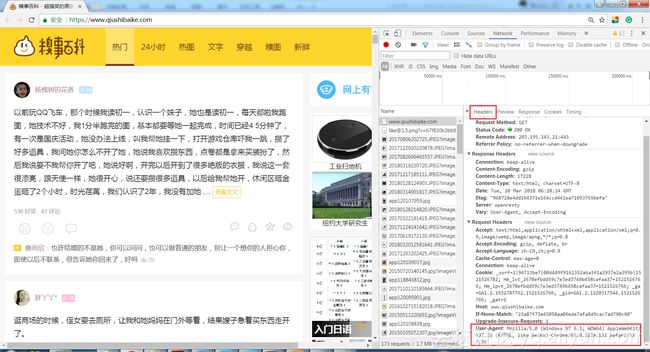

第三步,利用上面所提到的用户代理池进行爬取。首先建立用户代理池,从用户代理池中随机选择一项,设置UA。
import urllib.request
import re
import random
#用户代理池
uapools=[
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
]
def UA():
opener=urllib.request.build_opener()
thisua=random.choice(uapools)
ua=("User-Agent",thisua)
opener.addheaders=[ua]
urllib.request.install_opener(opener)
print("当前使用UA:"+str(thisua))
#for循环,爬取第1页到第36页的段子内容
for i in range(0,35):
UA()
#构造不同页码对应网址
thisurl="http://www.qiushibaike.com/8hr/page/"+str(i+1)+"/"
data=urllib.request.urlopen(thisurl).read().decode("utf-8","ignore")
#利用提取段子内容
pat='.*?(.*?).*?'
rst=re.compile(pat,re.S).findall(data)
for j in range(0,len(rst)):
print(rst[j])
print("-------")
还可以定时的爬取:
Import time
#然后在后面调用time.sleep()方法
换言之,学习爬虫需要灵活变通的思想,针对不同的情况,不同的约束而灵活运用。
三、抓包分析
抓包分析可以将网页中的访问细节信息取出。有时会发现直接爬网页时是无法获取到目标数据的,因为这些数据做了隐藏,此时可以使用抓包分析的手段进行分析,并获取隐藏数据。
1)Fiddler简介
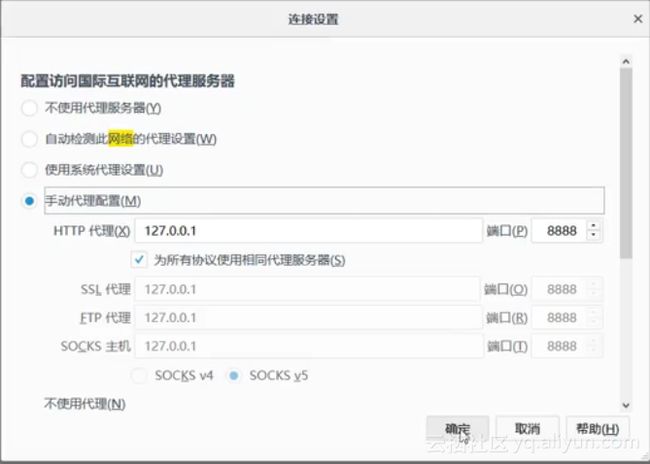
抓包分析可以直接使用浏览器F12进行,也可以使用一些抓包工具进行,这里推荐Fiddler。Fiddler下载安装。假设给Fiddler配合的是火狐浏览器,打开浏览器,如下图,找到连接设置,选择手动代理设置并确定。
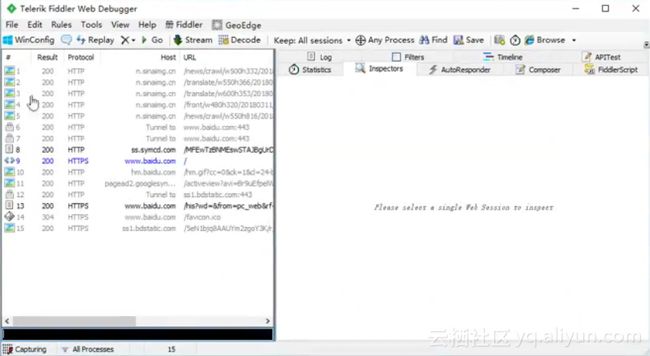
假设打开百度,如下图,加载的数据包信息就会在Fiddler中左侧列表中列出来,那么网站中隐藏相关的数据可以从加载的数据包中找到。
2)第二项练习-腾讯视频评论爬虫实战
目标网站:https://v.qq.com/
需要获取的数据:某部电影的评论数据,实现自动加载。
首先可以发现腾讯视频中某个视频的评论,在下面的图片中,如果点击”查看更多评论”,网页地址并无变化,与上面提到的糗事百科中的页码变化不同。而且通过查看源代码,只能看到部分评论。即评论信息是动态加载的,那么该如何爬取多页的评论数据信息?
