DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(一)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(一)
目录
THE NEURAL NETWORK ZOO
perceptrons
RBF
RNN
LSTM
GRU
BiRNN, BiLSTM and BiGRU
相关文章
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(一)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(二)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(三)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(四)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(五)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(六)
THE NEURAL NETWORK ZOO
POSTED ON SEPTEMBER 14, 2016 BY FJODOR VAN VEEN
With new neural network architectures popping up every now and then, it’s hard to keep track of them all. Knowing all the abbreviations being thrown around (DCIGN, BiLSTM, DCGAN, anyone?) can be a bit overwhelming at first.
随着新神经网络体系结构的不断涌现,很难对它们进行跟踪。知道所有的缩写(DCIGN, BiLSTM, DCGAN,还有其它更多的一些?)一开始可能有点压倒性。
So I decided to compose a cheat sheet containing many of those architectures. Most of these are neural networks, some are completely different beasts. Though all of these architectures are presented as novel and unique, when I drew the node structures… their underlying relations started to make more sense.
因此,我决定编写一个包含许多这样的体系结构的备忘单。其中大部分是神经网络,有些则是完全不同的beasts。虽然所有这些架构都是新颖独特的,但当我绘制节点结构时……它们的底层关系开始变得更有意义。
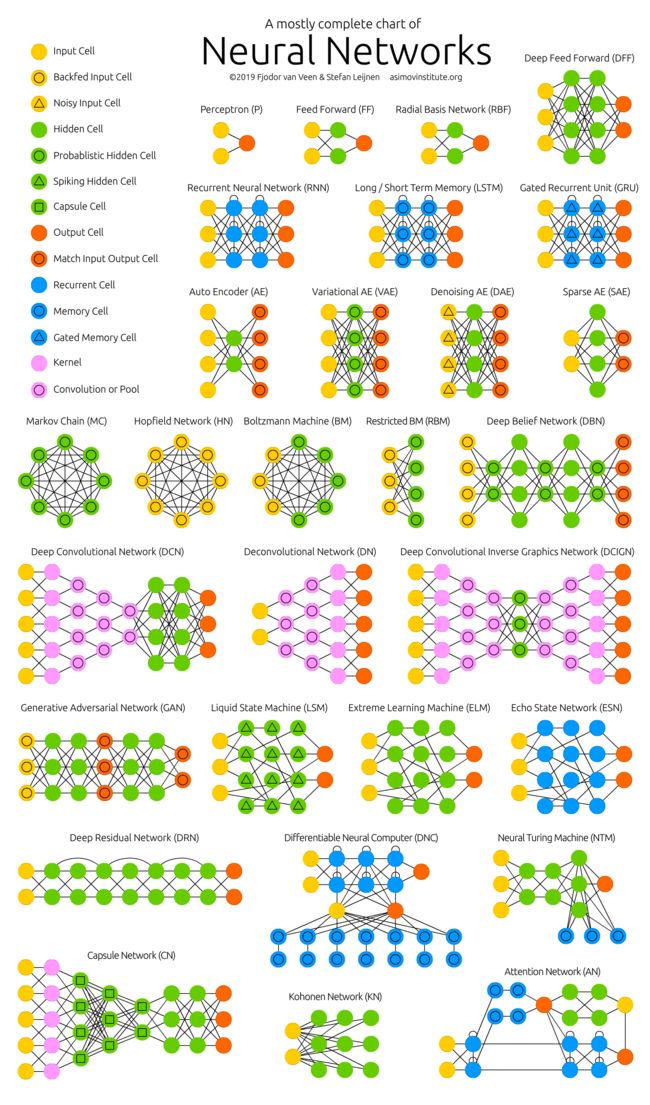
One problem with drawing them as node maps: it doesn’t really show how they’re used. For example, variational autoencoders (VAE) may look just like autoencoders (AE), but the training process is actually quite different. The use-cases for trained networks differ even more, because VAEs are generators, where you insert noise to get a new sample. AEs, simply map whatever they get as input to the closest training sample they “remember”. I should add that this overview is in no way clarifying how each of the different node types work internally (but that’s a topic for another day).
