redis(十二):redis缓存的置换算法、过期策略、缓存击穿等问题
1.缓存更新策略
(1)LRU:最近最久未被使用的页面置换出去(LinkedHashMap就是对LRU的实现)
下面借用了图来说明LRU的整个页面置换过程:https://blog.csdn.net/u013700358/article/details/85873397
如图是按照70120304的顺序加入栈中的数据。
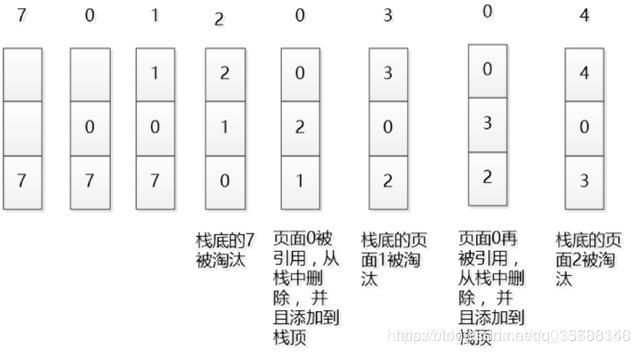
(2)LFU:最近最少使用的页面置换出去
(3)FIFO:最先进入的页面有限置换出去
我们在redis的实际开发过程中通常是使用设计过期时间和LRU结合的策略淘汰数据,设置过期时间可以保证数据在不需要的时候不在占用内存,LRU可以作为兜底,防止内存溢出。
补充:
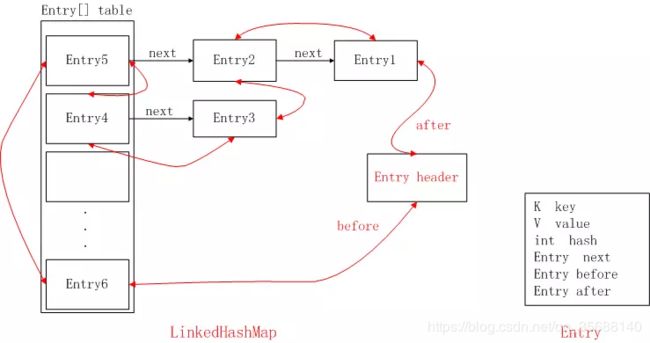
LinkedHashMap实际上是维持了排序(用双向链表)的HashMap,LinkedHashMap复用了HashMap的put方法。对get方法做出了修改。下面是红色的是LinkedHashMap维持的一个有序双向列表。get数据的时候
图片借用至https://www.jianshu.com/p/8f4f58b4b8ab
关于put,LinkedHashMap最后会调用HashMap的put方法,因为里面newNode在LinkedHashMap中被重写了。
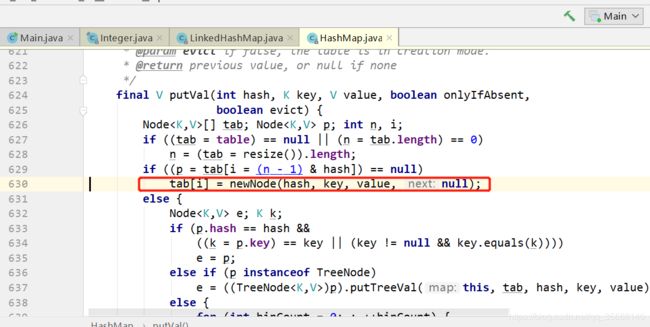
LinkedHashMap最后会用linkNodeLast方法将新加入的节点放到链表的最后。
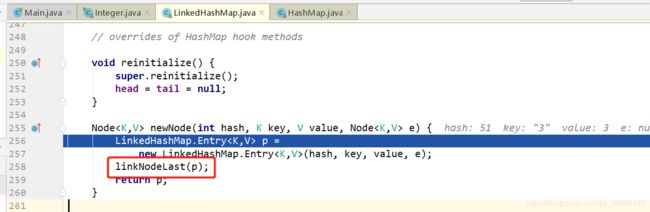
关于get:下面是LinkedHashMap的get方法
accessOrder是一个属性,表明LinkedHashMap按照访问顺序迭代,false表示按照插入顺序迭代。
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
2.内存的六种淘汰策略
1.noeviction :默认淘汰策略,不淘汰,如果内存已满,添加数据是报错。//eviction逐出
2.allkeys-lru:在所有键中,选取最近最少使用的数据抛弃。
3.volatile-lru:在设置了过期时间的所有键中,选取最近最少使用的数据抛弃。//Least Recently Used
4.allkeys-random: 在所有键中,随机抛弃。
5.volatile-random: 在设置了过期时间的所有键,随机抛弃。//volatile不稳定,易变的
