Java8新特性之Lambda表达式和函数式接口
Java8新特性之Lambda表达式和函数式接口
- 一. 函数式接口简介
- 1. 概念
- 2. 格式
- 3. @FunctionalInterface注解
- 二. Lambda表达式
- 1. 概念
- 2. 格式
- 3. 示例
- 三. 函数式编程
- 1. Lambda的延迟执行
- 2. 使用Lambda作为参数和返回值
- 四. 常用函数式接口
- 1. Supplier接口
- 2. Consumer接口
- 抽象方法:accept
- 默认方法:andThen
- 3. Predicate接口
- 抽象方法:test
- 默认方法:and
- 默认方法:or
- 默认方法:negate
- 4. Function接口
- 抽象方法:apply
- 默认方法:andThen
一. 函数式接口简介
1. 概念
函数式接口:有且仅有一个抽象方法的接口。
函数式接口,即适用于函数式编程场景的接口。而Java中的函数式编程体现就是Lambda表达式,所以函数式接口就是可以适用于Lambda表达式使用的接口。只有确保接口中有且仅有一个抽象方法,Java中的Lambda表达式才能顺利地进行推导。
Java中的Lambda表达式可以被当做是匿名内部类的“语法糖”。
(“语法糖”是指使用更加方便,但是原理不变的代码语法。例如在遍历集合时使用的for-each语法,其实底层的实现原理仍然是迭代器,这便是“语法糖”。)
2. 格式
修饰符 interface 接口名称 {
public abstract 返回值类型 方法名称(可选参数信息);
// 其他非抽象方法内容
}
抽象方法在接口当中抽象方法的 public abstract 是可以省略的,所以我们可以写成:
public interface MyFunctionalInterface {
void myMethod();
}
3. @FunctionalInterface注解
与 @Override 注解的作用类似,Java 8中专门为函数式接口引入了一个新的注解: @FunctionalInterface 。该注解可用于一个接口的定义上:
@FunctionalInterface
public interface MyFunctionalInterface {
void myMethod();
}
一旦使用该注解来定义接口,编译器将会强制检查该接口是否确实有且仅有一个抽象方法,否则将会报错。需要注意的是,即使不使用该注解,只要满足函数式接口的定义,这仍然是一个函数式接口,使用起来都一样。当然小编建议还是写着好,因为这样可以防止我们犯错。
二. Lambda表达式
1. 概念
Lambda表达式(也称为闭包)是Java 8中最大和最令人期待的语言改变。它允许我们将函数当成参数传递给某个方法,或者把代码本身当作数据处理:函数式开发者非常熟悉这些概念。
很多JVM平台上的语言(Groovy、Scala等)从诞生之日就支持Lambda表达式,但是Java开发者没有选择,只能使用匿名内部类代替Lambda表达式。
Lambda的设计耗费了很多时间和很大的社区力量,最终找到一种折中的实现方案,可以实现简洁而紧凑的语言结构。
2. 格式
(参数1,参数2...) -> {
//方法体
}
说明:
(参数1,参数2…)表示参数列表;
->表示连接符;
{}内部是方法体
1、如果形参列表为空,只需保留();
2、如果形参只有1个,()可以省略,只需要参数的名称即可;
3、如果执行语句只有1句,且无返回值,{}可以省略,若有返回值,则若想省去{},则必须同时省略return,且执行语句也保证只有1句;
4、形参列表的数据类型会自动推断;
5、lambda不会生成一个单独的内部类文件;
6、lambda表达式若访问了局部变量,则局部变量必须是final的,若是局部变量没有加final关键字,系统会自动添加,此后在修改该局部变量,会报错;
3. 示例
先看看无参无返回值的例子:
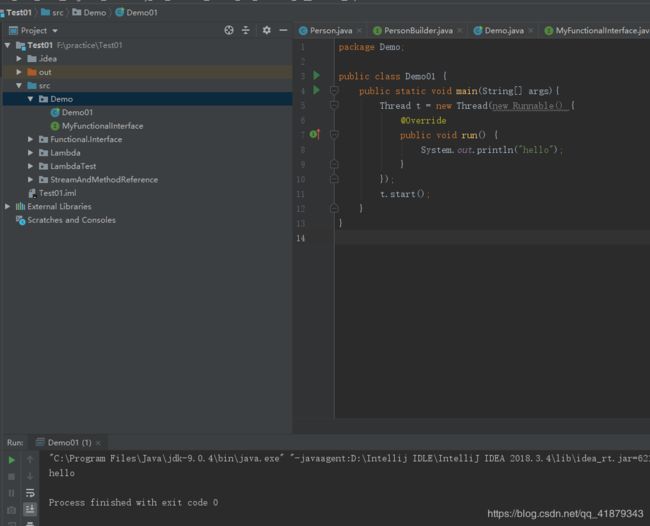
package Demo;
public class Demo01 {
public static void main(String[] args){
