DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(二)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(二)
目录
AE
VAE
DAE
SAE
相关文章
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(一)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(二)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(三)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(四)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(五)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(六)
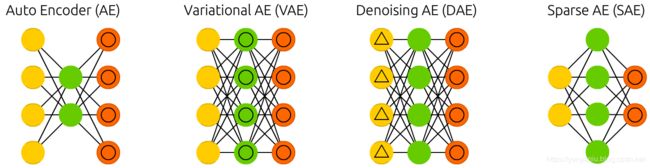
AE
Autoencoders (AE) are somewhat similar to FFNNs as AEs are more like a different use of FFNNs than a fundamentally different architecture. The basic idea behind autoencoders is to encode information (as in compress, not encrypt) automatically, hence the name. The entire network always resembles an hourglass like shape, with smaller hidden layers than the input and output layers. AEs are also always symmetrical around the middle layer(s) (one or two depending on an even or odd amount of layers). The smallest layer(s) is|are almost always in the middle, the place where the information is most compressed (the chokepoint of the network). Everything up to the middle is called the encoding part, everything after the middle the decoding and the middle (surprise) the code. One can train them using backpropagation by feeding input and setting the error to be the difference between the input and what came out. AEs can be built symmetrically when it comes to weights as well, so the encoding weights are the same as the decoding weights.
自动编码器(AE)有点类似于FFNNs,因为AEs更像是FFNNs的另一种用法,而不是一种根本不同的体系结构。自动编码器的基本思想是自动编码信息(如压缩,而不是加密),因此得名。整个网络总是像一个沙漏形状,隐藏层比输入层和输出层更小。AEs也总是围绕中间层对称(一层或两层取决于偶数层或奇数层)。最小的层是|,它几乎总是在中间,这是信息最压缩的地方(网络的阻塞点)。直到中间的所有内容都称为编码部分,中间之后的所有内容都称为解码和(令人惊讶的)中间代码。可以使用反向传播训练它们,方法是输入并将错误设置为输入和输出之间的差。当涉及到权值时,AEs也可以对称地构建,因此编码权值与解码权值相同。
Bourlard, Hervé, and Yves Kamp. “Auto-association by multilayer perceptrons and singular value decomposition.” Biological cybernetics 59.4-5 (1988): 291-294.
Original Paper PDF
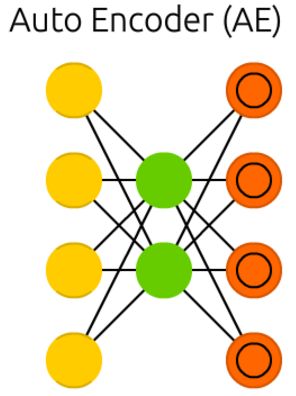
VAE
Variational autoencoders (VAE) have the same architecture as AEs but are “taught” something else: an approximated probability distribution of the input samples. It’s a bit back to the roots as they are bit more closely related to BMs and RBMs. They do however rely on Bayesian mathematics regarding probabilistic inference and independence, as well as a re-parametrisation trick to achieve this different representation. The inference and independence parts make sense intuitively, but they rely on somewhat complex mathematics. The basics come down to this: take influence into account. If one thing happens in one place and something else happens somewhere else, they are not necessarily related. If they are not related, then the error propagation should consider that. This is a useful approach because neural networks are large graphs (in a way), so it helps if you can rule out influence from some nodes to other nodes as you dive into deeper layers.
变分自编码器(VAE)具有与AEs相同的体系结构,但是“被教授”了其他一些东西:输入样本的近似概率分布。这有点回到根源,因为它们与BMs和RBMs的关系更密切。然而,他们确实依赖贝叶斯数学的概率推理和独立性,以及重新参数化的技巧来实现这种不同的表示。
推理和独立部分在直觉上是有意义的,但是它们依赖于一些复杂的数学。最基本的是:考虑影响力。如果一件事发生在一个地方,另一件事发生在另一个地方,它们不一定相关。如果它们不相关,那么错误传播应该考虑这一点。这是一种有用的方法,因为神经网络是大型图(在某种程度上),所以当您深入到更深的层次时,如果能够排除某些节点对其他节点的影响,这将会有所帮助。
Kingma, Diederik P., and Max Welling. “Auto-encoding variational bayes.” arXiv preprint arXiv:1312.6114 (2013).