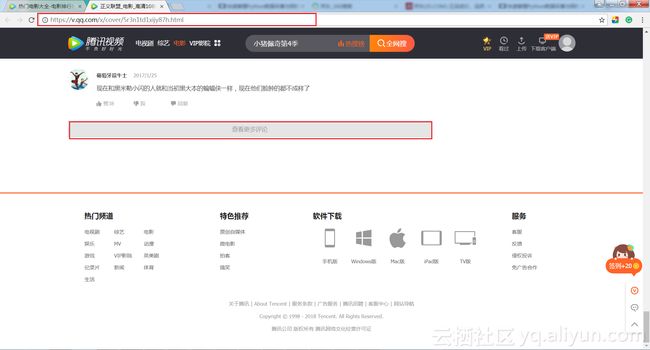
第一步,分析腾讯视频评论网址变化规律。点击”查看更多评论”,同时打开Fiddler,第一条信息的TextView中,TextView中可以看到对应的content内容是unicode编码,刚好对应的是某条评论的内容。
解码出来可以看到对应评论内容。

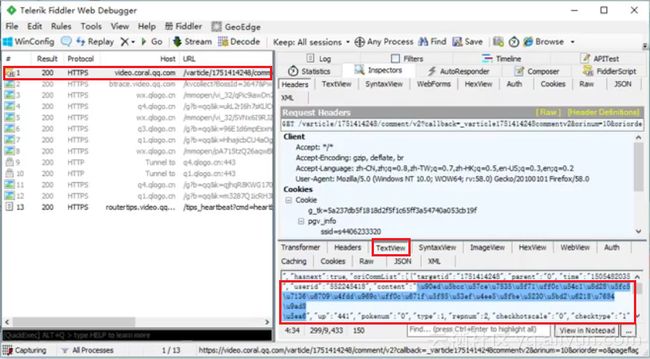
将第一条信息的网址复制出来进行分析,观察其中的规律。下图是两个紧连着的不同评论的url地址,如下图,可以发现只有cursor字段发生变化,只要得到cursor,那么评论的地址就可以轻松获得。如何找到cursor值?
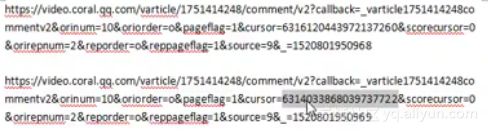
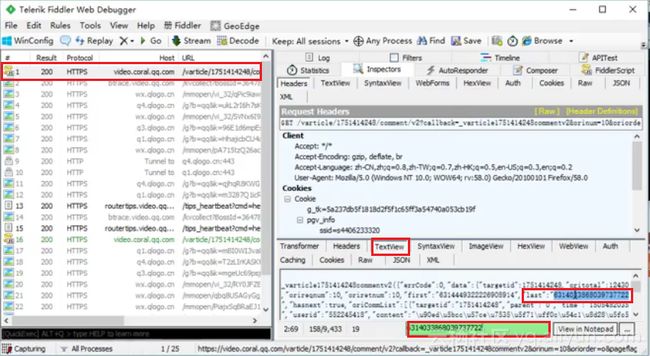
第二步,查找网址中变化的cursor字段值。从上面的第一条评论信息里寻找,发现恰好在last字段值与后一条评论的cursor值相同。即表示cursor的值是迭代方式生成的,每条评论的cursor信息在其上一条评论的数据包中寻找即可。
第三步,完整代码
a.腾讯视频评论爬虫:获取”深度解读”评论内容(单页评论爬虫)
#单页评论爬虫
import urllib.request
import re
#https://video.coral.qq.com/filmreviewr/c/upcomment/[视频id]?commentid=[评论id]&reqnum=[每次提取的评论的个数]
#视频id
vid="j6cgzhtkuonf6te"
#评论id
cid="6233603654052033588"
num="20"
#构造当前评论网址
url="https://video.coral.qq.com/filmreviewr/c/upcomment/"+vid+"?commentid="+cid+"&reqnum="+num
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Content-Type":"application/javascript",
}
opener=urllib.request.build_opener()
headall=[]
for key,value in headers.items():
item=(key,value)
headall.append(item)
opener.addheaders=headall
urllib.request.install_opener(opener)
#爬取当前评论页面
data=urllib.request.urlopen(url).read().decode("utf-8")
titlepat='"title":"(.*?)"'