Thread t = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("hello");
}
});
t.start();
}
}
运行结果如下:
下面我们来看看怎么用Lambda表达式创建线程:
package Demo;
public class Demo01 {
public static void main(String[] args){
Thread t = new Thread(()->System.out.println("hello"));
t.start();
}
}
运行结果如下:

再看看有参无返回值的类型:
package Demo;
//先写一个带参函数式接口
@FunctionalInterface
public interface MyFunctionalInterface {
public void printName(String name);
}
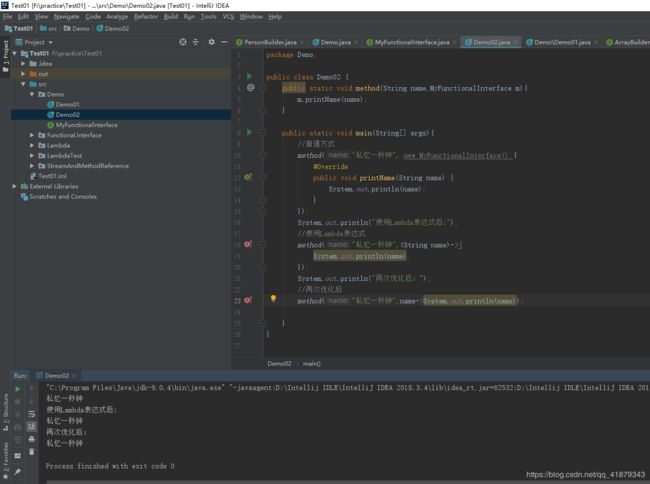
package Demo;
public class Demo02 {
public static void method(String name,MyFunctionalInterface m){
m.printName(name);
}
public static void main(String[] args){
//普通方式
method("私忆一秒钟", new MyFunctionalInterface() {
@Override
public void printName(String name) {
System.out.println(name);
}
});
System.out.println("使用Lambda表达式后:");
//使用Lambda表达式
method("私忆一秒钟",(String name)->{
System.out.println(name);
});
System.out.println("再次优化后:");
//再次优化后
method("私忆一秒钟",name->System.out.println(name));
}
}
运行结果如下:
最后我们看看有参有返回值的类型:
package Demo;
//先写一个带参有返回值的函数式接口
@FunctionalInterface
public interface MyFunctionalInterface01 {
public String printName(String name);
}
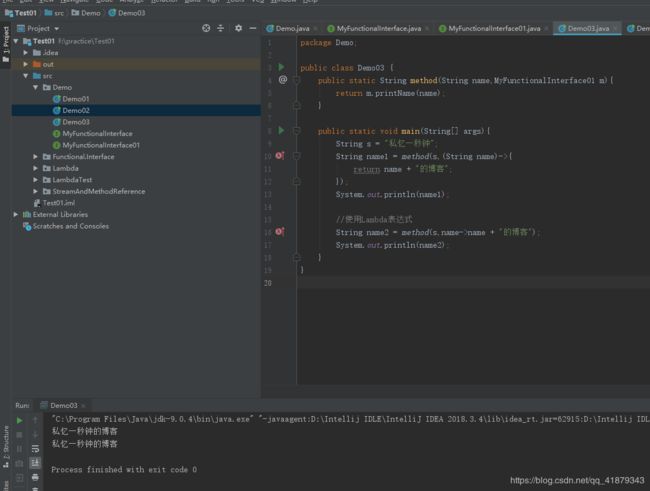
package Demo;
public class Demo03 {
public static String method(String name,MyFunctionalInterface01 m){
return m.printName(name);
}
public static void main(String[] args){
String s = "私忆一秒钟";
String name1 = method(s,(String name)->{
return name + "的博客";
});
System.out.println(name1);
//使用Lambda表达式
String name2 = method(s,name->name + "的博客");
System.out.println(name2);
}
}
运行结果如下:
三. 函数式编程
1. Lambda的延迟执行
有些场景的代码执行后,结果不一定会被使用,从而造成性能浪费。而Lambda表达式是延迟执行的,这正好可以
作为解决方案,提升性能。
首先我们看看日志性能浪费案例:
一种典型的场景就是对参数进行有条件使用,例如对日志消息进行拼接后,在满足条件的情况下进行打印输出:
public class Logger {
private static void log(int level, String msg) {
if (level == 1) {