将它们绘制为节点映射有一个问题:它并没有真正显示如何使用它们。例如,变分自编码器(VAE)可能看起来就像自编码器(AE),但是训练过程实际上是非常不同的。经过训练的网络的用例差别甚至更大,因为VAEs是生成器,您可以在其中插入噪声以获得新的样本。AEs,简单地将他们得到的输入映射到他们“记得”的最近的训练样本。我应该补充一点,这个概述并没有阐明每种不同的节点类型如何在内部工作(但这是另一个主题)。
It should be noted that while most of the abbreviations used are generally accepted, not all of them are. RNNs sometimes refer to recursive neural networks, but most of the time they refer to recurrent neural networks. That’s not the end of it though, in many places you’ll find RNN used as placeholder for any recurrent architecture, including LSTMs, GRUs and even the bidirectional variants. AEs suffer from a similar problem from time to time, where VAEs and DAEs and the like are called simply AEs. Many abbreviations also vary in the amount of “N”s to add at the end, because you could call it a convolutional neural network but also simply a convolutional network (resulting in CNN or CN).
应该指出的是,虽然使用的大多数缩写词都被普遍接受,但并不是所有的缩写词都被接受。RNNs有时指recursive神经网络,但大多数时候指的是recurrent神经网络。不过,这还没完,在许多地方,您会发现RNN被用作任何循环体系结构的占位符,包括LSTMs、GRUs甚至双向变体。AEs有时会遇到类似的问题,其中VAEs和DAEs等被简单地称为AEs。许多缩写在结尾添加的“N”的数量也有所不同,因为您可以将其称为卷积神经网络,也可以简单地称为卷积网络(即CNN或CN)。
Composing a complete list is practically impossible, as new architectures are invented all the time. Even if published it can still be quite challenging to find them even if you’re looking for them, or sometimes you just overlook some. So while this list may provide you with some insights into the world of AI, please, by no means take this list for being comprehensive; especially if you read this post long after it was written.
组成一个完整的列表实际上是不可能的,因为新的体系结构一直在被发明。即使发表了,找到它们仍然是很有挑战性的,即使你正在寻找它们,或者有时你只是忽略了一些。因此,尽管这份清单可能会让你对人工智能的世界有一些了解,但请不要认为这份清单是全面的;特别是如果你在这篇文章写完很久之后才读它。
For each of the architectures depicted in the picture, I wrote a very, very brief description. You may find some of these to be useful if you’re quite familiar with some architectures, but you aren’t familiar with a particular one.
对于图中描述的每一个架构,我都写了一个非常非常简短的描述。如果您非常熟悉某些体系结构,您可能会发现其中一些非常有用,但是您不熟悉特定的体系结构。
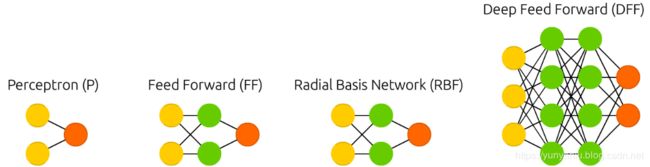

perceptrons
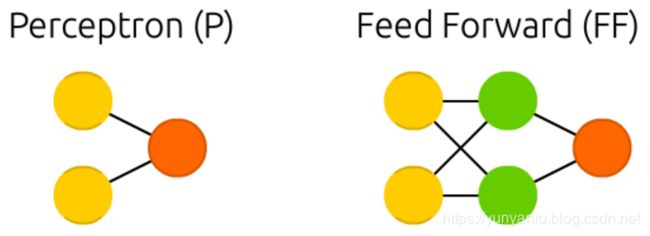
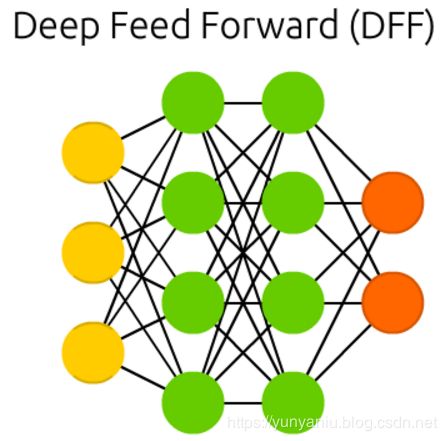
Feed forward neural networks (FF or FFNN) and perceptrons (P) are very straight forward, they feed information from the front to the back (input and output, respectively). Neural networks are often described as having layers, where each layer consists of either input, hidden or output cells in parallel. A layer alone never has connections and in general two adjacent layers are fully connected (every neuron form one layer to every neuron to another layer). The simplest somewhat practical network has two input cells and one output cell, which can be used to model logic gates. One usually trains FFNNs through back-propagation, giving the network paired datasets of “what goes in” and “what we want to have coming out”. This is called supervised learning, as opposed to unsupervised learning where we only give it input and let the network fill in the blanks. The error being back-propagated is often some variation of the difference between the input and the output (like MSE or just the linear difference). Given that the network has enough hidden neurons, it can theoretically always model the relationship between the input and output. Practically their use is a lot more limited but they are popularly combined with other networks to form new networks.
