hadoop的伪分布式安装
hadoop的伪分布式安装
HDFS上运行MapReduce 程序
我的hadoop的版本是2.9.2
hadoop-2.9.2 的下载地址
1. 下载后,解压到你设置好的目录
# 我的是在/opt/moudles/hadoop-2.9.2
2. 进入到配置文件所在目录
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ cd etc/hadoop/
3. 修改 etc/hadoop/hadoop-env.sh
# 配置JAVA_HOME
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2/etc/hadoop$ vi hadoop-env.sh
4. 然后在文件末尾添加
export JAVA_HOME=/opt/moudles/jdk1.8.0_121
其中/opt/moudles/jdk1.8.0_121 是我的JDK所在的路径,需要换成你的JDK所在的路径
5. 修改core-site.xml
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2/etc/hadoop$ vim core-site.xml
找到<configuration></configuration>(这句不要粘贴)
<configuration>
<!--namenode所在节点-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.144.109:9000</value>
<description>将上边192.168.144.109换成你的ip</description>
</property>
<!-- 指定hadoop运行时产生文件的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/moudles/hadoop-2.9.2/tmp</value>
<description>/opt/moudles/hadoop-2.9.2换成你的hadoop所在的路径</description>
</property>
</configuration>
6. 修改hadoop/hdfs-site.xml
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2/etc/hadoop$ vim hdfs-site.xml
找到<configuration></configuration>(这句不要粘贴)
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
7. 格式化namenode(第一次启动时格式化,以后就不要总格式化)
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ bin/hdfs namenode -format
注:如果你配置了HADOOP_HOME,可以用以下命令直接启动
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ hdfs namenode -format
注:如果你没有配置HADOOP_HOME
HADOOP_HOME配置连接
8. 启动namenode
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ sbin/hadoop-daemon.sh start namenode
注:如果你配置了HADOOP_HOME,可以用以下命令直接启动
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ hadoop-daemon.sh start namenode
9. 启动datanode
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ sbin/hadoop-daemon.sh start datanode
注:如果你配置了HADOOP_HOME,可以用以下命令直接启动
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ hadoop-daemon.sh start datanode
10. jps查看
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ jps
13192 DataNode
13097 NameNode
14622 Jps
若报以下错误
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ jps
The program 'jps' can be found in the following packages:
* openjdk-8-jdk-headless
* openjdk-9-jdk-headless
Try: sudo apt install <selected package>
到该普通用户家目录下进行Java环境配置
ubuntu@ubuntu01:~$ vi .profile
向文件末尾中增加
export JAVA_HOME=/opt/moudles/jdk1.8.0_121
export PATH= $ PATH:$JAVA_HOME/bin注 $ PATH之间没有空格
#其中opt/moudles/jdk1.8.0_121为你的jdk所在目录
生效该文件
ubuntu@ubuntu01:~$ source .profile
Java环境详细配置链接参看
jps查看
11. 在hdfs上进行文件测试-在hdfs文件系统上创建一个input文件夹
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ bin/hadoop fs -mkdir -p /user/xcu/mapreduce/wordcount/input
12. 在浏览器地址栏中输入
http://192.168.144.109:50070
将对应的ip换成你的
13.出现以下界面
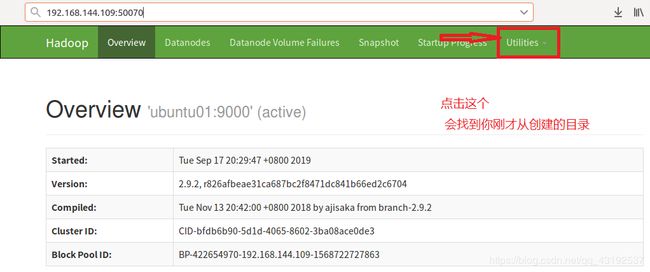
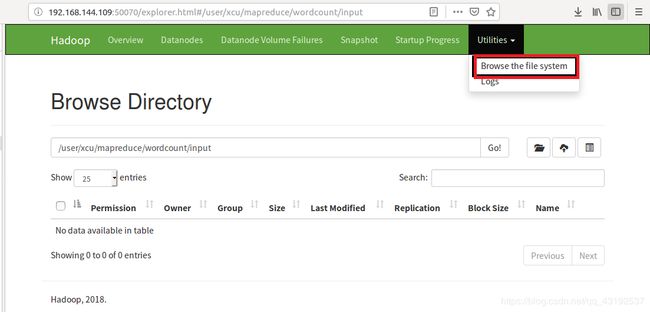
14. 若浏览器中不能出现上边的界面
重要的事说三遍
关闭防火墙
关闭防火墙
关闭防火墙
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ sudo ufw disable
15. 下面测试在Hdfs上运行mapreduce程序
- ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ mkdir wciput
- ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ vim wc.input
hadoop yarn
hadoop mapreduce
xcu
xcu
- 将测试文件内容上传到文件系统上
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ bin/hadoop fs -put /opt/moudles/hadoop-2.9.2/wciput/wc.input /user/xcu/mapreduce/wordcount/input/
注:执行这些命令时候,一定是在hadoop的安装目录下(若配置了hadoope的家目录,可以在任何地方执行这些命令)
- 可查看是否上传成功
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ bin/hadoop fs -cat /user/xcu/mapreduce/wordcount/input/wc.input
- 浏览器中也可以查看
- 开始执行在Hdfs上运行mapreduce程序
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /user/xcu/mapreduce/wordcount/input/ /user/xcu/mapreduce/wordcount/output
注:第二次运行时/user/xcu/mapreduce/wordcount/output中的output换个名称
注:/user/xcu/mapreduce/wordcount/output是文件产生目录
注:/user/xcu/mapreduce/wordcount/input存放的是要操作的文件的目录
注:jar wordcount 是执行命令
-
在浏览器中下载查看产生的文件
-
命令查看
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ bin/hadoop fs -cat /user/xcu/mapreduce/wordcount/output/*
- 进入到相应的目录下进行查看这些数据实际存放在哪里
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2/tmp/dfs/data/current/BP-422654970-192.168.144.109-1568722727863/current/finalized/subdir0/subdir0$
cat blk_1073741826
YARN上运行MapReduce 程序
1. 进入到配置文件所在目录
2. 配置yarn-env.sh
#文件末尾中添加
export JAVA_HOME=/opt/moudles/jdk1.8.0_121
3.配置yarn-site.xml
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
4.配置mapred-env.sh
#文件末尾中添加
export JAVA_HOME=/opt/moudles/jdk1.8.0_121
5.配置mapred-site.xml
<!-- 指定mapreduce运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
6.启动resourcemanager
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ sbin/yarn-daemon.sh start resourcemanager
7.启动nodemanager
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ sbin/yarn-daemon.sh start nodemanager
8.jps查看
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ jps
29889 Jps
29187 ResourceManager
13192 DataNode
13097 NameNode
29823 NodeManager
9.yarn-浏览器页面查看
http://192.168.144.109:8088
10.yarn-浏览器页面查看如图
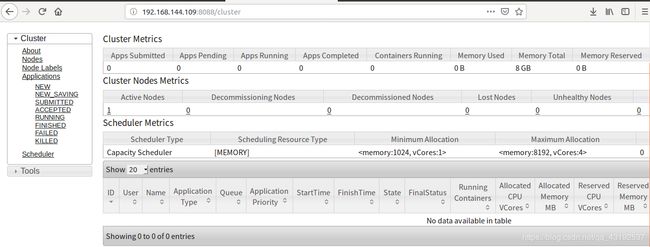
11.删除文件系统上的output文件
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ bin/hdfs dfs -rm -R /user/xcu/mapreduce/wordcount/output
11. 执行mapreduce程序
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /user/xcu/mapreduce/wordcount/input /user/xcu/mapreduce/wordcount/output
12. 查看运行结果
bin/hdfs dfs -cat /user/atguigu/mapreduce/wordcount/output/*
13. 用单个命令停止NodeManager ResourceManager DataNode NameNode
#可以用以上的命令
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ sbin/yarn-daemon.sh stop nodemanager
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ sbin/yarn-daemon.sh start resourcemanager
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ sbin/hadoop-daemon.sh start datanode
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ sbin/hadoop-daemon.sh start namenode
14. 用集成命令停止 启动NodeManager ResourceManager DataNode NameNode
#开启
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ sbin/start-dfs.sh
#关闭
ubuntu@ubuntu01:/opt/moudles/hadoop-2.9.2$ sbin/stop-dfs.sh