System.out.println(msg);
}
}
public static void main(String[] args) {
String msgA = "Hello";
String msgB = "World";
String msgC = "Java";
log(1, msgA + msgB + msgC);
}
}
这段代码存在问题:无论级别是否满足要求,作为 log 方法的第二个参数,三个字符串一定会首先被拼接并传入方法内,然后才会进行级别判断。如果级别不符合要求,那么字符串的拼接操作就白做了,存在性能浪费。
备注:SLF4J是应用非常广泛的日志框架,它在记录日志时为了解决这种性能浪费的问题,并不推荐首先进行字符串的拼接,而是将字符串的若干部分作为可变参数传入方法中,仅在日志级别满足要求的情况下才会进行字符串拼接。例如: LOGGER.debug(“变量{}的取值为{}。”, “os”, “macOS”) ,其中的大括号 {} 为占位符。如果满足日志级别要求,则会将“os”和“macOS”两个字符串依次拼接到大括号的位置;否则不会进行字符串拼接。这也是一种可行解决方案,但Lambda可以做到更好。
下面我们来验证下Lambda表达式的延迟执行:
package Demo;
//先写个MessageBuilder函数式接口
@FunctionalInterface
public interface MessageBuilder {
public String builderMessage();
}
package Demo;
public class Demo04 {
public static void log(int level,MessageBuilder mb){
if(level == 1){
System.out.println(mb.builderMessage());
}
}
public static void main(String[] args){
String msg = "hello";
log(1,()->msg);
log(2,()->{
System.out.println("Lambda使用中");
return msg;
});
}
}
运行结果如下:

从结果中可以看出,在不符合级别要求的情况下,Lambda将不会执行。从而达到节省性能的效果。
扩展:实际上使用内部类也可以达到同样的效果,只是将代码操作延迟到了另外一个对象当中通过调用方法来完成。而是否调用其所在方法是在条件判断之后才执行的。
2. 使用Lambda作为参数和返回值
如果抛开实现原理不说,Java中的Lambda表达式可以被当作是匿名内部类的替代品。如果方法的参数是一个函数式接口类型,那么就可以使用Lambda表达式进行替代。使用Lambda表达式作为方法参数,其实就是使用函数式接口作为方法参数。
例如 java.lang.Runnable 接口就是一个函数式接口,假设有一个 startThread 方法使用该接口作为参数,那么就可以使Lambda进行传参。这种情况其实和 Thread 类的构造方法参数为 Runnable 没有本质区别。
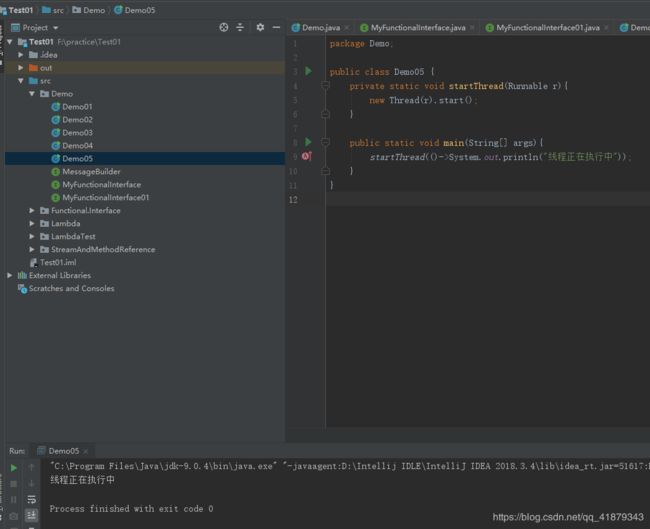
package Demo;
public class Demo05 {
private static void startThread(Runnable r){
new Thread(r).start();
}
public static void main(String[] args){
startThread(()->System.out.println("线程正在执行中"));
}
}
运行结果如下:
类似地,如果一个方法的返回值类型是一个函数式接口,那么就可以直接返回一个Lambda表达式。当需要通过一
个方法来获取一个 java.util.Comparator 接口类型的对象作为排序器时,就可以调该方法获取。
package Demo;
import java.util.Arrays;
import java.util.Comparator;
public class Demo06 {
