DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(六)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(六)
目录
DRN
DNC
NTM
CN
KN
AN
相关文章
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(一)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(二)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(三)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(四)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(五)
DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(六)
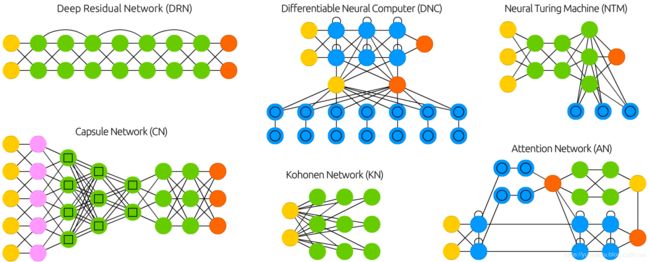
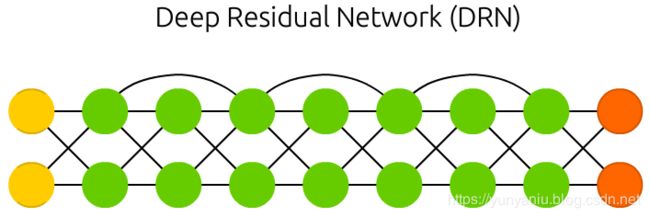
DRN
Deep residual networks (DRN) are very deep FFNNs with extra connections passing input from one layer to a later layer (often 2 to 5 layers) as well as the next layer. Instead of trying to find a solution for mapping some input to some output across say 5 layers, the network is enforced to learn to map some input to some output + some input. Basically, it adds an identity to the solution, carrying the older input over and serving it freshly to a later layer. It has been shown that these networks are very effective at learning patterns up to 150 layers deep, much more than the regular 2 to 5 layers one could expect to train. However, it has been proven that these networks are in essence just RNNs without the explicit time based construction and they’re often compared to LSTMs without gates.
深度残差网络(DRN)是非常深的FFNNs,有额外的连接将输入从一层传递到下一层(通常是2到5层)以及下一层。与其试图寻找一个跨5层将一些输入映射到一些输出的解决方案,不如强制网络学会将一些输入映射到一些输出+一些输入。基本上,它为解决方案添加了一个标识,将旧的输入传送到新层。
研究表明,这些网络在学习高达150层的模式方面非常有效,远远超过人们可以预期训练的常规2至5层。然而,已经证明,这些网络本质上只是没有显式的基于时间的构造的RNNs,它们经常被比作没有门的LSTMs。
He, Kaiming, et al. “Deep residual learning for image recognition.” arXiv preprint arXiv:1512.03385 (2015).
Original Paper PDF
DNC
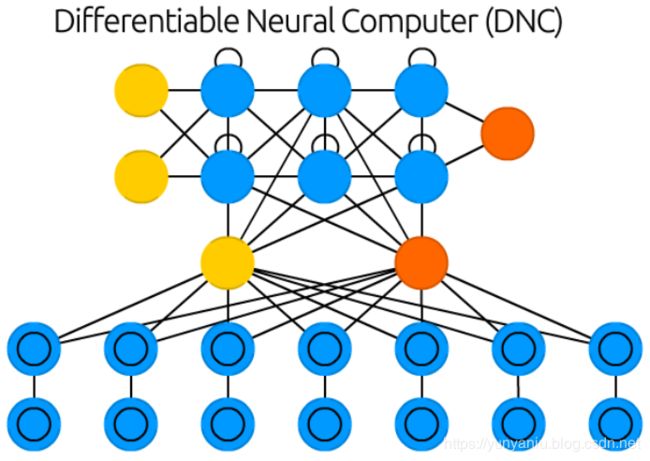
Differentiable Neural Computers (DNC) are enhanced Neural Turing Machines with scalable memory, inspired by how memories are stored by the human hippocampus. The idea is to take the classical Von Neumann computer architecture and replace the CPU with an RNN, which learns when and what to read from the RAM. Besides having a large bank of numbers as memory (which may be resized without retraining the RNN). The DNC also has three attention mechanisms. These mechanisms allow the RNN to query the similarity of a bit of input to the memory’s entries, the temporal relationship between any two entries in memory, and whether a memory entry was recently updated – which makes it less likely to be overwritten when there’s no empty memory available.
可微神经计算机(DNC)是一种增强的神经图灵机,具有可伸缩的内存,其灵感来自于人类海马区存储记忆的方式。其想法是采用经典的冯•诺依曼计算机架构,用RNN替换CPU, RNN可以学习何时以及从RAM中读取什么。除了拥有大量的数字作为内存(可以在不重新训练RNN的情况下调整大小)之外。DNC也有三个注意机制。这些机制允许RNN查询少量输入与内存条目的相似性、内存中任意两个条目之间的时间关系,以及最近是否更新了内存条目——这使得在没有可用的空内存时不太可能覆盖该条目。
Graves, Alex, et al. “Hybrid computing using a neural network with dynamic external memory.” Nature 538 (2016): 471-476.
