DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(四)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(四)
目录
CNN
DN
DCIGN
相关文章
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(一)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(二)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(三)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(四)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(五)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(六)
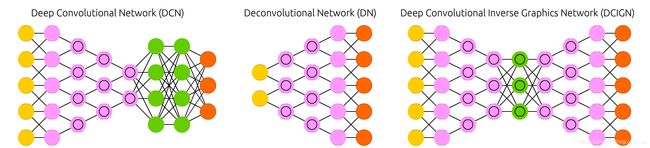
CNN

Convolutional neural networks (CNN or deep convolutional neural networks, DCNN) are quite different from most other networks. They are primarily used for image processing but can also be used for other types of input such as as audio. A typical use case for CNNs is where you feed the network images and the network classifies the data, e.g. it outputs “cat” if you give it a cat picture and “dog” when you give it a dog picture. CNNs tend to start with an input “scanner” which is not intended to parse all the training data at once. For example, to input an image of 200 x 200 pixels, you wouldn’t want a layer with 40 000 nodes. Rather, you create a scanning input layer of say 20 x 20 which you feed the first 20 x 20 pixels of the image (usually starting in the upper left corner). Once you passed that input (and possibly use it for training) you feed it the next 20 x 20 pixels: you move the scanner one pixel to the right. Note that one wouldn’t move the input 20 pixels (or whatever scanner width) over, you’re not dissecting the image into blocks of 20 x 20, but rather you’re crawling over it. This input data is then fed through convolutional layers instead of normal layers, where not all nodes are connected to all nodes. Each node only concerns itself with close neighbouring cells (how close depends on the implementation, but usually not more than a few). These convolutional layers also tend to shrink as they become deeper, mostly by easily divisible factors of the input (so 20 would probably go to a layer of 10 followed by a layer of 5). Powers of two are very commonly used here, as they can be divided cleanly and completely by definition: 32, 16, 8, 4, 2, 1. Besides these convolutional layers, they also often feature pooling layers. Pooling is a way to filter out details: a commonly found pooling technique is max pooling, where we take say 2 x 2 pixels and pass on the pixel with the most amount of red. To apply CNNs for audio, you basically feed the input audio waves and inch over the length of the clip, segment by segment. Real world implementations of CNNs often glue an FFNN to the end to further process the data, which allows for highly non-linear abstractions. These networks are called DCNNs but the names and abbreviations between these two are often used interchangeably.
卷积神经网络(CNN或深度卷积神经网络,DCNN)与大多数其他网络有很大的不同。它们主要用于图像处理,但也可以用于其他类型的输入,如音频。CNNs的一个典型用例是提供网络图像,然后网络对数据进行分类,例如,如果给它一张猫的图片,它就输出“cat”;如果给它一张狗的图片,它就输出“dog”。
CNNs倾向于从一个输入“扫描器”开始,它不打算一次解析所有的训练数据。例如,要输入一个200 x 200像素的图像,您不会想要一个有40000个节点的层。相反,您将创建一个扫描输入层,例如20 x 20,它将提供图像的前20 x 20像素(通常从左上角开始)。一旦您传递了该输入(并可能将其用于训练),您将为它提供下一个20x20像素:您将扫描仪向右移动一个像素。注意,不会将输入的20个像素(或任何扫描器宽度)移动过来,您不是将图像分割成20 x 20的块,而是在它上面爬行。然后,这些输入数据通过卷积层而不是普通层提供,在普通层中,并非所有节点都连接到所有节点。每个节点只关心自己与相邻的单元之间的关系(紧密程度取决于实现,但通常不会超过几个)。这些卷积层也倾向于收缩变得更深,主要由易于分割因素的输入(20可能去一层10其次是一层5)。两个很常用的权力,因为他们可以划分清晰,完全由定义:32,16,8、4、2、1。
除了这些卷积层,它们通常还具有池化层。池是一种过滤掉细节的方法:一种常见的池技术是max池,我们取2 x 2个像素,然后传递红色最多的像素。要将CNNs应用于音频,您基本上是将输入的音频波形和一英寸的长度逐段地输入到剪辑中。在现实世界中,CNNs的实现常常将FFNN绑定到数据的末尾,以进一步处理数据,这允许高度非线性的抽象。这些网络被称为DCNNs,但是这两个网络之间的名称和缩写通常可以互换使用。
LeCun, Yann, et al. “Gradient-based learning applied to document recognition.” Proceedings of the IEEE 86.11 (1998): 2278-2324.