private static Comparator<String> newComparator(){
return (a,b)->a.length()-b.length();
}
public static void main(String[] args){
String[] array = {"aaa","b","cc"};
System.out.println(Arrays.toString(array));
Arrays.sort(array,newComparator());
System.out.println(Arrays.toString(array));
}
}
其中直接return一个Lambda表达式即可。
四. 常用函数式接口
1. Supplier接口
java.util.function.Supplier 接口仅包含一个无参的方法: T get() 。用来获取一个泛型参数指定类型的对
象数据。由于这是一个函数式接口,这也就意味着对应的Lambda表达式需要“对外提供”一个符合泛型类型的对象
数据。
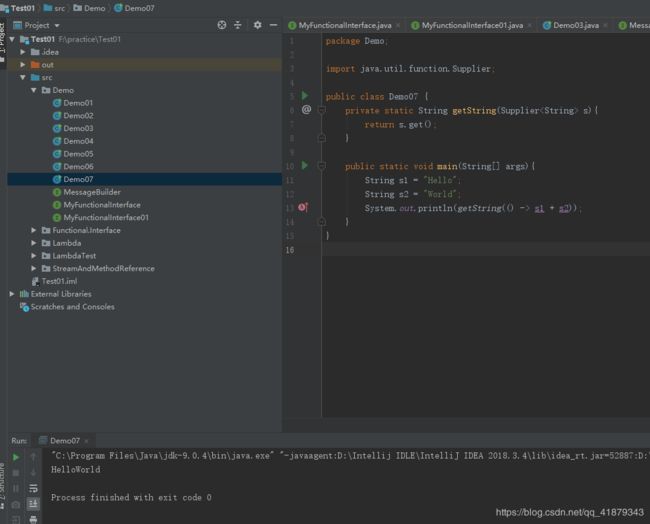
package Demo;
import java.util.function.Supplier;
public class Demo07 {
private static String getString(Supplier<String> s){
return s.get();
}
public static void main(String[] args){
String s1 = "Hello";
String s2 = "World";
System.out.println(getString(() -> s1 + s2));
}
}
运行结果如下:
2. Consumer接口
java.util.function.Consumer 接口则正好与Supplier接口相反,它不是生产一个数据,而是消费一个数据,
其数据类型由泛型决定。
抽象方法:accept
Consumer 接口中包含抽象方法 void accept(T t) ,意为消费一个指定泛型的数据。基本使用如:
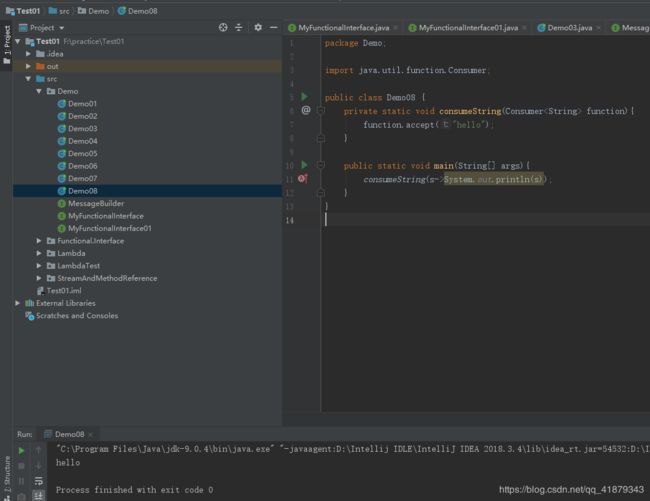
package Demo;
import java.util.function.Consumer;
public class Demo08 {
private static void consumeString(Consumer<String> function){
function.accept("hello");
}
public static void main(String[] args){
consumeString(s->System.out.println(s));
}
}
运行结果如下:
当然,更好的写法是使用方法引用,关于方法引用小编后面会更新出来的。
默认方法:andThen
如果一个方法的参数和返回值全都是 Consumer 类型,那么就可以实现效果:消费数据的时候,首先做一个操作,然后再做一个操作,实现组合。而这个方法就是 Consumer 接口中的default方法 andThen 。下面是JDK的源代码:
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) ‐> { accept(t); after.accept(t); };
}
备注: java.util.Objects 的 requireNonNull 静态方法将会在参数为null时主动抛出NullPointerException 异常。这省去了重复编写if语句和抛出空指针异常的麻烦。
要想实现组合,需要两个或多个Lambda表达式即可,而 andThen 的语义正是“一步接一步”操作。例如两个步骤组合的情况:
package Demo;
import java.util.function.Consumer;
public class Demo09 {
private static void consumeString(Consumer<String> one, Consumer<String> two){