Original Paper PDF
NTM
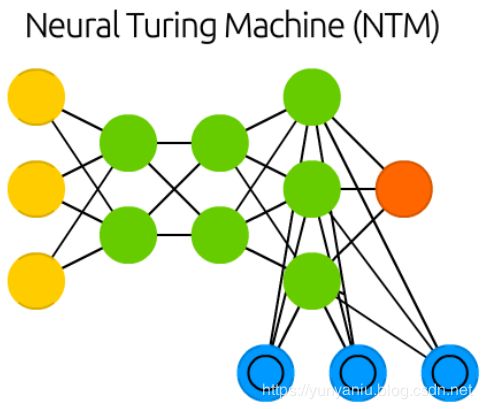
Neural Turing machines (NTM) can be understood as an abstraction of LSTMs and an attempt to un-black-box neural networks (and give us some insight in what is going on in there). Instead of coding a memory cell directly into a neuron, the memory is separated. It’s an attempt to combine the efficiency and permanency of regular digital storage and the efficiency and expressive power of neural networks. The idea is to have a content-addressable memory bank and a neural network that can read and write from it. The “Turing” in Neural Turing Machines comes from them being Turing complete: the ability to read and write and change state based on what it reads means it can represent anything a Universal Turing Machine can represent.
神经网络图灵机(NTM)可以被理解为LSTMs的抽象,是一种试图消除黑盒神经网络(并让我们对其中发生的事情有一些了解)的尝试。不是直接将记忆细胞编码成神经元,而是将记忆分开。它试图将常规数字存储的效率和持久性与神经网络的效率和表达能力结合起来。这个想法是要有一个内容可寻址的存储库和一个可以从中读写的神经网络。神经图灵机器中的“图灵”来自于它们的图灵完备性:根据它所读取的内容读写和改变状态的能力意味着它可以表示任何通用图灵机器能够表示的东西。
Graves, Alex, Greg Wayne, and Ivo Danihelka. “Neural turing machines.” arXiv preprint arXiv:1410.5401 (2014).
Original Paper PDF
CN
Capsule Networks (CapsNet) are biology inspired alternatives to pooling, where neurons are connected with multiple weights (a vector) instead of just one weight (a scalar). This allows neurons to transfer more information than simply which feature was detected, such as where a feature is in the picture or what colour and orientation it has. The learning process involves a local form of Hebbian learning that values correct predictions of output in the next layer.
胶囊网络(CapsNet)是受生物学启发的池的替代品,其中神经元连接多个权重(向量),而不是一个权重(标量)。这使得神经元能够传递更多的信息,而不仅仅是检测到哪些特征,比如某个特征在图片中的什么位置,或者它的颜色和方向。学习过程包括一种局部形式的Hebbian学习,它重视对下一层输出的正确预测。
Sabour, Sara, Frosst, Nicholas, and Hinton, G. E. “Dynamic Routing Between Capsules.” In Advances in neural information processing systems (2017): 3856-3866.
Original Paper PDF
KN
Kohonen networks (KN, also self organising (feature) map, SOM, SOFM) utilise competitive learning to classify data without supervision. Input is presented to the network, after which the network assesses which of its neurons most closely match that input. These neurons are then adjusted to match the input even better, dragging along their neighbours in the process. How much the neighbours are moved depends on the distance of the neighbours to the best matching units.
Kohonen networks (KN,也是self - organizational (feature) map, SOM, SOFM)利用竞争性学习对数据进行分类,无需监督。输入被呈现给网络,然后网络评估哪个神经元与输入最匹配。然后,这些神经元被调整,以更好地匹配输入,在这个过程中拖拽它们的邻居。邻域的移动量取决于邻域到最佳匹配单元的距离。
Kohonen, Teuvo. “Self-organized formation of topologically correct feature maps.” Biological cybernetics 43.1 (1982): 59-69.
Original Paper PDF
AN
Attention networks (AN) can be considered a class of networks, which includes the Transformer architecture. They use an attention mechanism to combat information decay by separately storing previous network states and switching attention between the states. The hidden states of each iteration in the encoding layers are stored in memory cells. The decoding layers are connected to the encoding layers, but it also receives data from the memory cells filtered by an attention context. This filtering step adds context for the decoding layers stressing the importance of particular features. The attention network producing this context is trained using the error signal from the output of decoding layer. Moreover, the attention context can be visualized giving valuable insight into which input features correspond with what output features.
注意机制网络(AN)可以看作是一类网络,它包括转换器体系结构。他们使用一种注意机制,通过单独存储以前的网络状态和在状态之间切换注意来对抗信息衰减。编码层中每个迭代的隐藏状态存储在内存单元中。解码层连接到编码层,但它也接收由注意上下文过滤的记忆细胞的数据。此过滤步骤为解码层添加上下文,强调特定特性的重要性。利用解码层输出的错误信号对产生该上下文的注意网络进行训练。此外,注意上下文可以被可视化,从而提供有价值的见解,了解哪些输入特性对应于哪些输出特性。
Jaderberg, Max, et al. “Spatial Transformer Networks.” In Advances in neural information processing systems (2015): 2017-2025.
Original Paper PDF
Follow us on twitter for future updates and posts. We welcome comments and feedback, and thank you for reading!
[Update 22 April 2019] Included Capsule Networks, Differentiable Neural Computers and Attention Networks to the Neural Network Zoo; Support Vector Machines are removed; updated links to original articles. The previous version of this post can be found here .
【2019年4月22日更新】包括胶囊网络、可微神经计算机和神经网络动物园的注意力网络;删除支持向量机;更新到原始文章的链接。这篇文章的前一个版本可以在这里找到。