Original Paper PDF
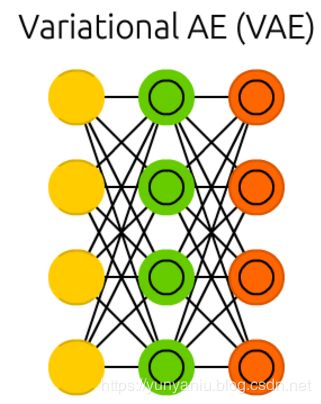
DAE
Denoising autoencoders (DAE) are AEs where we don’t feed just the input data, but we feed the input data with noise (like making an image more grainy). We compute the error the same way though, so the output of the network is compared to the original input without noise. This encourages the network not to learn details but broader features, as learning smaller features often turns out to be “wrong” due to it constantly changing with noise.
去噪自编码器(DAE)是一种AEs,我们不仅向输入数据提供数据,还向输入数据提供噪声(比如使图像更颗粒化)。我们用同样的方法计算误差,所以网络的输出与原始输入相比没有噪声。这鼓励网络不要学习细节,而是学习更广泛的特性,因为学习较小的特性往往是“错误的”,因为它会随着噪声不断变化。
Vincent, Pascal, et al. “Extracting and composing robust features with denoising autoencoders.” Proceedings of the 25th international conference on Machine learning. ACM, 2008.
Original Paper PDF
SAE
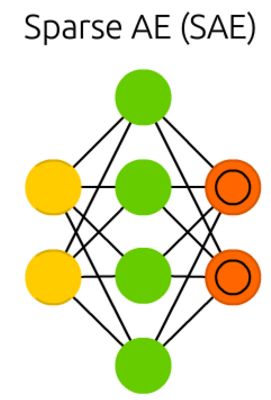
Sparse autoencoders (SAE) are in a way the opposite of AEs. Instead of teaching a network to represent a bunch of information in less “space” or nodes, we try to encode information in more space. So instead of the network converging in the middle and then expanding back to the input size, we blow up the middle. These types of networks can be used to extract many small features from a dataset. If one were to train a SAE the same way as an AE, you would in almost all cases end up with a pretty useless identity network (as in what comes in is what comes out, without any transformation or decomposition). To prevent this, instead of feeding back the input, we feed back the input plus a sparsity driver. This sparsity driver can take the form of a threshold filter, where only a certain error is passed back and trained, the other error will be “irrelevant” for that pass and set to zero. In a way this resembles spiking neural networks, where not all neurons fire all the time (and points are scored for biological plausibility).
稀疏自编码器(SAE)在某种程度上与AEs相反。我们不是教网络在更小的“空间”或节点中表示一堆信息,而是尝试在更大的空间中编码信息。所以我们不是把网络收敛到中间然后再扩展到输入大小,而是把中间放大。这些类型的网络可用于从数据集中提取许多小特性。如果用与AE相同的方法训练SAE,那么几乎在所有情况下,您都会得到一个非常无用的身份网络(就像输入就是输出一样,没有任何转换或分解)。为了防止这种情况发生,我们不是返回输入,而是返回输入加上一个稀疏驱动程序。这种稀疏驱动程序可以采用阈值筛选器的形式,在阈值筛选器中,只有一个特定的错误被传递回去并进行训练,而另一个错误将与该传递“无关”,并被设置为零。在某种程度上,这类似于尖峰状的神经网络,不是所有的神经元都一直处于兴奋状态(并根据生物学上的合理性打分)。
Marc’Aurelio Ranzato, Christopher Poultney, Sumit Chopra, and Yann LeCun. “Efficient learning of sparse representations with an energy-based model.” Proceedings of NIPS. 2007.
Original Paper PDF