则表达式
执行数据库查询时,有完整查询和模糊查询之分。
一般模糊语句如下:
SELECT 字段 FROM 表 WHERE 某字段 Like 条件
其中关于条件,SQL提供了四种匹配模式:
1、
%
:表示任意0个或多个字符。可匹配任意类型和长度的字符,有些情况下若是中文,请运用两个百分号(%%)表示。
比如 SELECT * FROM [user] WHERE u_name LIKE '%三%'
将会把u_name为“张三”,“张猫三”、“三脚猫”,“唐三藏”等等有“三”的记录全找出来。
另外,如果须要找出u_name中既有“三”又有“猫”的记录,请运用 and条件
SELECT * FROM [user] WHERE u_name LIKE '%三%' AND u_name LIKE '%猫%'
若运用 SELECT * FROM [user] WHERE u_name LIKE '%三%猫%'
虽然能搜索出“三脚猫”,但不能搜索出符合条件的“张猫三”。
2、
_
: 表示任意单个字符。匹配单个任意字符,它常用来限定表达式的字符长度语句:
比如 SELECT * FROM [user] WHERE u_name LIKE '_三_'
只找出“唐三藏”这样u_name为三个字且中间一个字是“三”的;
再比如 SELECT * FROM [user] WHERE u_name LIKE '三__';
只找出“三脚猫”这样name为三个字且第一个字是“三”的;
3、
[ ]
:表示括号内所列字符中的一个(类似正则表达式)。指定一个字符、字符串或范围,要求所匹配对象为它们中的任一个。
比如 SELECT * FROM [user] WHERE u_name LIKE '[张李王]三'
将找出“张三”、“李三”、“王三”(而不是“张李王三”);
如 [ ] 内有一系列字符(01234、abcde之类的)则可略写为“0-4”、“a-e”
SELECT * FROM [user] WHERE u_name LIKE '老[1-9]'
将找出“老1”、“老2”、……、“老9”;
4、
[^ ]
:表示不在括号所列之内的单个字符。其取值和 [] 相同,但它要求所匹配对象为指定字符以外的任一个字符。
比如 SELECT * FROM [user] WHERE u_name LIKE '[^张李王]三'
将找出不姓“张”、“李”、“王”的“赵三”、“孙三”等;
SELECT * FROM [user] WHERE u_name LIKE '老[^1-4]';
将排除“老1”到“老4”,寻找“老5”、“老6”、……
5、查询内容包含通配符时
由于通配符的缘故,导致我们查询特殊字符“%”、“_”、“[”的语句不能正常实现,而把特殊字符用“[ ]”括起便可正常查询。据此我们写出以下函数:
function sqlencode(str)
str=replace(str,"[","[[]") '此句一定要在最前
str=replace(str,"_","[_]")
str=replace(str,"%","[%]")
sqlencode=str
end function
在查询前将待查字符串先经该函数处理即可。
正则表达式查询
1. 字符 ‘
^
' 查询以特定字符或字符串开头的记录
|
1
|
SELECT * FROM user WHERE email REGEXP '^a'
|
字符 ‘^' 匹配以特定字符或字符串开头的记录,以上语句查询邮箱以 a 开头的记录
2. 字符 ' 查询以特定字符或字符串结尾的记录
|
1
|
SELECT * FROM user WHERE phone REGEXP '0$'
|
字符 ‘
$
' 匹配以特定字符或字符串结尾的记录,以上语句查询邮箱以 0 结尾的记录
3. 用符号“
.
