DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(五)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(五)
目录
GAN
LSM
ELM
ESN
相关文章
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(一)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(二)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(三)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(四)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(五)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(六)

GAN
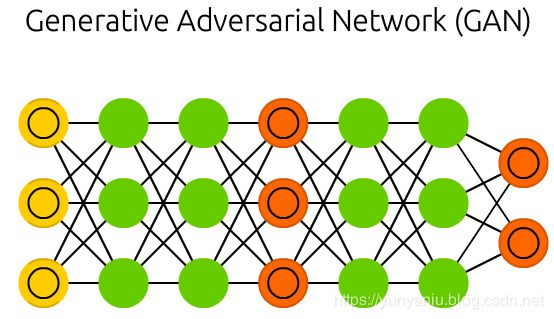
Generative adversarial networks (GAN) are from a different breed of networks, they are twins: two networks working together. GANs consist of any two networks (although often a combination of FFs and CNNs), with one tasked to generate content and the other has to judge content. The discriminating network receives either training data or generated content from the generative network. How well the discriminating network was able to correctly predict the data source is then used as part of the error for the generating network. This creates a form of competition where the discriminator is getting better at distinguishing real data from generated data and the generator is learning to become less predictable to the discriminator. This works well in part because even quite complex noise-like patterns are eventually predictable but generated content similar in features to the input data is harder to learn to distinguish. GANs can be quite difficult to train, as you don’t just have to train two networks (either of which can pose it’s own problems) but their dynamics need to be balanced as well. If prediction or generation becomes to good compared to the other, a GAN won’t converge as there is intrinsic divergence.
生成对抗网络(GAN)来自不同种类的网络,它们是双胞胎:两个网络一起工作。GANs由任意两个网络组成(尽管通常是ff和CNNs的组合),一个负责生成内容,另一个负责判断内容。识别网络从生成网络接收训练数据或生成内容。然后将判别网络对数据源的正确预测程度作为生成网络误差的一部分。这就形成了一种竞争形式,在这种竞争中,甄别者越来越善于区分真实数据和生成的数据,而生成者正在学习如何让甄别者变得更难以预测。这在一定程度上很有效,因为即使是非常复杂的类似于噪音的模式,最终也是可以预测的,但生成的内容在特性上与输入数据相似,这一点更难区分。
GANs可能很难训练,因为您不仅需要训练两个网络(其中任何一个都可能带来它自己的问题),而且还需要平衡它们的动态。如果预测或生成变得比另一个好,GAN将不会收敛,因为有内在的发散。
Goodfellow, Ian, et al. “Generative adversarial nets.” Advances in Neural Information Processing Systems (2014).
Original Paper PDF
LSM
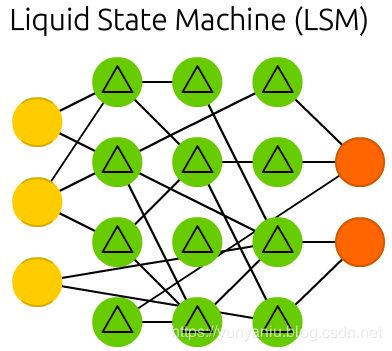
Liquid state machines (LSM) are similar soups, looking a lot like ESNs. The real difference is that LSMs are a type of spiking neural networks: sigmoid activations are replaced with threshold functions and each neuron is also an accumulating memory cell. So when updating a neuron, the value is not set to the sum of the neighbours, but rather added to itself. Once the threshold is reached, it releases its’ energy to other neurons. This creates a spiking like pattern, where nothing happens for a while until a threshold is suddenly reached.
液态机器(LSM)是类似的soups,看起来很像ESNs。真正的不同之处在于,LSMs是一种尖峰型神经网络:sigmoid激活被阈值函数取代,每个神经元也是一个累积的记忆细胞。因此,当更新一个神经元时,该值不会被设置为相邻神经元的和,而是被添加到它自己。一旦达到这个阈值,它就会向其他神经元释放能量。这就创建了一个类似于spiking的模式,在此模式中,一段时间内什么都没有发生,直到突然达到一个阈值。
Maass, Wolfgang, Thomas Natschläger, and Henry Markram. “Real-time computing without stable states: A new framework for neural computation based on perturbations.” Neural computation 14.11 (2002): 2531-2560.
Original Paper PDF
ELM
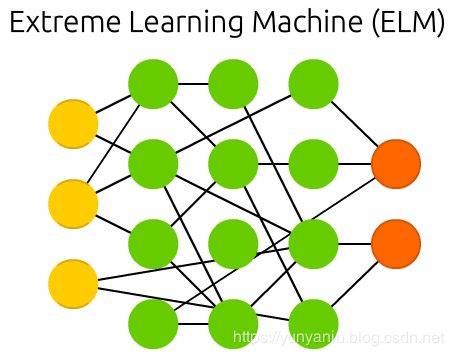
Extreme learning machines (ELM) are basically FFNNs but with random connections. They look very similar to LSMs and ESNs, but they are not recurrent nor spiking. They also do not use backpropagation. Instead, they start with random weights and train the weights in a single step according to the least-squares fit (lowest error across all functions). This results in a much less expressive network but it’s also much faster than backpropagation.
极限学习机(ELM)基本上是FFNNs,但具有随机连接。它们看起来非常类似于LSMs和ESNs,但它们既不复发也不尖峰。它们也不使用反向传播。相反,它们从随机权重开始,并根据最小二乘拟合(所有函数的最小误差)一步训练权重。这导致了一个更少的表达网络,但它也比反向传播快得多。
Huang, Guang-Bin, et al. “Extreme learning machine: Theory and applications.” Neurocomputing 70.1-3 (2006): 489-501.
Original Paper PDF
ESN
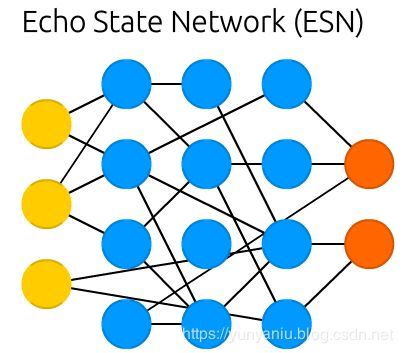
Echo state networks (ESN) are yet another different type of (recurrent) network. This one sets itself apart from others by having random connections between the neurons (i.e. not organised into neat sets of layers), and they are trained differently. Instead of feeding input and back-propagating the error, we feed the input, forward it and update the neurons for a while, and observe the output over time. The input and the output layers have a slightly unconventional role as the input layer is used to prime the network and the output layer acts as an observer of the activation patterns that unfold over time. During training, only the connections between the observer and the (soup of) hidden units are changed.
回声状态网络(ESN)是另一种不同类型的(循环)网络。这个神经元通过神经元之间的随机连接(即没有组织成整齐的一组层)将自己与其他神经元区分开来,而且它们的训练方式也不同。我们不再输入和反向传播错误,而是输入、转发和更新神经元一段时间,并随着时间观察输出。输入层和输出层有一个稍微非常规的角色,因为输入层用于启动网络,而输出层作为随时间展开的激活模式的观察者。在训练中,只有观察者和隐藏单位之间的连接被改变。
Jaeger, Herbert, and Harald Haas. “Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication.” science 304.5667 (2004): 78-80.
Original Paper PDF