one.andThen(two).accept("Hello");
}
public static void main(String[] args){
consumeString(
s->System.out.println(s.toUpperCase()),
s->System.out.println(s.toLowerCase())
);
}
}
运行结果如下:

运行结果将会首先打印完全大写的HELLO,然后打印完全小写的hello。当然,通过链式写法可以实现更多步骤的组合。
3. Predicate接口
运行结果将会首先打印完全大写的HELLO,然后打印完全小写的hello。当然,通过链式写法可以实现更多步骤的组合。
抽象方法:test
Predicate 接口中包含一个抽象方法: boolean test(T t) 。用于条件判断的场景:
package Demo;
import java.util.function.Predicate;
public class Demo10 {
private static void method(Predicate<String> p){
boolean veryLone = p.test("HelloWorld");
System.out.println("字符串很长吗?" + veryLone);
}
public static void main(String[] args){
method(s->s.length()>5);
}
}
条件判断的标准是传入的Lambda表达式逻辑,只要字符串长度大于5则认为很长。
默认方法:and
既然是条件判断,就会存在与、或、非三种常见的逻辑关系。其中将两个 Predicate 条件使用“与”逻辑连接起来实现“并且”的效果时,可以使用default方法 and 。其JDK源码为:
default Predicate<T> and(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) ‐> test(t) && other.test(t);
}
如果要判断一个字符串既要包含大写“H”,又要包含大写“W”,那么:
package Demo;
import java.util.function.Predicate;
public class Demo11 {
private static void method(Predicate<String> one,Predicate<String> two){
boolean isValid = one.and(two).test("HelloWorld");
System.out.println("字符串符合要求吗?" + isValid);
}
public static void main(String[] args){
method(
s->s.contains("H"),
s->s.contains("W")
);
method(
s->s.contains("h"),
s->s.contains("W")
);
}
}
运行结果如下:

默认方法:or
与 and 的“与”类似,默认方法 or 实现逻辑关系中的“或”。JDK源码为:
default Predicate<T> or(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) ‐> test(t) || other.test(t);
}
如果希望实现逻辑“字符串包含大写H或者包含大写W”,那么代码只需要将“and”修改为“or”名称即可,其他都不变:
package Demo;
import java.util.function.Predicate;
public class Demo12 {
private static void method(Predicate<String> one,Predicate<String> two){
boolean isValid = one.or(two).test("HelloWorld");
System.out.println("字符符合要求吗?" + isValid);
}