”;来代替字符串中的任意一个字符
|
1
|
SELECT * FROM user WHERE email REGEXP 'a.c'
|
查询邮箱 a、c 之间有一个字符的记录,'.' 相当于是一个占位符。如果写成 REGEXP ‘a..c' , 即a、c之间有两个点,则表示邮箱中 a、c 之间要有两个字符。
4.使用“
*
”匹配多个字符
|
1
|
SELECT * FROM user WHERE email REGEXP 'm*'
|
查询所有邮箱中有 m 的记录。
|
1
|
SELECT * FROM user WHERE email REGEXP '^am*'
|
查询邮箱字母 a开头, a后面有字母 m 的记录。其中'*' 表示0次或以上。
5. 用字符“
+
”表示紧跟的字符
|
1
|
SELECT * FROM user WHERE email REGEXP 'm+'
|
查询所有邮箱中有 m 的记录。
|
1
|
SELECT * FROM user WHERE email REGEXP '^am+'
|
查询邮箱字母 a开头, a后面紧跟字母 m 的记录。其中'+' 表示紧跟字符。
6. “
|
” 分隔条件匹配指定字符串
|
1
|
SELECT * FROM user WHERE email REGEXP 'qq.com|163.com'
|
正则表达式可以匹配指定的字符串,字符串之间使用 “|” 分隔。
7. “
[]
” 表示集合匹配指定字符串中的任意一个
|
1
|
SELECT * FROM user WHERE email REGEXP '[az]'
|
”[]“ 指定一个集合,以上表示查询邮箱中带有 a或z或两者都有的邮箱。也可以用来匹配数字集合,比如 [0-9] 表示集合区间所有数字,[a-z] 表示集合区间所有字母。
8. “
[^]
”匹配指定字符以外的字符
|
1
|
SELECT * FROM user WHERE email REGEXP '[^a-d1-3]'
|
如上匹配邮箱中不包含 a、b、c、d 且 不包含 1、2、3 的记录。
9. 使用
{n,}
或
{n,m}
来指定字符串连接出现的次数
|
1
|
SELECT * FROM user WHERE email REGEXP 'b{2}'
|
表示字母 b 至少出现 2 次。
|
1
|
SELECT * FROM user WHERE email REGEXP 'yu{1,3}'
|
表示字符串 ba 至少出现1次,至多出现3次。
查询用户名:user(),system_user(),session_user()
索引
Mysql各种索引区别:
普通索引:最基本的索引,没有任何限制
唯一索引:与"普通索引"类似,不同的就是:索引列的值必须唯一,但允许有空值。
主键索引:它 是一种特殊的唯一索引,不允许有空值。
全文索引:仅可用于 MyISAM 表,针对较大的数据,生成全文索引很耗时好空间。
组合索引:为了更多的提高mysql效率可建立组合索引,遵循”最左前缀“原则。创建复合索引时应该将最常用(频率)作限制条件的列放在最左边,依次递减。
组合索引最左字段用in是可以用到索引的,最好explain一下select。
创建索引
(1)在创建数据表的时候创建索引
create table table_name(
属性名 数据类型[约束条件],
属性名 数据类型[约束条件],
属性名 数据类型[约束条件],
……
属性名 属性类型
[UNIQUE|FULLTEXT|SPATIAL] INDEX }KEY
[别名](属性名1 [长度])[asc|desc])
);
使用show create table语句可以查看完整表结构
例:创建score数据表并在该表的id字段上建立
普通索引
:
create table score(
id int(11) auto_increment primary key not null,
name varchar(50) not null,
math int(5) not null,
index(id)
);
例:创建address数据表,并在该表的id字段上建立
唯一索引
:
create table address(
id int(11) auto_increment primary key not null,
name varchar(50) not null,
math int(5) not null,
unique index address(id asc)
);
例:创建cards数据表,并在该表的info字段上建立
全文索引(全文索引的创建只能作用在char varchar text类型的字段上,创建全文索引需要使用fulltext 参数进行约束)
:
create table cards(
id int(11) auto_increment primary key not null,
name varchar(50) not null,
math int(5) not null,
number bigint(11),
info varchar(50),
fulltext key cards_info(info)
)engine=MyISAM;
例:创建telephone数据表,并在该表的tel字段上建立
单列索引
:
create table telephone(
id int(11) auto_increment primary key not null,
name varchar(50) not null,
tel varchar(50) not null,
index tel_num(tel(20))
);
数据字段长度为50,而创建的索引字段长度为20,这样做的目的是为了提高查询效率而优化查询速度。