6.volatile-ttl:在设置了过期时间的所有键,抛弃存活时间最短的数据。//time to live 生存时间
3.过期策略
1.定期删除:redis会把设置了过期时间的key放在单独的字典中,每隔一段时间执行一次删除(在redis.conf配置文件设置hz,1s刷新的频率)过期key的操作。
特性:每次占用较多CPU来处理需要删除额的数据,对CPU不太友好。
具体使用:
(1)从过期字典中随机 20 个 key;
(2)删除这 20 个 key 中已经过期的 key;
(3)如果过期的 key 比率超过 1/4,那就重复步骤 1;
2.惰性删除:过期的key并不一定会马上删除,还会占用着内存。 当你真正查询这个key时,redis会检查一下,这个设置了过期时间的key是否过期了? 如果过期了就会删除,返回空。这就是惰性删除。
特性:有些数据如果一直不被使用会一直占用内存,就算已经超时,对内存有一定的影响。
3.定时删除:在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除。
特性:每个key需要维持一个单独的定时器,而且可能存在一次性删除key较多,对CPU不友好的状况。好少有人使用该策略。
redis最常用的是惰性删除+定期删除,定期删除可以保证内存的可用性,惰性删除为定期删除兜底。
4.缓存击穿
(1)缓存空对象:可以解决访问很多mysql中的对象为空的问题,如果大量访问的数据在数据库中为空,为了减少数据库的这种空对象的压力,可以在访问一次以后将结果写入redis。
比如在100班中查询分数期间,某黑客视图恶意攻击学校数据库,使用无用的学号去查询,加入redis中并没有缓存这种key,那么他直接去数据库拿数据,数据库压力很大。为此,可以在redis中保存这种返回值为空的学号,如果下次还是这个学号,那么redis接可以直接告诉它没有学分,减小数据库的压力。
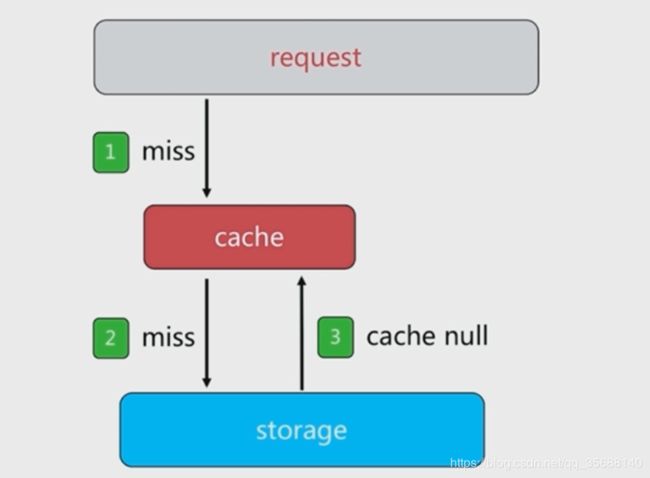
伪码逻辑:

(2)布隆过滤器
在redis上设置一个布隆过滤器,标记某个数据是存在于mysql中,如果不存在就必须要访问数据库。
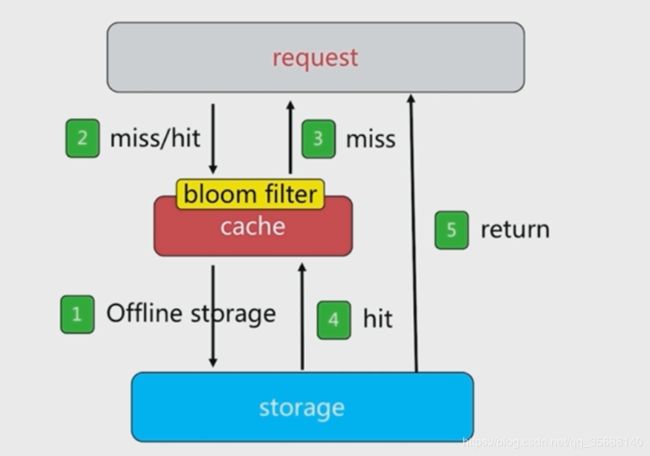
5.无底洞问题
redis节点增加,redis的性能下降。
主要原因:节点增加,mget需要访问的节点和io次数变多(mget命令需要遍历所有的节点)。
优化:
(1)减少keys等慢查询的命令的使用。
(2)mget使用pipeline减少网络io。(或者使用比较极端的hash_tag).