public static void main(String[] args){
method(
s->s.contains("H"),
s->s.contains("w")
);
method(
s->s.contains("h"),
s->s.contains("w")
);
}
}
运行结果如下:

默认方法:negate
“与”、“或”已经了解了,剩下的“非”(取反)也会简单。默认方法 negate 的JDK源代码为:
default Predicate<T> negate() {
return (t) ‐> !test(t);
}
从实现中很容易看出,它是执行了test方法之后,对结果boolean值进行“!”取反而已。一定要在 test 方法调用之前调用 negate 方法,正如 and 和 or 方法一样:
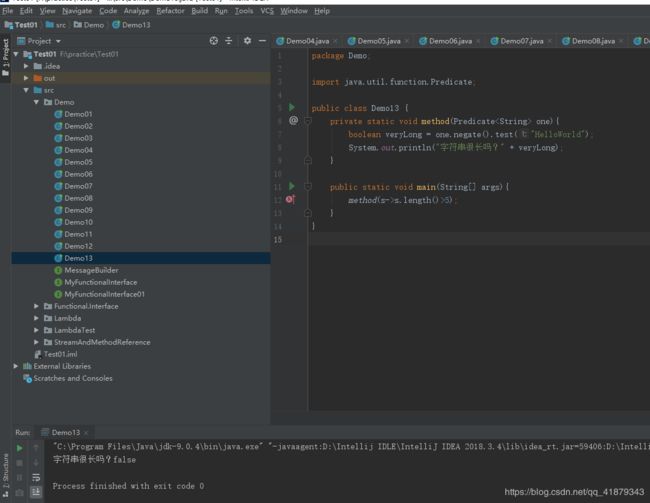
package Demo;
import java.util.function.Predicate;
public class Demo13 {
private static void method(Predicate<String> one){
boolean veryLong = one.negate().test("HelloWorld");
System.out.println("字符串很长吗?" + veryLong);
}
public static void main(String[] args){
method(s->s.length()>5);
}
}
运行结果如下:
4. Function接口
java.util.function.Function
抽象方法:apply
Function 接口中最主要的抽象方法为: R apply(T t) ,根据类型T的参数获取类型R的结果。使用的场景例如:将 String 类型转换为 Integer 类型。
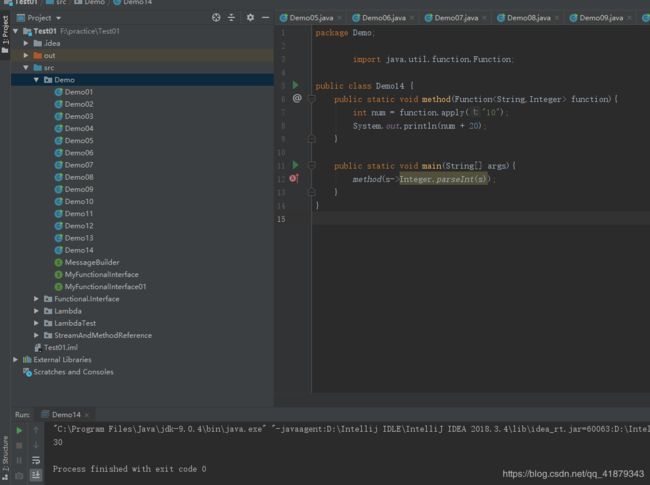
package Demo;
import java.util.function.Function;
public class Demo14 {
public static void method(Function<String,Integer> function){
int num = function.apply("10");
System.out.println(num + 20);
}
public static void main(String[] args){
method(s->Integer.parseInt(s));
}
}
运行结果如下:
默认方法:andThen
Function 接口中有一个默认的 andThen 方法,用来进行组合操作。JDK源代码如:
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t) ‐> after.apply(apply(t));
}
该方法同样用于“先做什么,再做什么”的场景,和 Consumer 中的 andThen 差不多:
package Demo;
import java.util.function.Function;
public class Demo15 {
private static void method(Function<String, Integer> one, Function<Integer, Integer> two){
int num = one.andThen(two).apply("10");
System.out.println(num + 20);
}
public static void main(String[] args){
method(
s->Integer.parseInt(s) + 10,
s->s *= 10
);
}
}
运行结果如下:
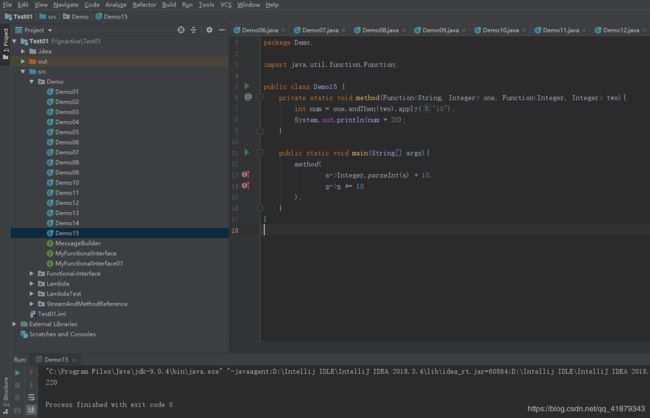
第一个操作是将字符串解析成为int数字,第二个操作是乘以10。两个操作通过 andThen 按照前后顺序组合到了一起。
请注意,Function的前置条件泛型和后置条件泛型可以相同。