例:创建information数据表,并在该表的name,sex字段上建立
多列索引
:
create table information(
id int(11) auto_increment primary key not null,
name varchar(50) not null,
sex vachar(5) not null,
birthday varchar(50) not null,
index info(name,sex)
);
注意使用在多列索引中只有查询条件使用了这些字段中的第一个字段(即上面实例中的name字段)时,索引才会被使用
例:创建list数据表,并在该表创建名为listinfo的
空间索引
:
create table list(
id int(11) auto_increment primary key not null,
goods geometry not null,
spatial index listinfo(goods)
)engine=MyISAM;
goods字段上已经建立名称为listinfo的空间索引,其中,goods字段必须不能为空,且数据类型是geometry。该类型是空间数据类型。空间类型不能用其他类型代替,否则生成空间索引时或产生错误且不能正常创建该类型索引。
在已建立的数据表中创建索引
create [unique|fulltext|spatial] index index_name
on table_name(属性[(length)])[asc|desc]
);
index_name:索引名称
table_name:表名
创建
普通索引
:create index stu_info on studentinfo(sid);
创建
唯一索引
:create unique index index1_id on index1(cid);
创建
全文索引
:create fulltext index 索引名 on 数据表名(字段名称);
创建
单列索引
:create index 索引名 on 数据表名(字段名称(长度));
创建
多列索引
:create index 索引名 on 数据表名(字段名称1,字段名称2);
创建
空间索引
:create spatial index 索引名 on 数据表名(字段名称);
其中,spatial用来设置索引为空间索引。用户要操作的数据表类型必须为MyISAM类型。并且字段名称必须存在非空约束。
修改已经存在在数据表上的索引结构添加索引
alter table table_name add [unique|fulltext|spatial] index index_name(属性名[(length)])[asc|desc]);
删除索引:drop index index_name on table_name;
事务(只支持数据表为InnoDB和BDB类型)
一般来说,事务是必须满足4个条件(ACID)::原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
- 原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
- 隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
- 持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
事务(只支持数据表为InnoDB和BDB类型)
创建一个类型为
InnoDB或BDB
类型的数据表:create table table_name(field_defintions)type=
InnoDB|BDB
;
当已经存在的表进行事务支持
:alter table table_name type=InnoDB|BDB;
命令行操作以后数据表就可以支持事务处理了,但这种操作可能会导致数据库中的数据丢失,因此为了避免非预期结果出现,在使用该命令之前,用户需要常见一个表备份。
初始化事务
:start transaction;
应用select 语句来查看数据是否被录用
提交事务
:commit;
撤销事务(事务回滚)
:rollback;
自动提交
:set autocommit=1;
关闭自动提交
:set autocommit=0;
对数据表使用表锁 加锁
:lock tables table_name lock_type,…… 类型有读、写。
以读方式锁定数据表
:lock table table_name read;
自己和别人都能能查看数据表数据,但都不能往里面写(添加 删除 更新)
以写方式锁定数据表
:lock table table_name write;
自己能查看和修改其他人无权限查看,只有在释放锁之后能查看数据表数据
。
去锁
:unlock tables;
数据备份:
备份一个数据库
:mysqldump -u username -p dbname table1 table2 …… >BackupName.sql
dbname为数据库名 table1table2 为数据表名 BackupName前面可以加一个绝对路径
例:root用户备份test数据库下的student表 : mysqldump -u root -p test student >D:\student.sql
备份多个数据库
:mysqldump -u username -p --databases dbname1 dbname2 …… >BackupName.sq
备份所有数据库
:mysqldump -u username -p --all --databases >BackupName.sql
数据恢复:mysql -u root -p [dbname]