pipeline和hash_tag相关:https://blog.csdn.net/qq_35688140/article/details/101562861
6.缓存的热点key的重建
key的重建:我们通常使用缓存都是查询redis中是否有某个keyA,如果有没有就访问数据,然后构建
这里有一个问题,如果keyA是一个热点数据,那么可能在高并发下,多个线程都在重建keyA。重构的时间可能很长。如下图:
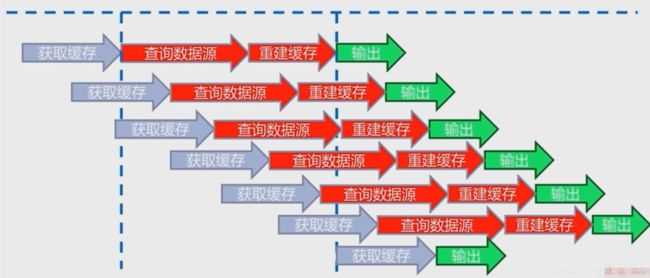
为了避免反复的重建缓存keyA提出下面两种方案:
(1)互斥锁:只有一个线程可以构建keyA,其他线程都被阻塞。构建完成以后,其他线程都可以直接获得该数据无需再重建keyA了。
缺点:在构建key的过程中,可能查询该数据的操作无法进行。
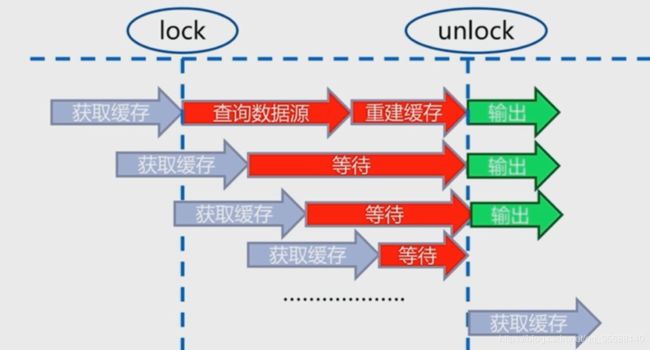
伪码:

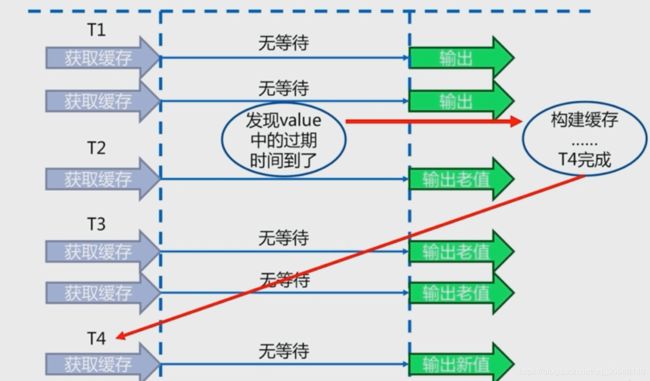
(2)永不过期:(对互斥锁的一个优化)redis中key不设置过期时间,而是给它一个逻辑过期时间。T2时间,如果发现keyA发生了变化需要重建,那就在逻辑过期时间上标记为过期,并fork一个新的线程去重建,在重建期间(T3),T3会不断尝试去获取缓存无需等待,但是获取的是老的数据,直到T4时间,缓存重建成功,再去获取数据就是最新的数据了。

7.缓存雪崩
原文链接:https://blog.csdn.net/a745233700/article/details/88088669
缓存雪崩:即缓存在同一时刻大面积的失效,比如你的缓存服务宕机了,会有大量的请求进来直接打到DB上,结果就是DB撑不住,挂掉。
①事前:使用集群缓存,保证缓存服务的高可用:
这种方案就是在发生雪崩前对缓存集群实现高可用,如果是使用 Redis,可以使用 主从+哨兵 ,Redis Cluster 来避免 Redis 全盘崩溃的情况。、
②事中:ehcache本地缓存 + Hystrix限流&降级,避免MySQL被打死:
使用 ehcache 本地缓存的目的也是考虑在 Redis Cluster 完全不可用的时候,ehcache 本地缓存还能够支撑一阵。
使用 Hystrix进行限流 & 降级 ,比如一秒来了5000个请求,我们可以设置假设只能有一秒 2000个请求能通过这个组件,那么其他剩余的 3000 请求就会走限流逻辑。
然后去调用我们自己开发的降级组件(降级),比如设置的一些默认值呀之类的。以此来保护最后的 MySQL 不会被大量的请求给打死。
③事后:开启Redis持久化机制,尽快恢复缓存集群:
一旦重启,就能从磁盘上自动加载数据恢复内存中的数据。