前馈神经网络(FF或FFNN)和感知器(P)是非常直接的,它们将信息从前面反馈到后面(分别是输入和输出)。神经网络通常被描述为具有多个层,其中每个层由并行的输入、隐藏或输出单元组成。单独的一层永远不会有连接,通常相邻的两层是完全连接的(每个神经元从一层到另一层)。
最简单而实用的网络有两个输入单元和一个输出单元,可以用它们来建模逻辑门。人们通常通过反向传播来训练FFNNs,给网络配对的数据集“输入什么”和“输出什么”。这叫做监督学习,而不是我们只给它输入,让网络来填补空白的非监督学习。
反向传播的错误通常是输入和输出之间的差异的一些变化(如MSE或只是线性差异)。假设网络有足够多的隐藏神经元,理论上它总是可以模拟输入和输出之间的关系。实际上,它们的使用非常有限,但是它们通常与其他网络结合在一起形成新的网络。
Rosenblatt, Frank. “The perceptron: a probabilistic model for information storage and organization in the brain.” Psychological review 65.6 (1958): 386.
Original Paper PDF
RBF
Radial basis function (RBF) networks are FFNNs with radial basis functions as activation functions. There’s nothing more to it. Doesn’t mean they don’t have their uses, but most FFNNs with other activation functions don’t get their own name. This mostly has to do with inventing them at the right time.
径向基函数网络是以径向基函数为激活函数的神经网络。没有别的了。这并不意味着它们没有自己的用途,但是大多数带有其他激活函数的FFNNs都没有自己的名称。这主要与在正确的时间发明它们有关。
Broomhead, David S., and David Lowe. Radial basis functions, multi-variable functional interpolation and adaptive networks. No. RSRE-MEMO-4148. ROYAL SIGNALS AND RADAR ESTABLISHMENT MALVERN (UNITED KINGDOM), 1988.
Original Paper PDF
RNN
Recurrent neural networks (RNN) are FFNNs with a time twist: they are not stateless; they have connections between passes, connections through time. Neurons are fed information not just from the previous layer but also from themselves from the previous pass. This means that the order in which you feed the input and train the network matters: feeding it “milk” and then “cookies” may yield different results compared to feeding it “cookies” and then “milk”. One big problem with RNNs is the vanishing (or exploding) gradient problem where, depending on the activation functions used, information rapidly gets lost over time, just like very deep FFNNs lose information in depth. Intuitively this wouldn’t be much of a problem because these are just weights and not neuron states, but the weights through time is actually where the information from the past is stored; if the weight reaches a value of 0 or 1 000 000, the previous state won’t be very informative. RNNs can in principle be used in many fields as most forms of data that don’t actually have a timeline (i.e. unlike sound or video) can be represented as a sequence. A picture or a string of text can be fed one pixel or character at a time, so the time dependent weights are used for what came before in the sequence, not actually from what happened x seconds before. In general, recurrent networks are a good choice for advancing or completing information, such as autocompletion.
递归神经网络(RNN)是具有时间扭曲的FFNNs:它们不是无状态的;它们之间有联系,时间上的联系。神经元不仅接受来自前一层的信息,还接受来自前一层的自身信息。这意味着输入和训练网络的顺序很重要:先给它“牛奶”,然后再给它“饼干”,与先给它“饼干”,然后再给它“牛奶”相比,可能会产生不同的结果。
RNNs的一个大问题是消失(或爆炸)梯度问题,根据使用的激活函数,随着时间的推移,信息迅速丢失,就像非常深的FFNNs在深度上丢失信息一样。直觉上这不会是个大问题因为这些只是权重而不是神经元的状态,但是时间的权重实际上是储存过去信息的地方;如果权重达到0或1,000 000,则前面的状态不会提供太多信息。
RNNs原则上可以在许多领域中使用,因为大多数没有时间轴的数据形式(与声音或视频不同)都可以表示为序列。一张图片或一串文本可以一次输入一个像素或字符,所以时间相关的权重用于序列中之前发生的内容,而不是x秒之前发生的内容。一般来说,递归网络是一个很好的选择,用于推进或完成信息,如自动完成。
Elman, Jeffrey L. “Finding structure in time.” Cognitive science 14.2 (1990): 179-211.