Original Paper PDF
DN
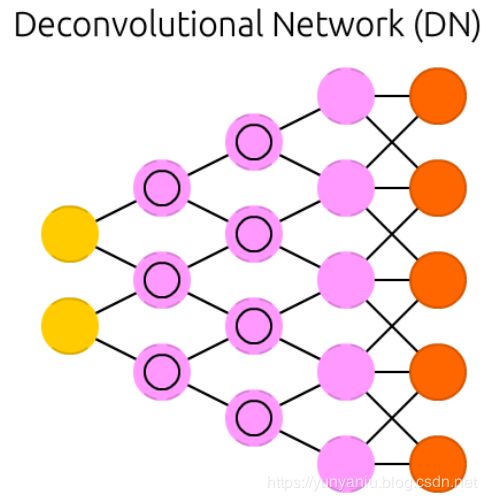
Deconvolutional networks (DN), also called inverse graphics networks (IGNs), are reversed convolutional neural networks. Imagine feeding a network the word “cat” and training it to produce cat-like pictures, by comparing what it generates to real pictures of cats. DNNs can be combined with FFNNs just like regular CNNs, but this is about the point where the line is drawn with coming up with new abbreviations. They may be referenced as deep deconvolutional neural networks, but you could argue that when you stick FFNNs to the back and the front of DNNs that you have yet another architecture which deserves a new name. Note that in most applications one wouldn’t actually feed text-like input to the network, more likely a binary classification input vector. Think <0, 1> being cat, <1, 0> being dog and <1, 1> being cat and dog. The pooling layers commonly found in CNNs are often replaced with similar inverse operations, mainly interpolation and extrapolation with biased assumptions (if a pooling layer uses max pooling, you can invent exclusively lower new data when reversing it).
反卷积神经网络(DN)又称逆图形网络(IGNS),是一种反向卷积神经网络。想象一下,给一个网络输入“猫”这个词,并通过将生成的图像与猫的真实图像进行比较,训练它生成类似猫的图像。就像普通的CNNs一样,DNNs也可以和FFNNs组合在一起,但这是关于如何使用新的缩写的问题。它们可能被称为深度反容量神经网络,但你可以争辩说,当你把FFNNs放在DNNs的后面和前面时,你得到了另一个值得重新命名的架构。
注意,在大多数应用程序中,实际上不会向网络提供类似文本的输入,更可能是二进制分类输入向量。想想< 0,1 >是猫,< 1,0 >是狗,< 1,1 >是猫和狗。CNNs中常见的池化层经常被类似的反操作替换,主要是使用有偏差的假设进行插值和外推(如果池化层使用最大池化,则可以在反转时只创建更低的新数据)。
Zeiler, Matthew D., et al. “Deconvolutional networks.” Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010.
Original Paper PDF
DCIGN
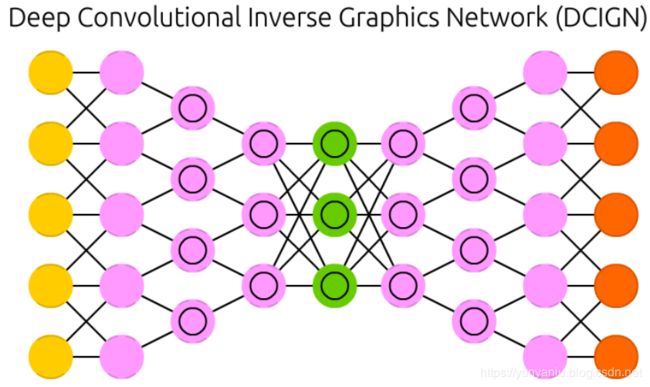
Deep convolutional inverse graphics networks (DCIGN) have a somewhat misleading name, as they are actually VAEs but with CNNs and DNNs for the respective encoders and decoders. These networks attempt to model “features” in the encoding as probabilities, so that it can learn to produce a picture with a cat and a dog together, having only ever seen one of the two in separate pictures. Similarly, you could feed it a picture of a cat with your neighbours’ annoying dog on it, and ask it to remove the dog, without ever having done such an operation. Demo’s have shown that these networks can also learn to model complex transformations on images, such as changing the source of light or the rotation of a 3D object. These networks tend to be trained with back-propagation.
深度卷积逆图形网络(DCIGN)有一个有点误导人的名字,因为它们实际上是VAEs,但是分别用于编码器和解码器的是CNNs和DNNs。这些网络试图将编码中的“特征”建模为概率,这样它就能学会在只在单独的图片中看到一只猫和一只狗的情况下,同时生成一张猫和狗的图片。
同样,你也可以给它喂一张猫的照片,上面有你邻居那只讨厌的狗,然后让它把狗移走,而不用做这样的手术。演示表明,这些网络还可以学习对图像进行复杂的转换建模,比如改变光源或3D对象的旋转。这些网络往往经过反向传播训练。
Kulkarni, Tejas D., et al. “Deep convolutional inverse graphics network.” Advances in Neural Information Processing Systems. 2015.
Original Paper PDF