commentpat='"content":"(.*?)"'
titleall=re.compile(titlepat,re.S).findall(data)
commentall=re.compile(commentpat,re.S).findall(data)
for i in range(0,len(titleall)):
try:
print("评论标题是:"+eval('u"'+titleall[i]+'"'))
print("评论内容是:"+eval('u"'+commentall[i]+'"'))
print("------")
except Exception as err:
print(err)
b.腾讯视频评论爬虫:获取”深度解读”评论内容(自动切换下一页评论的爬虫)
#自动切换下一页评论的爬虫
import urllib.request
import re
#https://video.coral.qq.com/filmreviewr/c/upcomment/[视频id]?commentid=[评论id]&reqnum=[每次提取的评论的个数]
vid="j6cgzhtkuonf6te"
cid="6233603654052033588"
num="3"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Content-Type":"application/javascript",
}
opener=urllib.request.build_opener()
headall=[]
for key,value in headers.items():
item=(key,value)
headall.append(item)
opener.addheaders=headall
urllib.request.install_opener(opener)
#for循环,多个页面切换
for j in range(0,100):
#爬取当前评论页面
print("第"+str(j)+"页")
#构造当前评论网址thisurl="https://video.coral.qq.com/filmreviewr/c/upcomment/"+vid+"?commentid="+cid+
"&reqnum="+num
data=urllib.request.urlopen(thisurl).read().decode("utf-8")
titlepat='"title":"(.*?)","abstract":"'
commentpat='"content":"(.*?)"'
titleall=re.compile(titlepat,re.S).findall(data)
commentall=re.compile(commentpat,re.S).findall(data)
lastpat='"last":"(.*?)"'
#获取last值,赋值给cid,进行评论id切换
cid=re.compile(lastpat,re.S).findall(data)[0]
for i in range(0,len(titleall)):
try:
print("评论标题是:"+eval('u"'+titleall[i]+'"'))
print("评论内容是:"+eval('u"'+commentall[i]+'"'))
print("------")
except Exception as err:
print(err)
四、挑战案例
1)第三项练习-中国裁判文书网爬虫实战
目标网站:http://wenshu.court.gov.cn/
需要获取的数据:2018年上海市的刑事案件接下来进入实战讲解。
第一步,观察换页之后的网页地址变化规律。打开中国裁判文书网2018年上海市刑事案件的第一页,在换页时,如下图中的地址,发现网址是完全不变的,这种情况就是属于隐藏,使用抓包分析进行爬取。
第二步,查找变化字段。从Fiddler中可以找到,获取某页的文书数据的地址:http://wenshu.court.gov.cn/List/ListContent
可以发现没有对应的网页变换,意味着中国裁判文书网换页是通过POST进行请求,对应的变化数据不显示在网址中。通过F12查看网页代码,再换页操作之后,如下图,查看ListContent,其中有几个字段需要了解:
Param:检索条件
Index:页码
Page:每页展示案件数量
...
>>>>阅读全文