Original Paper PDF
LSTM

Long / short term memory (LSTM) networks try to combat the vanishing / exploding gradient problem by introducing gates and an explicitly defined memory cell. These are inspired mostly by circuitry, not so much biology. Each neuron has a memory cell and three gates: input, output and forget. The function of these gates is to safeguard the information by stopping or allowing the flow of it. The input gate determines how much of the information from the previous layer gets stored in the cell. The output layer takes the job on the other end and determines how much of the next layer gets to know about the state of this cell. The forget gate seems like an odd inclusion at first but sometimes it’s good to forget: if it’s learning a book and a new chapter begins, it may be necessary for the network to forget some characters from the previous chapter. LSTMs have been shown to be able to learn complex sequences, such as writing like Shakespeare or composing primitive music. Note that each of these gates has a weight to a cell in the previous neuron, so they typically require more resources to run.
长/短期内存(LSTM)网络试图通过引入门和显式定义的内存单元来解决渐变消失/爆炸的问题。这些灵感主要来自电路,而不是生物学。
每个神经元都有一个记忆细胞和三个门:输入、输出和遗忘。这些门的功能是通过阻止或允许信息流动来保护信息。输入门决定前一层的信息有多少存储在单元格中。输出层接受另一端的任务,并确定下一层对这个单元格的状态了解多少。“忘记门”一开始看起来很奇怪,但有时候忘记也是有好处的:如果你正在学习一本书,并且翻开了新的一章,那么网络可能有必要忘记前一章中的一些字符。
LSTMs已经被证明能够学习复杂的序列,比如像莎士比亚那样的写作或者创作原始音乐。注意,这些门中的每一个都对前一个神经元中的一个细胞有一个权重,因此它们通常需要更多的资源来运行。
Hochreiter, Sepp, and Jürgen Schmidhuber. “Long short-term memory.” Neural computation 9.8 (1997): 1735-1780.
Original Paper PDF
GRU
Gated recurrent units (GRU) are a slight variation on LSTMs. They have one less gate and are wired slightly differently: instead of an input, output and a forget gate, they have an update gate. This update gate determines both how much information to keep from the last state and how much information to let in from the previous layer. The reset gate functions much like the forget gate of an LSTM but it’s located slightly differently. They always send out their full state, they don’t have an output gate. In most cases, they function very similarly to LSTMs, with the biggest difference being that GRUs are slightly faster and easier to run (but also slightly less expressive). In practice these tend to cancel each other out, as you need a bigger network to regain some expressiveness which then in turn cancels out the performance benefits. In some cases where the extra expressiveness is not needed, GRUs can outperform LSTMs.
门控循环单位(GRU)是LSTM的一个微小变化。它们少了一个门,接线方式略有不同:它们没有输入、输出和忘记门,而是有一个更新门。这个更新门决定了与上一个状态保持多少信息,以及从上一层允许多少信息。
重置门的功能与LSTM的忘记门非常相似,但其位置略有不同。它们总是发送它们的完整状态,它们没有输出门。在大多数情况下,它们的功能与lstms非常相似,最大的区别在于grus的速度稍快,运行起来也更容易(但表达能力也稍差)。在实践中,它们往往会相互抵消,因为您需要一个更大的网络来重新获得一些表现力,而这反过来又会抵消性能优势。在一些不需要额外表现力的情况下,GRUS可以优于LSTM。
Chung, Junyoung, et al. “Empirical evaluation of gated recurrent neural networks on sequence modeling.” arXiv preprint arXiv:1412.3555 (2014).
Original Paper PDF
BiRNN, BiLSTM and BiGRU
Bidirectional recurrent neural networks, bidirectional long / short term memory networks and bidirectional gated recurrent units (BiRNN, BiLSTM and BiGRU respectively) are not shown on the chart because they look exactly the same as their unidirectional counterparts. The difference is that these networks are not just connected to the past, but also to the future. As an example, unidirectional LSTMs might be trained to predict the word “fish” by being fed the letters one by one, where the recurrent connections through time remember the last value. A BiLSTM would also be fed the next letter in the sequence on the backward pass, giving it access to future information. This trains the network to fill in gaps instead of advancing information, so instead of expanding an image on the edge, it could fill a hole in the middle of an image.
图中没有显示双向递归神经网络、双向长/短期记忆网络和双向门控递归单元(BiRNN、BiLSTM和BiGRU),因为它们看起来与单向递归单元完全相同。不同之处在于,这些网络不仅与过去相连,而且与未来相连。例如,单向LSTMs可以通过逐个输入字母来训练预测单词“fish”,其中通过时间的重复连接记住最后一个值。BiLSTM还将在向后传递时按顺序输入下一个字母,让它访问未来的信息。这就训练了网络来填补空白,而不是推进信息,因此它可以填补图像中间的一个洞,而不是在边缘扩展图像。
Schuster, Mike, and Kuldip K. Paliwal. “Bidirectional recurrent neural networks.” IEEE Transactions on Signal Processing 45.11 (1997): 2673-2681.
Original Paper PDF